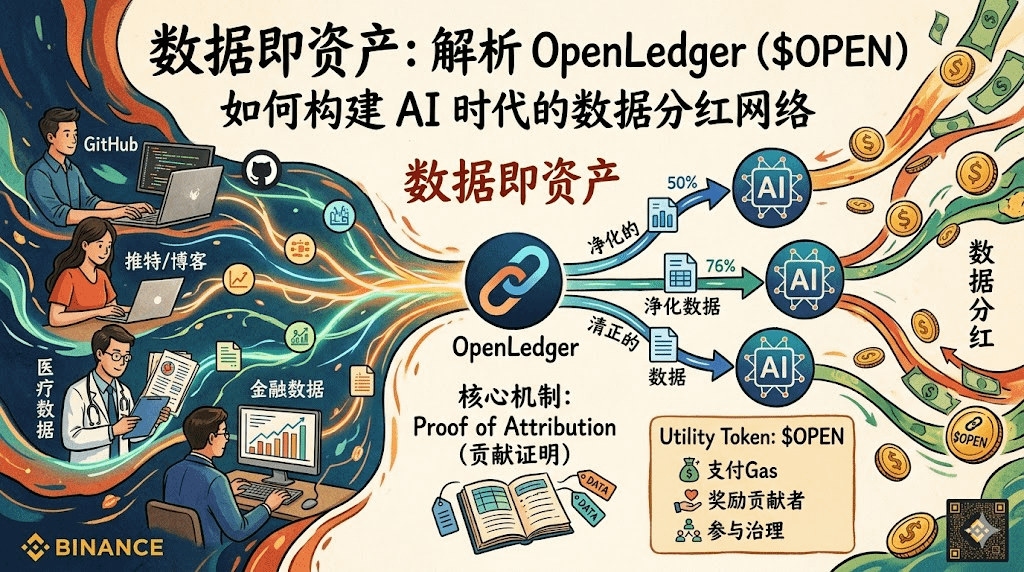
Now let's talk AI. Everyone's eyes are glued to those few giants. Today, this company’s parameters hit a few billion, tomorrow that one’s context jumps to tens of thousands. But have you thought about one question: whose data are these models consuming? I scroll through Twitter, write blogs, toss code on GitHub, and all that content gets used to train models, while companies profit off it. What do I get? Nothing at all. It's not that I need those few bucks, but this feeling of 'data freeloading' is definitely uncomfortable.
Recently, I came across a project called @OpenLedger that has an interesting angle. Instead of competing over model parameters, it specifically addresses one issue: if data is contributed, how do we prove it and how do we share the rewards? The core mechanism is called Proof of Attribution. In simple terms, it’s on-chain accounting. It tracks who provided what data, which model used that data, and what output was generated—all logged. Later, when the model starts raking in profits, rewards are automatically distributed based on contribution size.
Sounds a bit idealistic, right? But after some thought, this is actually a real need. The public data that can be scraped online is almost exhausted. So where's the real valuable data? It's in the internal databases of hospitals, law firms, and financial institutions. This data is high quality and highly specialized, but why would they just give it to you? You need a mechanism to make them willing to share it. What OpenLedger aims to do is just that: you contribute data, and you keep getting dividends.
Technically, it’s built on the OP Stack chain, compatible with EVM, and connects directly through MetaMask. They have a platform called OctoClaw, which integrates data acquisition, decision-making, and on-chain execution. There’s also VibeCoding, claiming to lower the barrier for AI agent development. I haven’t dived deep into these yet, but they're headed in the right direction. The token is called $OPEN , with a total supply of 1 billion and an initial circulation of about 21.55%. Its functionality is that of a typical utility token: paying Gas fees, rewarding data contributors, and participating in governance. I heard there's also a 1% transaction burn mechanism; I’ll leave that to you to judge.
To be honest, whether this project can take off hinges not on technology (the technical approach is quite clear). The challenge lies in: who can persuade those who hold high-value data to put their 'treasures' on the chain? This involves a comprehensive design of business models, trust, and incentive mechanisms. However, one point I strongly agree with: in the AI era, the issue of data ownership and revenue distribution will eventually need to be resolved. OpenLedger is at least moving in that direction, rather than just launching a token or hype. If you have time, check out their official website or give OctoClaw a try. I think instead of just watching others hype parameters on Twitter, it’s better to pay attention to these genuine attempts at addressing the underlying issues of profit distribution. (This article is part of a platform task and does not constitute any investment advice.)