you look at the current generation of AI apps long enough and a specific pattern becomes visible. most of them are doing similar things with the same underlying models. not disappointing exactly. something closer to the feeling of recognizing a capability ceiling not because models aren't powerful enough, but because the data underneath them has run thin for anything requiring real domain depth.
the way this space frames the AI app opportunity treats model access as the scarce resource. get access to a capable model, connect it to a good interface, ship the product. that holds for general tasks. but it stops working the moment you're building for a domain where the difference between a useful answer and a correct answer depends on depth that general training data doesn't have. a legal app built on general training gives you legal-sounding outputs. a legal app built on verified case law, annotated practitioner decisions, and jurisdiction-specific precedent gives you legal outputs. those are not the same product. and the difference is not in the model architecture it's in the data that shaped it.
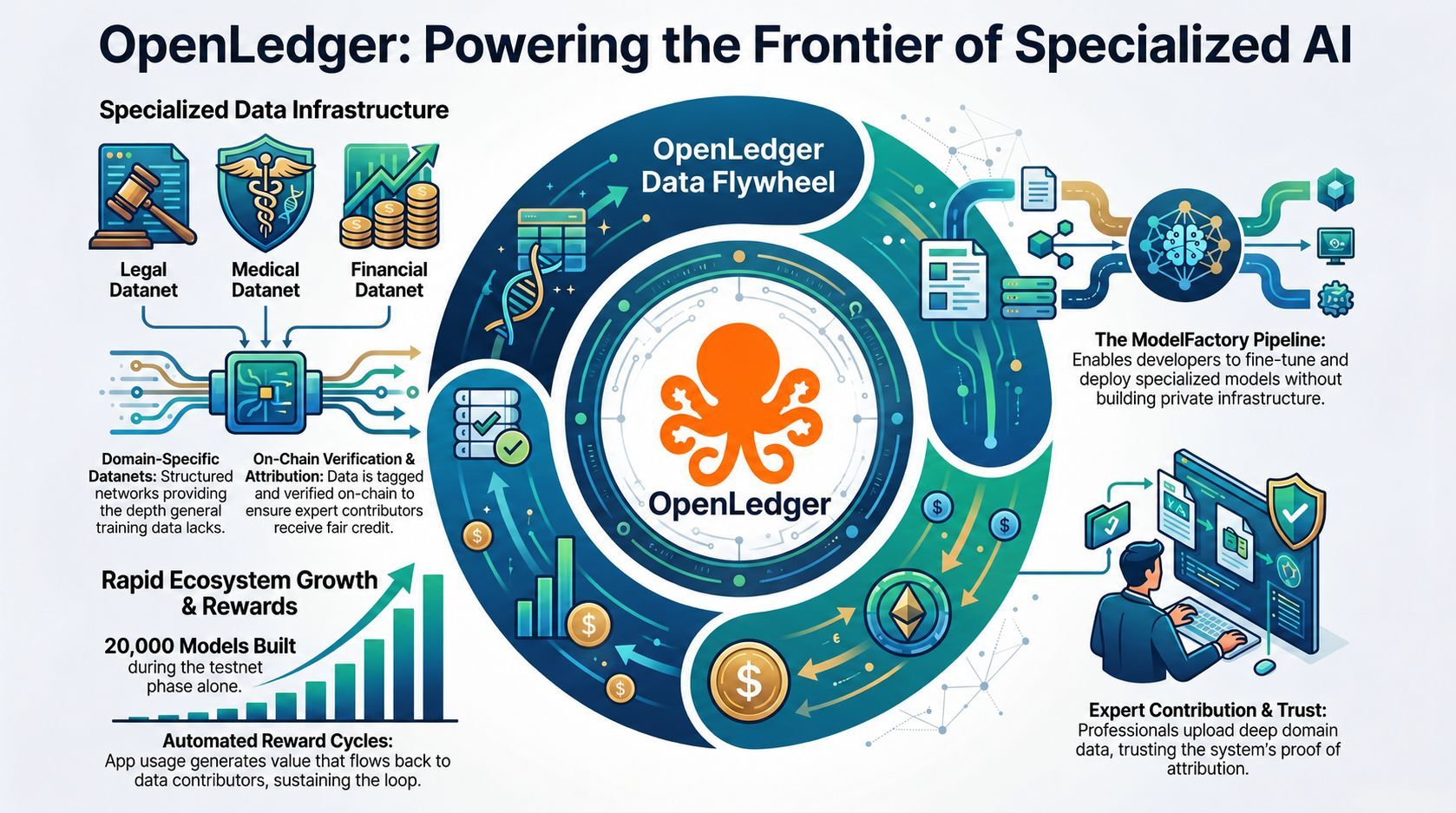
what openledger provides here is real. contributors upload domain-specific data to datanets structured networks organized around legal, medical, financial, and security verticals where data is tagged, verified, and attributed on-chain before it's available for model training. the Story Protocol partnership built a functioning framework for legal AI that compensates rights holders automatically. ModelFactory lets developers fine-tune and deploy specialized models without building training infrastructure. twenty thousand models were built during testnet.
so yes openledger could unlock a new generation of AI apps. the pipeline from domain data to deployed specialized model exists and it works.
but infrastructure availability has never been the constraint on what gets built.
the constraint has always been the intelligence layer underneath it. and this is where the assumption inside most of the excitement deserves a closer read.
here's what keeps pulling focus: a specialized language model is only as valuable as the domain data in its underlying datanet. that data only gets deep if contributors with genuine expertise doctors, lawyers, analysts, security researchers actually upload it. those contributors only upload if they trust that proof of attribution will correctly measure their influence and route rewards fairly over time. that trust only builds as models become valuable enough for the reward signal to mean something. which requires apps generating usage. which requires models specialized enough to matter.
that's a circular dependency. apps need model quality. model quality needs datanet depth. datanet depth needs contributor trust. contributor trust needs demonstrated reward. demonstrated reward needs usage. usage needs apps. the circle runs one way and breaking into it requires committing before the downstream validation exists.
then comes the timing question. because of course.
domain experts are not early adopters by nature. a doctor evaluating whether to upload anonymized case data to a medical datanet is making an expected-value decision, not an ideological one. they need to believe the attribution system will route meaningful rewards when their data is shaping outputs months later. that belief is hard to establish before the ecosystem generates the usage that makes rewards significant. builders arriving now are building on what the contributor base at this stage has provided and the gap between what the tooling can do and what the data currently contains is not visible from the documentation.
there is also a design tension here that rarely gets discussed alongside the app opportunity.
openledger is built on the assumption that contributor and developer incentives compound together contributors earn as data gets used, developers earn as apps generate usage, and the flywheel builds. that's coherent. but flywheels require an initial push the flywheel itself doesn't generate. that means builders willing to ship on models not yet category-defining, and contributors willing to share expertise before the reward signal fully justifies it. the architecture describes steady state well. it doesn't specify who absorbs the cost of reaching it.
and yet building this at all represents something categorically different from how the AI application space has approached domain depth until now.
most platforms take the easier path: wrap a general model, optimize the interface, build for tasks general training handles adequately. openledger is attempting something harder build the data infrastructure that makes domain-specific intelligence possible in the first place. a legal app on openledger's legal datanet is a different product from a legal chatbot wrapping a general model. that difference matters for real-world applications. the fact that earning it requires solving a bootstrapping problem nobody has fully solved is not evidence the attempt was wrong. it's evidence the problem is worth solving.
the question worth sitting with is not whether openledger's infrastructure can support better apps it can. the question is what kind of builders and contributors show up first, and whether what they provide is deep enough to make the next wave arrive with something more to build on.
because in systems where quality compounds from the data layer upward, the early decisions which domains get populated, which builders commit before the models are mature determine the ceiling for every application that follows. and that ceiling gets set long before most people looking at the app layer think to ask about it.
Trading always carries risks. This is not financial advice.
@OpenLedger $OPEN #OpenLedger $EDEN $BSB