
我有个朋友是万能工,家里大多数时候他都能搞定省了不少事。
但上个月家里暖气管道出了问题,他看了一圈摇摇头说这个得找专业的。我理解,有些事就是超出了通才的范围。
$OPEN 在 AI 领域做的事,本质上是一样的。

我特意查看了 @OpenLedger 的白皮书:通用大模型是用海量互联网数据训练出来的,处理泛化问题够用。但放到金融、医疗与法律、网络安全这些专业场景里,准确度和可解释性都不够。原因不是模型不够聪明,是训练数据太泛,没有足够多的高质量领域数据支撑专业判断。
#OpenLedger 的定位不是替代 GPT,是在它旁边做一件它做不好的事。
训练专业领域的垂直模型,用真正懂这个领域的人提供的数据,针对特定场景做深度微调。
白皮书原话是 "coexist and utilize the existing foundational models to make them even more intelligent"。不是竞争,是互补。通用模型负责广度,专业模型负责深度,两者配合才能覆盖真实的商业需求。
这个定位解决的是一个现实问题:企业用 AI 不是为了聊天,是为了在特定场景里做准确的判断。
一个医院用 AI 辅助诊断,需要的不是一个能聊所有话题的大模型,是一个在这个科室的病例数据上训练出来的、能给出可解释结论的专科模型。
这种需求通用大模型满足不了,但也没有人在系统性地建这类模型的训练和归因基础设施,直到 OpenLedger 出来。
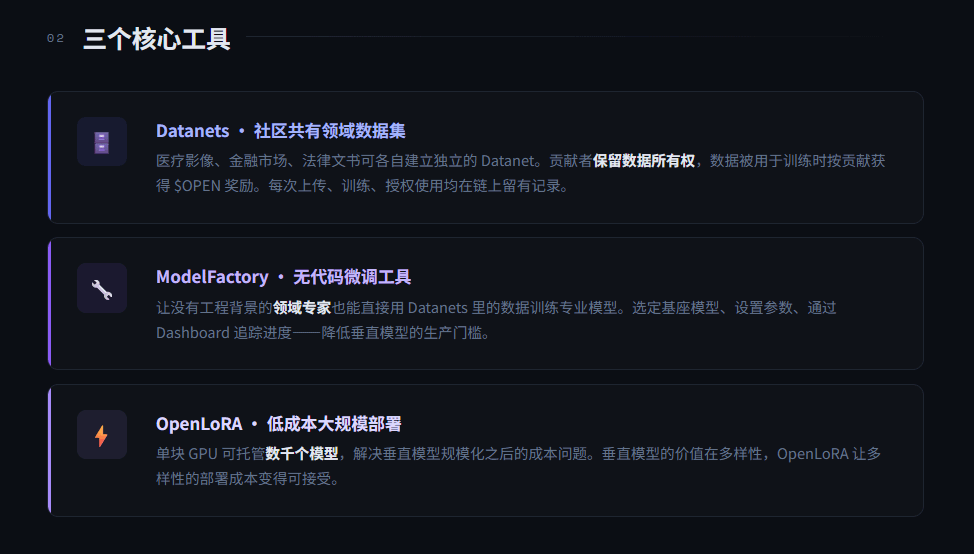
具体怎么实现的,有三个核心工具。
Datanets 是社区共有的领域专属数据集,医疗影像、金融市场、法律文书都可以建独立的 Datanet,贡献者保留所有权,数据被用于训练时按贡献获得 $OPEN 奖励。
ModelFactory 是无代码微调工具,让没有工程背景的领域专家也能直接用 Datanets 里的数据训练专业模型。
OpenLoRA 是部署层,单块 GPU 可托管数千个模型,解决了垂直模型规模化之后的成本问题。
但这三个工具里,我觉得最关键的是另一个机制:Proof of Attribution(PoA)。它在链上记录每个数据集、每次训练步骤和模型推理过程,精确追踪「谁的数据训练了这个模型的哪个输出」,然后据此分配收益。
这才是整个激励结构的底层。数据质量是表层,PoA 能不能真正量化「哪条数据贡献了多少」才是核心——如果归因机制是黑盒,数据再好也没有激励让领域专家持续往里放真实的专业数据。

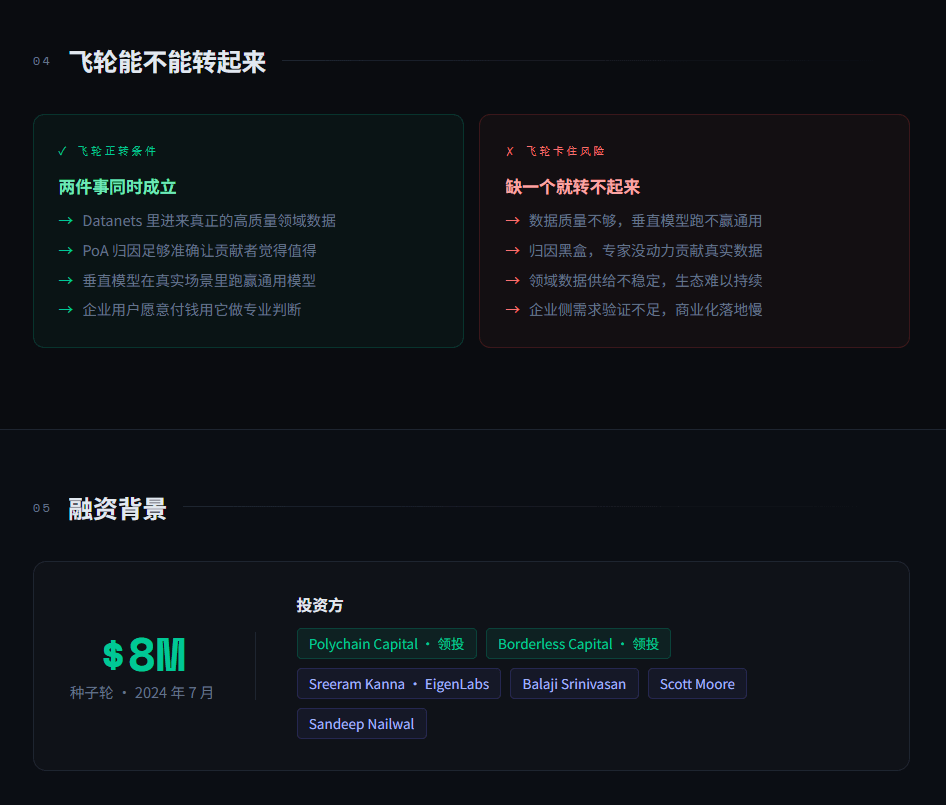
融资背景2024 年 7 月完成 800 万美元种子轮,由 Polychain Capital 和 Borderless Capital 领投,EigenLabs 的 Sreeram Kanna、Balaji Srinivasan 等参与。这个投资人名单在 AI × 区块链赛道里不算随便。
我觉得这个切入点选得对。通用大模型的竞争已经是巨头之间的军备竞赛,进去没有意义。垂直数据和归因基础设施这个层次,目前还没有人系统性地做。
当然,专业模型能不能真的比通用模型在垂直场景里表现更好,最终取决于两件事同时成立:Datanets 里进来的是真正的高质量领域数据,以及 PoA 的归因足够准确让贡献者觉得值得持续贡献。缺一个,飞轮就转不起来。
我朋友那个万能工,遇到超出范围的问题会直接说不行,这是我信任他的原因。
@OpenLedger 的专业模型如果真的能在垂直场景里给出通用模型给不了的答案,这个定位就站得住。检验标准很简单,就看真实的企业用户愿不愿意付钱用它做决策。