
Ich habe zu viele Dinge gesehen, die in der Krypto als „Infrastruktur“ bezeichnet werden. Jede Phase hat eine neue narrative Schicht, die vernünftiger und ordentlicher klingt und oft… sehr notwendig erscheint, aber wenn man genau hinsieht, lösen viele Dinge nur die Probleme, die diese Branche selbst geschaffen hat.
Indexing ist ein Beispiel dafür, und Verification ist es auch. Die beiden Konzepte mögen unterschiedlich erscheinen, stammen jedoch von einem gemeinsamen Punkt: Die Daten auf der Blockchain sind nicht so einfach zu nutzen, wie wir denken.
Das zugrunde liegende Problem hier ist nicht neu. Blockchain speichert Daten, ist aber nicht dafür ausgelegt, effizient abgefragt zu werden. Sie können Daten lesen, aber um sie zu verstehen, ist eine zusätzliche externe Verarbeitungsschicht erforderlich, und dort erscheinen die Indexierungssysteme. Sie helfen, rohe Daten in brauchbare Informationen zu übersetzen. Es klingt vernünftig und realistisch, und es ist fast zu einem Standardbestandteil im Stack vieler Anwendungen geworden.
Aber das ist auch der Ausgangspunkt eines anderen Problems. Wenn Sie einen Dritten benötigen, um die Daten neu zu organisieren, beginnen Sie, dem zu vertrauen, wie sie es organisieren. Sie lesen nicht mehr direkt von der Kette, sondern über eine verarbeitete, ausgewählte Schicht, und irgendwo wird das ursprüngliche „vertrauenslose“ Gefühl verwässert.
Mindestens aus der Sicht, die ich beobachtet habe, ist der Großteil der Benutzer nicht wirklich daran interessiert. Sie brauchen einfach schnelle Daten, stabile APIs und keine Fehler. Sie fragen nicht, ob diese Daten verändert wurden, sie überprüfen auch nicht. Das schafft einen ziemlich interessanten Graubereich: Wir bauen auf der Blockchain, um Vertrauen zu vermeiden, verlassen uns aber auf Zwischenhändler, denen wir... standardmäßig vertrauen.
Das ist der Teil, zu dem ich immer zurückkehre.
Indexierungssysteme, wie wir sie derzeit verwenden, scheinen ein UX-Problem zu lösen, eröffnen aber ein Problem hinsichtlich der Integrität. Nicht im Sinne von Betrug, sondern im Sinne von: Wir sind uns über die Daten nicht mehr absolut sicher, verhalten uns aber so, als ob alles in Ordnung wäre.
In diesem Kontext scheint es, dass einige Projekte in eine andere Richtung gehen. Sie versuchen nicht, die Daten leichter abfragbar zu machen, sondern wollen, dass die Daten klarer überprüfbar sind.
The Graph ist ein recht typisches Beispiel für den ersten Ansatz. Es verändert die Essenz der Daten nicht, sondern hilft Ihnen einfach, schneller auf diese Daten zuzugreifen, strukturierter. Es ist wie eine Dienstleistungsschicht, die auf der Blockchain liegt. Sie senden eine Abfrage, Sie erhalten ein Ergebnis. Einfach, effizient, und in der Realität wird es bereits häufig verwendet.
Aber The Graph beantwortet nicht wirklich die Frage: „Wie weiß ich, dass diese Daten korrekt sind?“ Es wird angenommen, dass das Indexierungssystem korrekt funktioniert oder zumindest ausreichend genau ist.
Auf der anderen Seite scheint SIGN zu versuchen, das Problem aus einer anderen Perspektive zu betrachten. Nicht Indexierung, sondern Verifizierung. Nicht Daten leichter lesbar zu machen, sondern die Überprüfung von Daten klarer zu gestalten. Nicht eine Abfrageebene, sondern eine Beweisebene.
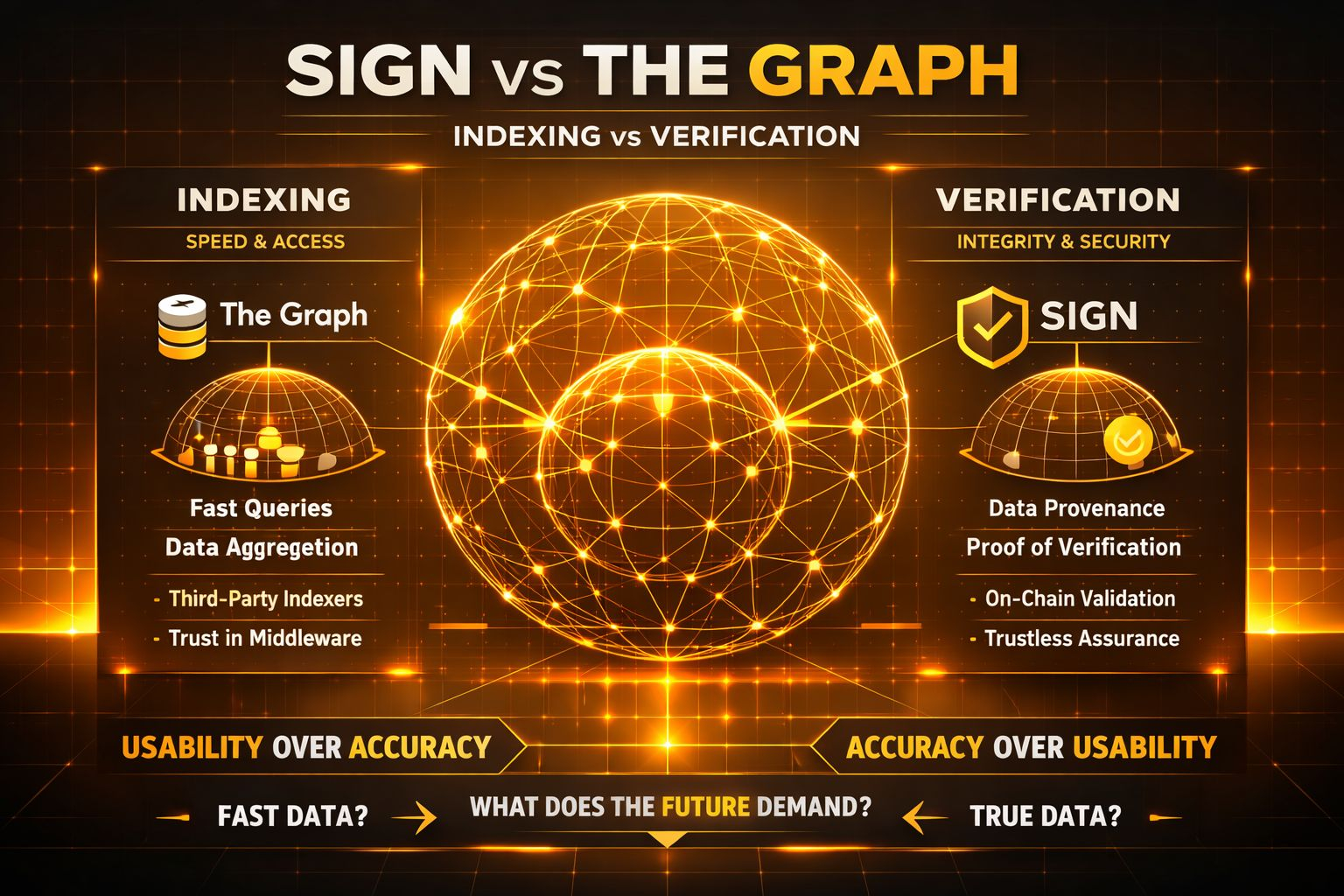
Dieser Unterschied mag klein erscheinen, ist aber ziemlich grundlegend. Eine Seite optimiert für Geschwindigkeit und Benutzererfahrung, die andere für Richtigkeit und Überprüfbarkeit. Eine Seite hilft Ihnen, Daten zu nutzen, während die andere versucht sicherzustellen, dass die Daten, die Sie verwenden, Dinge sind, denen Sie vertrauen können, ohne zu vertrauen.
Natürlich ist es einfach, das zu sagen, aber ob man es tatsächlich umsetzen kann, ist eine andere Geschichte.
Die Realität ist, dass die meisten aktuellen Anwendungen nicht so hohe Verifizierungsebenen erfordern oder zumindest noch nicht das Gefühl haben, dass dies notwendig ist. Wenn alles läuft, wenn die Benutzer nicht beschweren, kann das Hinzufügen einer Verifizierungsebene als übertrieben angesehen werden. Es macht das System komplizierter, langsamer und manchmal unnötig.
Aber das gilt nur, bis es nicht mehr gilt.
Wenn Fehler auftreten, wenn falsche Daten vorhanden sind, wenn ein System von diesen Daten abhängt und dadurch beeinträchtigt wird, wird die Frage der Verifizierung wichtig, aber dann ist es oft schon zu spät.
Es scheint, dass wir in einer Phase sind, in der die Indexierung gut genug ist, während die Verifizierung weiterhin ein „nice to have“ ist, aber ich bin mir nicht sicher, ob dies gleich bleibt, wenn das Ökosystem komplexer wird, wenn viele Systeme voneinander abhängen und eine kleine Abweichung sich ausbreiten kann.
SIGN setzt, zumindest aus meiner Sicht, auf dieses Szenario. Dass in Zukunft das „Wissen, woher die Daten stammen und ob sie korrekt sind“ genauso wichtig sein wird wie „wie schnell man Daten erhält“.
Aber das ist immer noch nur eine Annahme.
Whitepapers können sehr überzeugend sein, Narrative können sehr logisch sein, aber letztendlich kommt alles auf die Nutzung zurück. Braucht das wirklich jemand, ist jemand bereit, Leistung gegen Verifizierung einzutauschen? Oder sagen sie nur, dass sie es brauchen, aber wählen beim Bau den schnelleren, einfacheren Weg?
Ich habe noch keine klare Antwort.
Ich sehe nur, dass diese beiden Ansätze zwei unterschiedliche Sichtweisen auf dasselbe Problem widerspiegeln. Eine Seite akzeptiert Trade-offs, um die Benutzererfahrung zu optimieren, während die andere versucht, die Richtigkeit aufrechtzuerhalten, auch wenn dies noch nicht wirklich erforderlich ist.
Vielleicht sind beide in unterschiedlichen Kontexten richtig.
Oder vielleicht wird eines von beiden unpassend, wenn das System sich weiterentwickelt... Dennoch mag ich die Idee von SIGN ziemlich.
Ich werde weiterhin beobachten.