
前段时间,一个做猎头的朋友给我讲了件特别离谱的事。
他们公司开始用AI筛简历之后,内部很快发现一个问题:模型越来越“不相信人类”。
有些候选人简历明明写得很好,但AI会直接判定风险高;而有些包装痕迹很重的简历,反而能轻松通过。后来他们往回查,才发现问题根本不在模型本身。而在数据。
因为训练语料里混进了大量营销模板、伪造案例、批量润色内容,导致模型慢慢学会了“错误的判断逻辑”。
朋友那天说了一句让我印象特别深的话:“AI最危险的地方,不是它会骗人,而是它会开始相信骗子。”
我后来重新研究 @OpenLedger 的时候,脑子里突然一直在反复想这句话。
因为我越来越觉得,现在AI行业真正缺的,可能不是更强模型。而是一套“可信度系统”。
很多人现在聊 #OpenLedger ,都会重点说它的数据归因、验证者、Datanet这些东西。但我最近越看越觉得,它本质上其实是在尝试做:AI世界里的“信用体系”。这里的信用,不是金融征信哦。而是:谁的数据可信。谁的反馈可靠。谁的模型长期稳定。谁的行为能够被持续验证。
以前互联网时代,信息最大的特点是:真假混在一起。但AI时代会更夸张。因为未来不是人类在阅读内容。而是AI在阅读内容。一旦垃圾数据大量进入训练池,模型会迅速被污染。
最恐怖的是:这种污染不会立刻爆炸。它会慢慢累积。最后变成一种系统性偏差。
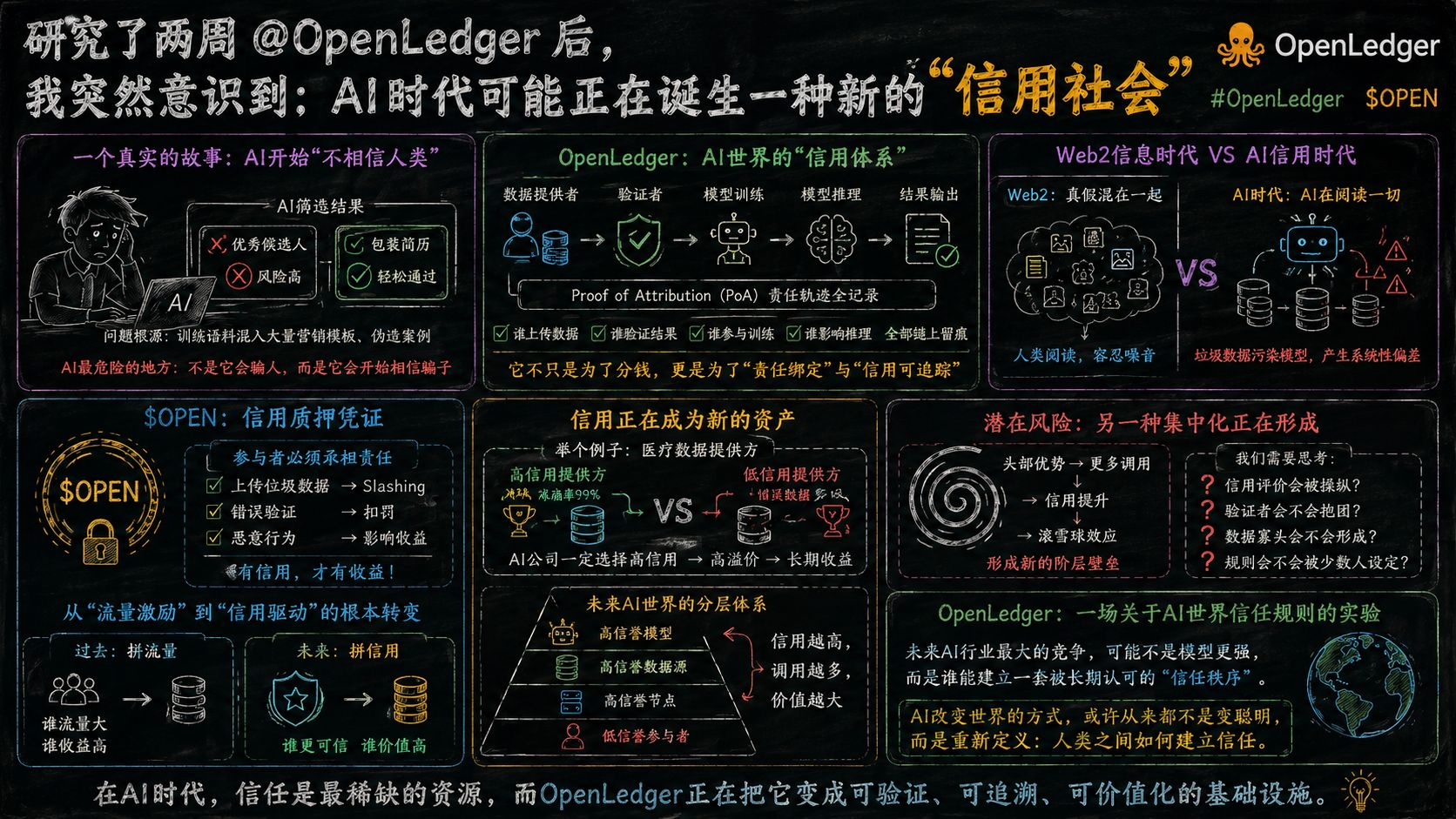
这也是为什么我最近越来越觉得,OpenLedger真正想解决的,其实不是“AI生成”,而是“AI信任”。
它的Proof of Attribution机制,说白了就是在给整个AI生产链建立“责任轨迹”。谁上传数据、谁验证结果、谁参与训练、谁影响推理,全部留痕。很多人觉得这只是方便分钱。
但我现在越来越怀疑:它真正重要的地方,其实是“责任绑定”。因为未来AI一定会进入高风险行业。医疗、金融、自动驾驶、法律。一旦模型出现错误,谁负责?传统AI公司的做法,其实特别像黑箱。模型怎么训练出来的。用了哪些数据。谁参与过反馈。外部根本看不到。
但OpenLedger现在做的,是试图把整条责任链拆开。这意味着未来AI世界可能会慢慢出现一种新逻辑:“信用可追踪。”
你贡献过多少有效数据。
历史验证准确率怎么样。
有没有恶意上传垃圾语料。
全部会形成长期记录。
而 $OPEN 在这里,其实更像一种“信用质押凭证”。因为你不是随便参与系统就能赚钱。
你需要承担责任。上传垃圾数据可能被Slashing。错误验证可能被扣罚。恶意行为会影响长期收益。这跟以前那种纯流量激励已经完全不是一个东西了。
以前Web2平台拼的是:谁流量大。
未来AI平台可能拼的是:谁更可信。
而一旦“可信度”开始金融化,事情就会变得特别有意思。因为信用本身,会慢慢变成一种资产。
举个很现实的例子。
未来两个医疗数据提供方:一个长期数据准确率99%。一个经常混入错误病例。AI公司会选择谁?一定是前者。因为AI行业最怕的不是数据少。而是数据错。
这意味着:未来高信用数据源,可能会像蓝筹资产一样被长期溢价。而低信用数据,会越来越没人愿意调用。到最后,整个AI世界可能会形成一种新的等级体系。
高信誉节点。
高信誉数据源。
高信誉模型。
低信誉参与者。
全部逐渐分层。
很多人现在还没意识到:这东西其实已经越来越像“数字信用社会”。
而这也是我现在对 @OpenLedger 最复杂的地方。因为它确实在解决AI行业最真实的问题。但同时,它也可能带来另一种新的集中化。
因为信用一旦变成生产资料,头部优势会越来越大。
信誉高的人会获得更多调用。
更多调用又会继续提高信誉。
最后形成一种滚雪球结构。
这跟现实社会里的资本积累,其实没什么区别。
我最近观察部分Datanet的时候,就已经开始出现这种趋势了。一些高质量地址的调用频率明显越来越高。而普通参与者,越来越难进入核心流量层。所以很多人现在讨论AI民主化,我其实是保留意见的。
因为历史已经反复证明:任何涉及利益和信用的系统,最后都会慢慢形成新的阶层。AI也不会例外。
这也是为什么我现在看 $OPEN ,不会单纯把它理解成AI概念币。
我更愿意把它看成:一场关于“AI世界信任规则”的实验。它现在还远远没成熟。很多问题也还没解决。
比如:
信用评价会不会被操纵?
验证者会不会抱团?
数据寡头会不会形成?
这些问题未来都可能爆发。
但至少目前来看,@OpenLedger 已经开始认真讨论:AI世界里,谁值得被相信。
而我越来越觉得:未来AI行业最大的竞争,可能不是谁模型更强。
而是谁能建立一套被长期认可的信任秩序。因为模型会迭代。技术会扩散。但一旦信用体系形成,后来者会非常难撼动。
AI最后真正改变世界的地方,可能从来都不是它有多聪明。
而是:它开始重新定义,人类之间到底该如何建立信任。