今天想清楚了一件事不能再浑浑噩噩了。内容做好了才有粉丝,有粉丝才好接广告有了广告收入才能做更好的内容,这个循环一旦转起来就停不下来。但得先迈出第一步,第一步最难。
$OPEN 的飞轮设计,跟这个完全一样只是规模更大且坐拥再链上。
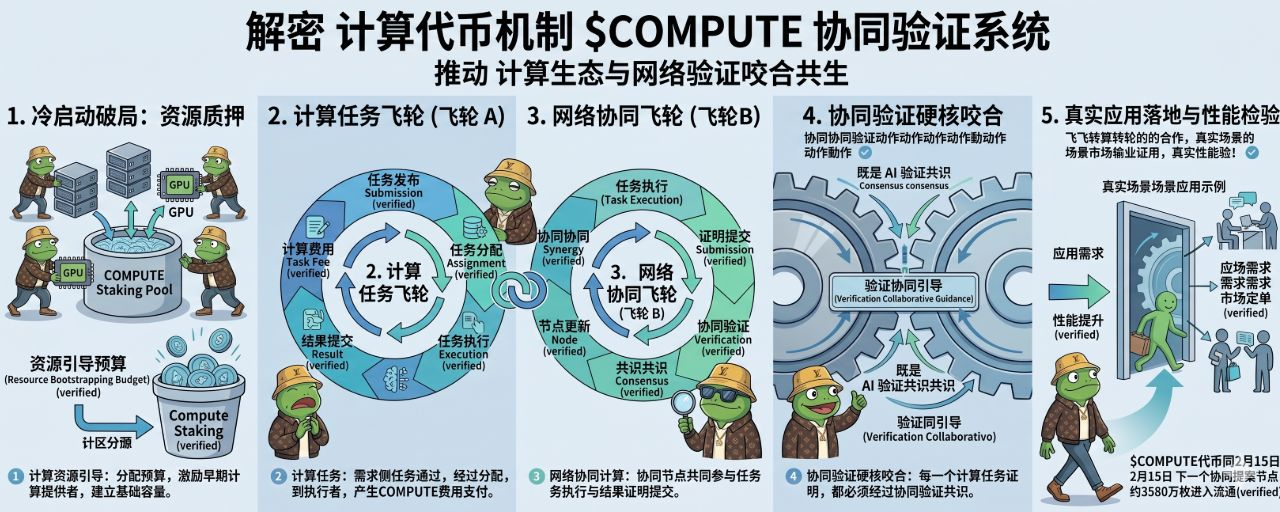
@OpenLedger 白皮书里描述了一套双飞轮结构:AI生态飞轮和区块链生态飞轮两个飞轮互相咬合,共同驱动整个系统加速。
AI生态飞轮的起点是模型创建者。开发者提交模型提案社区通过治理投票决定哪些模型值得推进。通过的模型进入数据收集阶段,Datanets里的数据贡献者开始向这个领域提交专业数据,数据质量够了之后模型开始微调
微调完成部署上线开始被用户调用。每一次调用产生推理费用费用按比例分给模型开发者数据贡献者和质押者。分到钱的贡献者有动力继续提交更好的数据,更好的数据让模型性能提升,性能更好的模型被调用得更多,产生更多费用整个循环加速。
区块链生态飞轮从另一个方向同时在转。每一次模型调用都是一笔链上交易,交易量增加让验证者收益增加,更高的收益吸引更多验证者加入更多验证者让网络更稳定更安全,更稳定的网络让开发者更愿意在上面建应用
这两个飞轮的咬合点在哪里?
AI模型的每一次推理调用,既是AI飞轮里的一个收益分配事件,也是区块链飞轮里的一笔链上交易。同一个动作同时驱动两个飞轮,这是OpenLedger把AI和区块链放在同一条链上的核心价值,不是简单的AI项目发了一个链上代币4而是AI的每一次使用都直接给区块链基础设施提供交易量和手续费收入。
我觉得这个结构里最值得关注的细节是治理的位置。在#OpenLedger 里,治理不只是投票决定协议参数,而是直接决定哪些AI模型可以进入开发流程。持有gOPEN代币的人投票,通过的模型才能进入数据收集和微调阶段。
这意味着社区的集体判断直接影响了哪些AI能力会被开发出来,治理权在这里不是管理工具是生产力的入口。这个设计如果运转良好,会让飞轮优先在真正有市场需求的方向上加速而不是开发者想做什么就做什么。
有一个问题:第一步最难我自己想清楚内容飞轮的逻辑容易,但真正开始做第一条内容,面对没有粉丝没有反馈的冷启动,大多数人都在这一步放弃了。
OpenLedger的飞轮同样面临冷启动问题——没有足够多的高质量数据贡献者
模型训练不起来,就没有推理调用
没有推理调用贡献者拿不到钱,就没有动力继续贡献。这个冷启动循环需要外部资金注入或者早期用户补贴来打破,白皮书里的代币分配里社区占了51.71%是最大的一块,这笔代币在冷启动阶段能不能被有效地用来激活早期贡献者,我觉得是飞轮能不能真正转起来的关键。
还有一个问题是飞轮的转速依赖AI模型的实际使用量。如果OpenLedger上训练出来的专业模型性能不够好,用户不愿意调用,推理费用产生不了整个机制就是空转。模型质量是飞轮的燃料没有燃料飞轮转不起来。白皮书描述的机制设计得很完整,但机制再好也代替不了模型本身的性能。
今天想清楚内容飞轮这件事,不代表明天就能做出爆款内容,想清楚和做到之间有很长的路。OpenLedger在纸面上自洽,能不能在真实环境里跑起来,要看第一批真正被市场认可的专业模型什么时候出现。
那才是飞轮开始真正转动的信号。