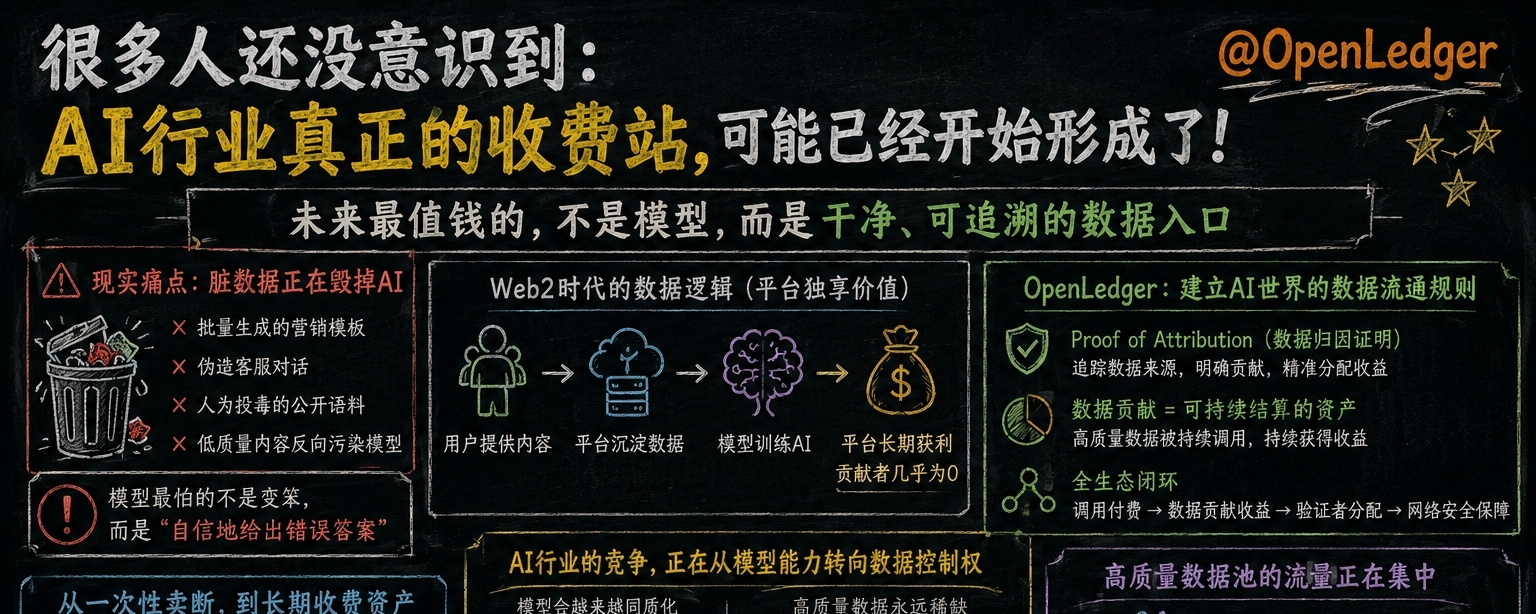
最近跟一个做企业 AI 系统的朋友聊了很久。他们团队原本以为,当前 AI 行业最大的成本压力会来自 GPU 和推理资源。但真正上线之后,他们发现最麻烦的问题,根本不是算力,而是数据质量。同样一句用户问题,模型有时候能正常回答,有时候却会突然出现逻辑混乱。后来团队回查训练语料,才发现问题出在数据源。大量低质量内容正在反向污染模型。包括批量生成的营销模板、伪造客服对话、甚至人为投毒的公开语料。
朋友当时说了一句让我印象很深的话:“现在 AI 最贵的东西,已经不是模型了,而是干净的数据入口。”也是从那之后,我重新认真研究了 @OpenLedger 。很多人现在聊 #OpenLedger ,还停留在“AI + 区块链”的概念阶段。但我越来越觉得,它真正重要的地方,其实是它正在尝试建立一套 AI 世界里的“数据流通规则”。
过去 Web2 的逻辑很简单:用户提供内容。平台沉淀数据。模型公司训练 AI。最后真正长期获利的,往往只有平台本身。而原始数据贡献者,几乎拿不到持续收益。但 OpenLedger 的结构不一样。它把“数据贡献”本身,开始变成一种可持续结算的资产。尤其是 Proof of Attribution 机制,本质上解决的是:模型到底用了谁的数据。哪些数据真正影响了输出。谁应该获得长期收益。以前的数据,更像一次性消耗品。现在的数据,开始慢慢变成“长期收费资产”。
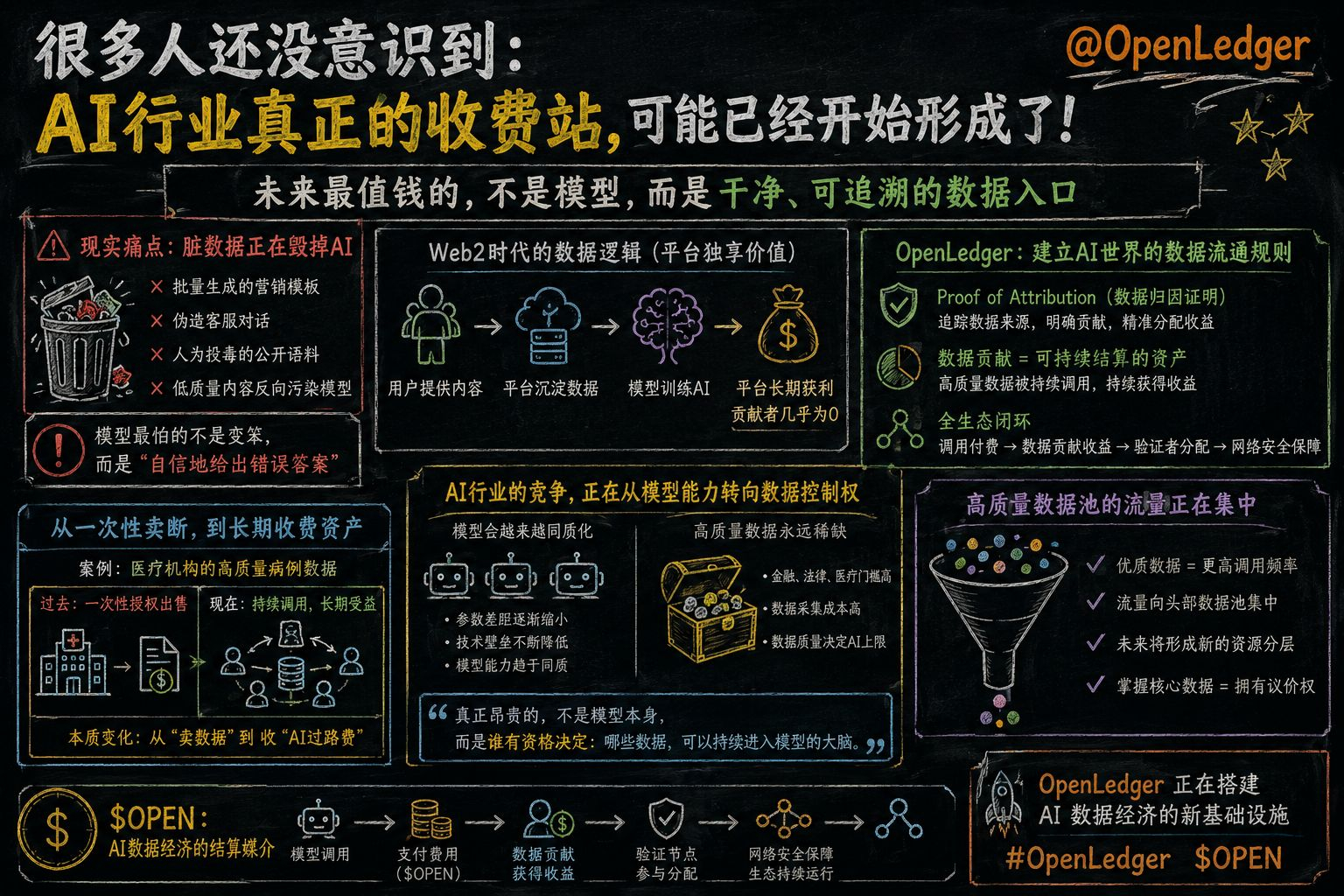
举个很现实的例子。一家医疗机构上传高质量病例数据后,过去可能只是一次性授权出售。但在 @OpenLedger 的逻辑里,只要未来模型持续调用这些数据,对应的数据源就能不断获得收益分配。这已经不是传统意义上的卖数据了。而是在收 AI 时代的“长期过路费”。而 $OPEN 在里面承担的,其实更像整个生态里的结算媒介。模型调用需要支付费用。数据贡献会获得收益。验证节点参与分配。整套 AI 数据经济开始形成闭环。不过我觉得,这件事真正值得关注的地方,还不只是分账。而是:未来 AI 行业的竞争,可能会从“模型能力”,逐渐转向“数据控制权”。因为模型会越来越同质化。但高质量数据,永远是稀缺资源。尤其是金融、法律、医疗这些高门槛行业。企业真正害怕的,从来不是模型偶尔变笨。而是模型“非常自信地给出错误答案”。所以未来最值钱的,可能不是参数最多的模型。而是谁能长期控制最稳定、最可信的数据来源。
我最近观察部分 Datanet 的调用情况时,其实已经能明显感觉到:高质量数据池的流量,正在越来越集中。这意味着未来 AI 行业,很可能会慢慢形成新的资源分层。谁掌握核心数据。谁就拥有更强的议价权。所以我现在越来越觉得:@OpenLedger 真正值得研究的地方,并不是单纯的 AI 概念。而是它正在提前搭建一种新的 AI 数据经济结构。
未来 AI 世界里,真正昂贵的,可能从来都不是模型本身。而是谁有资格决定:哪些数据,可以持续进入模型的大脑。
