
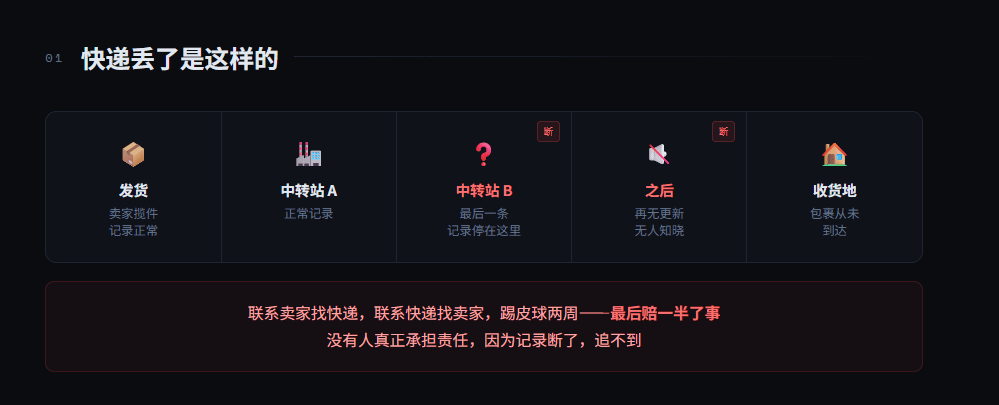
上个月买的东西快递丢了,打开物流记录一看,最后一条信息停在某个中转站之后再没有更新。联系卖家说找快递,联系快递说找卖家两边踢皮球踢了两周,最后赔了我一半了事。没有人知道包裹在哪个环节消失的,也没有人真正承担责任
这件事让我想清楚一个问题:透明度不是可选项是责任链条的基础。没有完整的记录出了问题就是一笔糊涂账。
$OPEN 在解决 AI 领域同样的问题,只是规模更大影响更深。
我看完 @OpenLedger 白皮书之后的理解是:大多数 AI 系统是黑盒训练数据来自哪里、模型经历了哪些改动、在现有的 AI 基础设施里几乎无法回答。GPT 告诉你一个结论你没有任何办法追溯这个结论背后用了哪些数据、哪些人的知识贡献了多少、中间经历了哪些训练步骤。
这不只是技术问题是信任监管问题,
#OpenLedger 把 AI 模型的每一个关键节点都写进链上记录。数据贡献者提交数据的时候链上生成一条归因记录,包含贡献者地址、数据特征、提交时间戳。
模型进入微调阶段训练参数的变化、使用的数据集版本每一次迭代的结果都有对应的链上记录。
这条记录链是完整的,不会在某个中转节点断掉。

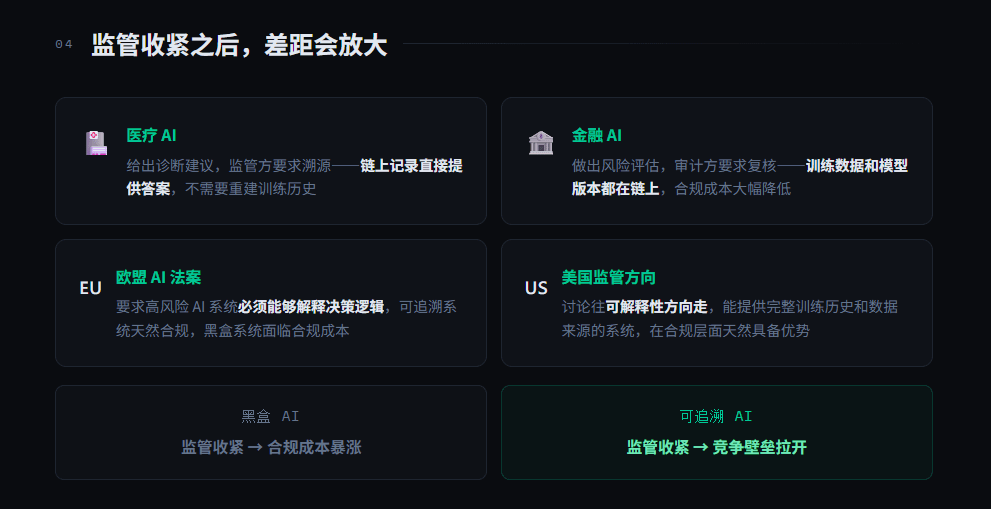
我觉得这个设计的价值不只是对贡献者公平,是对整个 AI 行业的信任基础有意义。现在 AI 监管正在收紧,欧盟的 AI 法案要求高风险 AI 系统必须能够解释决策逻辑,美国的监管讨论也在往可解释性方向走。一个能提供完整训练历史和数据来源的 AI 系统,在合规层面天然具备优势。
医疗 AI 给出诊断建议,监管方要求溯源链上记录直接提供答案;融 AI 做出风险评估审计方要求复核,训练数据和模型版本都在链上。
黑盒 AI 和可追溯 AI 在监管环境收紧之后的处境会完全不同。
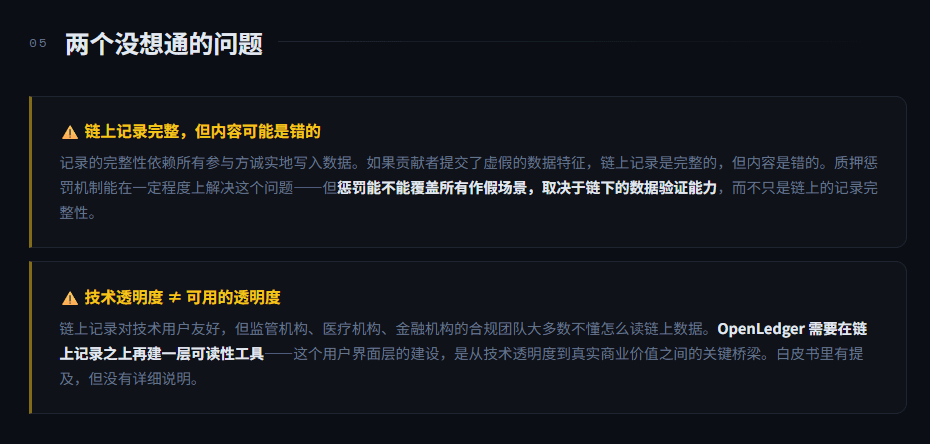
但链上记录本身有一个我一直在想的问题:记录的完整性依赖所有参与方诚实地把数据写进链上。如果某个环节的贡献者提交了虚假的数据特征,或者刻意隐瞒了数据来源,链上记录是完整的但记录的内容是错的。
OpenLedger 的质押机制在一定程度上解决了这个问题

提交虚假数据的成本是质押被惩罚,但惩罚机制能不能真的覆盖所有作假的场景取决于链下的数据验证能力,而不只是链上的记录完整性。
还有一个问题是记录的可读性。链上记录对技术用户友好,但监管机构医疗机构、金融机构的合规团队,大多数不懂怎么读链上数据。OpenLedger 需要在链上记录之上再建一层可读性工具,让非技术用户能够真正使用这些透明度数据。
我那个快递如果物流记录是完整的、每个中转节点都有签收记录、责任方清晰可查,结果不会是两周踢皮球之后赔一半了事。OpenLedger 想给 AI 行业建的就是这种每个节点都有记录、责任链条完整可追溯的基础设施。
黄金的价值可以用重量验证,BTC 的价值可以用链上记录验证。AI 模型的价值一直没有一套标准的验证方式,直到有人开始把训练过程本身上链。
链上记录不保证 AI 模型是好的,但保证了出了问题之后有账可查。这件事在 AI 监管越来越严的环境下比很多人现在意识到的更重要。
去看 OpenLedger 上第一批真正被监管机构或者企业合规团队引用了链上记录的案例
这个转折点目前还没有发生但它是整个逻辑链条里最值得盯的那个信号。那才是透明度从技术特性变成商业时刻。