上周凌晨两点,我在一个做跨境电商的朋友办公室里坐到很晚。
他电脑屏幕上挂着五六个AI窗口,有自动生成广告文案的,有做客服回复的,还有一个在帮他批量翻译商品详情页。他一边盯着后台订单,一边随口说了一句让我印象特别深的话:“现在最值钱的已经不是AI了,是喂AI的人。”我当时愣了一下。
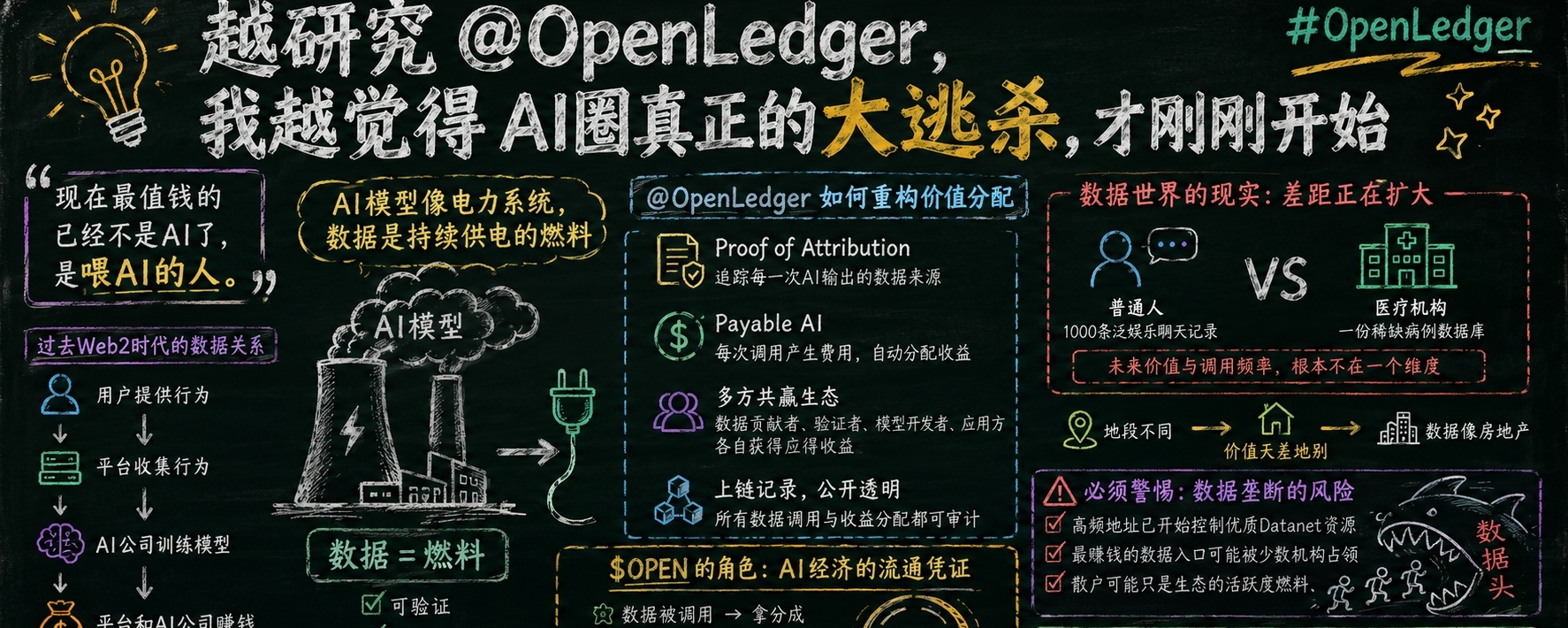
后来回去重新翻 @OpenLedger 的资料时,我突然意识到,现在整个AI行业其实正在发生一件很微妙的事情——模型开始越来越像“电力系统”,而真正稀缺的东西,变成了能持续供电的“燃料”。这个燃料,不是GPU。是数据。
更准确一点说,是那些能够被验证、被追踪、被持续调用的数据来源。

很多人聊 #OpenLedger 的时候,重点都放在Proof of Attribution、Payable AI这些概念上,但我现在越来越觉得,它真正想解决的,其实不是“AI怎么变聪明”,而是:“谁有资格长期从AI身上分钱。”
这个问题比模型参数重要得多。
过去Web2时代的数据关系其实很畸形。用户提供行为,平台收集行为,AI公司再拿这些行为训练模型,最后模型变强,真正赚到钱的是平台和模型公司,原始贡献者几乎拿不到什么持续收益。
你发过的帖子、改过的评论、点过的赞、纠正过的回答,本质上都在帮模型进化。但大部分人甚至不知道自己的行为已经变成训练材料。
所以我第一次看到 @OpenLedger 把“数据调用记录”和“收益归属”绑定的时候,我会觉得这个方向有点危险,但也确实有意思。
危险在于,它开始试图给“数据影响力”定价。而一旦数据开始被定价,人和人之间的数据差距会迅速拉大。
举个特别现实的例子。
一个普通人上传1000条泛娱乐聊天记录,和一家医疗机构上传一份稀缺病例数据库,它们未来被AI调用的频率和价值,根本不在一个维度。
这意味着未来的数据世界,很可能不会走向平均主义。
反而会越来越像房地产。地段不同,价格天差地别。有的数据会变成“黄金商铺”,有的数据永远只是路边摊。
而 $OPEN 在这里扮演的角色,其实更像整套系统里的“流通凭证”。
谁的数据被调用,谁拿分成。
谁验证归因,谁拿奖励。
谁运行模型,谁获得调用费。
它不是传统意义上的“治理币”,更像AI经济里的手续费燃料。这也是我最近越来越关注它的原因。因为现在很多AI项目的问题是:技术很强,但经济关系是空的。模型确实厉害,但没人知道长期利益怎么分。而OpenLedger至少开始把这个问题摆到桌面上了。不过我对它也不是完全乐观。因为一旦“数据收益”真的成立,接下来一定会出现另一个问题:数据垄断。
我最近看一些链上数据的时候发现,已经有部分高频地址开始持续控制优质Datanet资源了。这个趋势其实很危险,因为它意味着未来最赚钱的数据入口,可能会被少数专业机构提前占领。散户以为自己在参与AI革命。实际上很多时候只是给系统提供活跃度。这让我想到前几年DeFi最疯狂的时候。
大家都以为自己在参与金融民主化,结果最后真正稳定赚钱的,还是最懂规则、最懂流动性结构、最懂参数变化的人。AI数据经济也可能重复这个过程。表面是开放协作。底层依旧会形成新的资源阶层。
所以我现在看 @OpenLedger 的心态其实挺矛盾。一方面,我承认它确实抓住了AI行业未来最核心的一条线——数据价值归属。但另一方面,我也越来越怀疑:当“数据收益权”彻底金融化之后,普通人到底还能不能真正拥有自己的议价权?还是说,最后又会演变成另一种“数据地主游戏”。
这件事,我觉得未来两三年会越来越明显。AI真正改变世界的地方,可能从来都不是模型本身。而是谁能持续从模型身上收租。
