写研报这件事有一个很残酷的筛选机制:预测准了机构会找你转发你,下次还来;预测烂了不会有人骂你,只是慢慢没人理你了。市场是最诚实的评分系统,时间一长谁的判断值钱写得清清楚楚。
$OPEN 的RLHF机制,把这套逻辑搬进了链上。
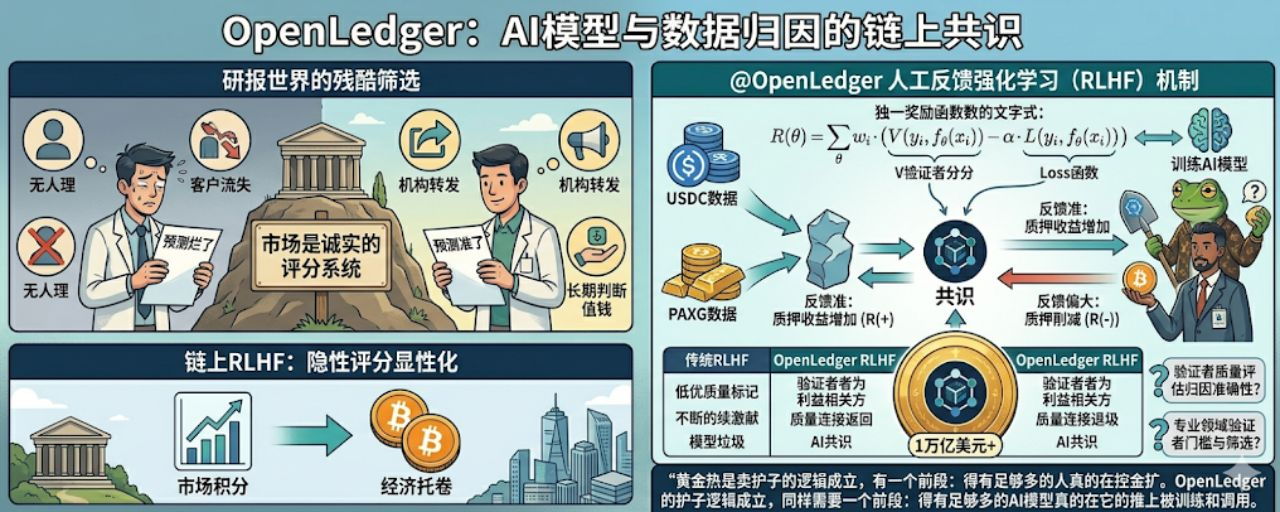
@OpenLedger 白皮书里描述了一套人工反馈强化学习机制,核心是:人工验证者对模型输出提供反馈,帮助模型对齐正确的逻辑和功能标准。但跟传统RLHF最大的不同是,这套反馈不是免费劳动——提供高质量反馈的验证者获得质押激励,提供低质量或者试图操纵系统的验证者面临质押惩罚。
白皮书里的奖励函数写得很具体:R(θ) = Σwi·(V(yi,fθ(xi)) − α·L(yi,fθ(xi))),其中V代表验证者打分,L是损失函数,α是防过拟合的正则化参数。
简单说就是验证者的判断和模型实际表现之间的偏差,直接决定了这个验证者能拿多少收益,或者被扣多少质押。你的评分越准,模型改进越明显,你的经济回报越高。
这个设计解决的是一个现有AI训练体系里的根本问题:人工标注员的激励和标注质量之间完全脱节。现在大多数AI公司雇人标注数据,按小时计费标注员的收入跟他们的判断准不准没有任何关系。
结果是大量低质量标注混进训练集,模型学到了垃圾但没有人为这个后果付出代价。
#OpenLedger 把这个关系倒过来。验证者在链上质押OPEN代币,质押代币是他们判断质量的经济承诺
我认为这个反馈是准确的,我用自己的钱来背书。模型训练完之后,实际表现会反过来评估每个验证者的历史反馈质量,判断准确的人质押收益增加,判断偏差大的人质押被削减。
这个机制让验证者从"完成任务的打工人"变成"对结果负责的利益相关方"。
我写研报那段时间,最大的压力不是写出来是写完之后等市场验证。预测对了客户会记住你,预测错了他们不会当面说,但下次不会再找你。OpenLedger的链上反馈机制把这个隐性的市场评分变成了显性的经济结算,时间周期压缩了,结果更透明,激励更直接。
但这里有一个我想了很久的问题:验证者的判断质量怎么评估?
白皮书里说是根据模型实际表现反过来打分,但模型表现本身是多因素的数据质量、架构选择、训练参数,每一个环节都在影响最终结果。
一个验证者提供了准确的反馈,但因为其他环节出了问题导致模型表现不好,他的质押会不会被错误地惩罚?这个归因的准确性,是RLHF机制能不能真正公平运转的关键,白皮书里对这个问题的处理没有给出足够详细的说明。
还有一个问题是验证者的专业门槛。医疗模型的反馈需要真正懂医学的人来提供,金融模型的反馈需要真正懂市场的人来评估。如果任何持有OPEN代币的人都可以成为验证者,专业领域的模型质量评估会不会被大量外行的判断稀释?
白皮书里对验证者的资质筛选机制描述得比较简略,这个细节在实际运营中会是一个真实的挑战。
切到交易视角$OPEN现在0.21附近,距ATH 1.85跌了88%,距1月低点0.139反弹54%。流通量2.9亿,总供应量10亿,71%还没进流通。
这个供应结构意味着后续解锁压力是持续存在的,RLHF机制能不能吸引足够多的高质量验证者进来,直接影响链上活跃度和代币需求。没有真实的验证者参与分账机制空转,代币需求就没有基本面支撑。
BTC这轮上涨机构买的是共识。OpenLedger的RLHF机制,本质上是在建立AI模型质量的链上共识——谁的判断准,链上说了算经济结果直接兑现。
这个共识机制能不能真正建立起来,要看第一批专业验证者的实际参与质量。
先看数据,再谈其他。