
这两周我重新梳理了一遍 AI 赛道的数据,发现一个特别明显的现象:现在市场上最不缺的,就是“模型演示”。
打开推特,到处都是:更大的参数。更快的推理。更炫的 Agent。更复杂的自动化工作流。但真正落地之后,很多项目都会卡在同一个地方:企业不愿意长期付费。原因其实很现实。因为大部分 AI 产品解决的,还是“能不能生成”的问题。而不是“能不能稳定创造价值”。
前几天跟一个做工业软件的朋友聊天,他们团队去年接入过三个不同的 AI 系统。一开始效果都不错。自动生成报告。自动识别设备异常。自动预测维护周期。可半年之后,他们内部把其中两个系统直接停掉了。不是因为模型不够聪明。而是:结果越来越不稳定。
有时候同样的数据输入,模型会给出完全不同的判断。有时候系统更新一次,过去好用的逻辑直接失效。
朋友后来总结了一句话:“企业真正怕的不是 AI 不会干活,而是 AI 今天会、明天不会。”
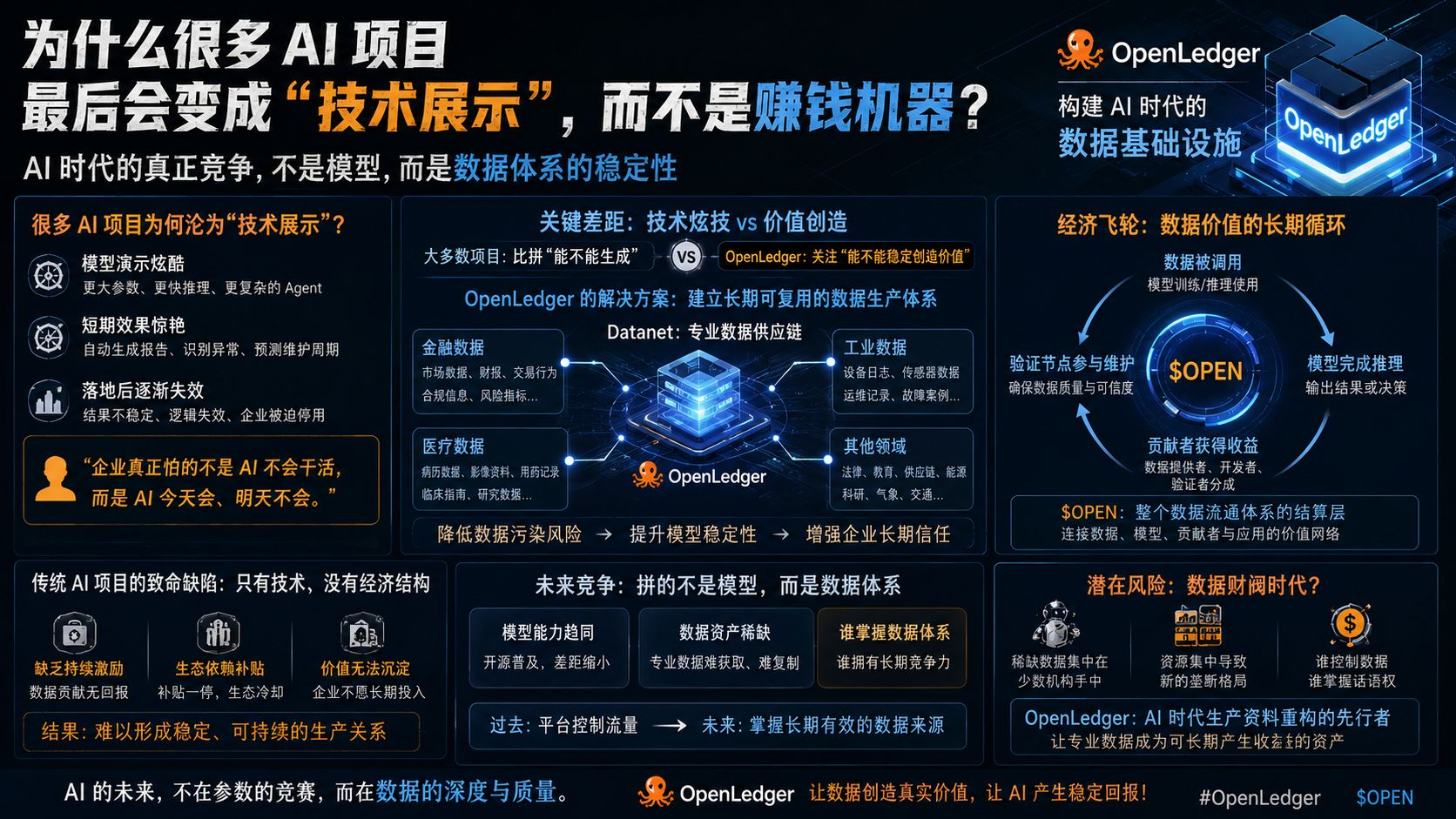
那天回去之后,我重新看了 @OpenLedger 的路线图,突然意识到它和很多 AI 项目最大的区别,其实不在模型。而在于:它在试图给 AI 建立“长期可复用的数据生产体系”。很多人现在聊 #OpenLedger ,都会重点看币价、节点、Agent、Datanet。
但我最近更在意的是它整个结构里的另一层逻辑:它想解决的,其实是 AI 行业最容易被忽视的问题——数据稳定性。
过去互联网时代,内容平台的核心资产是“流量”。但 AI 时代不一样。AI 最值钱的,不是用户看了多少内容。而是模型能不能持续学到“有效内容”。这两者差别非常大。因为模型不是一次性消费数据。它会长期依赖数据质量。
而 OpenLedger 的 Datanet,本质上其实有点像“专业数据供应链”。不同领域的数据源被拆开管理。金融的数据归金融。医疗的数据归医疗。工业的数据归工业。目的不是为了分类好看。而是为了降低“数据污染”的风险。
现在很多 AI 公司最头疼的一件事,就是训练池越来越混乱。AI 写的内容继续喂给 AI。营销内容伪装成专业知识。低质量语料不断重复扩散。最后模型表面参数越来越强。底层判断却越来越飘。这也是为什么最近越来越多企业开始重新重视“垂直数据”。因为真正能落地赚钱的 AI,最后一定会走向行业化。通用模型负责底座。专业数据决定上限。而 $OPEN 在这里,更像整个数据流通体系里的结算层。数据被调用,模型完成推理,贡献者获得收益,验证节点参与维护。整个结构开始形成一种长期循环。
这也是我最近开始重新评估 OpenLedger 的原因。因为它现在做的事情,本质上已经不是单纯的“AI+Crypto”。
而是在尝试解决:AI 行业未来到底怎么形成稳定生产关系。这一点其实很重要。过去很多 AI 项目最大的问题,就是只有技术,没有经济结构。模型很强。演示很酷。
但没人知道:数据为什么要持续贡献?开发者为什么长期维护?企业为什么愿意沉淀内容?最后整个生态只能靠补贴。
可一旦补贴停止,系统活跃度就会迅速下滑。但 OpenLedger 现在的方向不太一样。它是在尝试让“专业数据”本身,变成一种能长期产生收益的资产。这会带来一个很大的变化:未来 AI 行业拼的,可能不再是谁模型最炫。而是谁的数据体系最稳定。因为模型能力会越来越接近。开源会越来越普及。真正难复制的,反而是长期积累的行业数据网络。
不过这里也有一个我一直在观察的问题。当高质量数据开始持续产生收益之后,未来会不会出现新的“数据财阀”?因为真正稀缺的数据,本来就掌握在少数机构手里。医院、工业系统、大型企业、专业研究机构。
普通人能提供的大部分内容,其实很容易被替代。这意味着未来 AI 行业,很可能会慢慢形成新的资源集中。
谁控制核心数据。
谁控制模型质量。
谁就拥有更高的话语权。
所以我现在看 @OpenLedger ,已经不会单纯把它理解成一个 AI 项目,我更愿意把它看成:一场关于“AI时代生产资料重构”的实验。过去互联网平台控制流量。未来 AI 世界里,真正重要的,可能会变成:谁控制长期有效的数据来源。