I've been grinding in the crypto space for almost ten years, seen all sorts of hype cycles. Every day, I watch various projects stack blocks on-chain with flashy websites. It's either some open-source models shoved into the frontend calling themselves the next AI star, or they drop a shitcoin to stir up some emotional value. Honestly, my wallet is already immune to this grand narrative, and the frequent AI projects have me instinctively keeping my guard up.
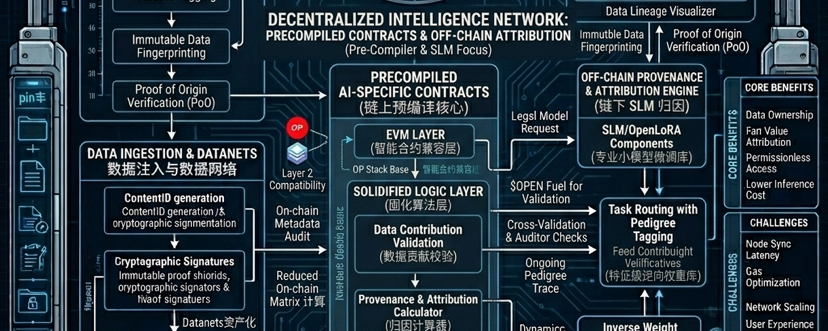
Just wrapped up the read.@OpenLedger In the whitepaper, everyone is hyping its Proof of Attribution contributor data attribution, or flocking to discuss those community-owned datasets Datanets. But I'm a bit more discerning; I'd rather talk about the technical underpinnings mentioned in the whitepaper that hardly anyone brings up. For instance, the AI-specific 'Precompiled Contracts' quietly slipped into its EVM-compatible Layer 2 infrastructure.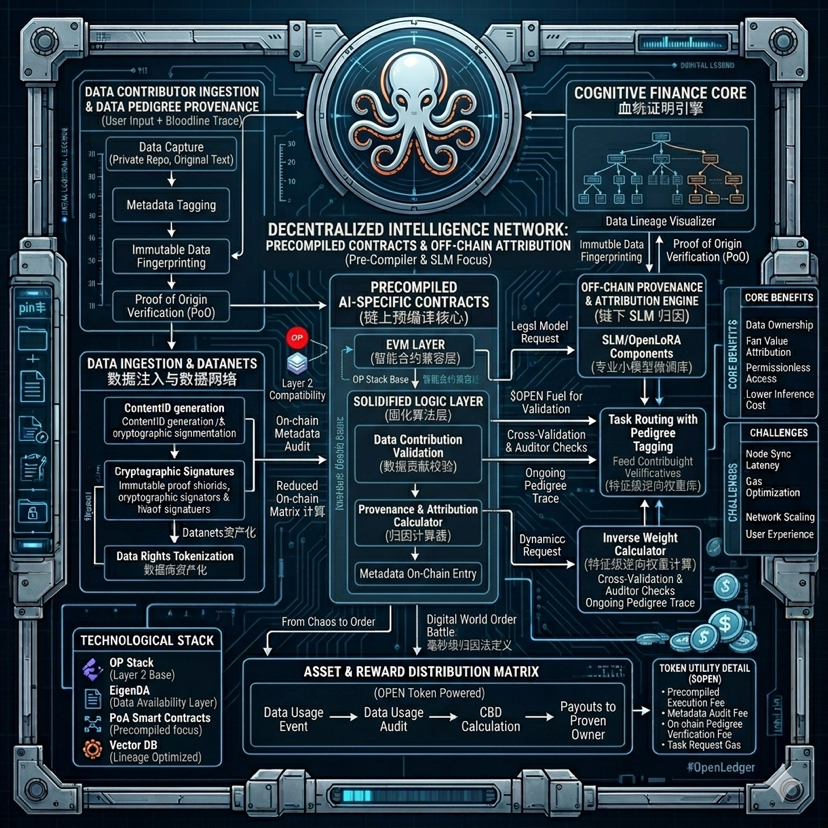
Put simply, it used to be a disaster to do AI on-chain. Ordinary smart contracts had to compute those complex mathematical matrices or verify data sources; the gas fees alone could light your wallet on fire. The experience was even worse than a grocery shopping app. OpenLedger’s cleverness is that it doesn’t try to force a brand-new, high-bar underlying layer. Instead, it’s built on the OP Stack, and it hardcodes the most core data contribution and attribution algorithms directly into the node’s underlying code. It’s like back then you used a web page’s built-in calculator to do calculus—it was painfully slow. Now they’ve literally welded a hardware-accelerated chip onto the motherboard. That makes its claim of $OPEN token participation in micro-payments and high-frequency inference allocation feasible from an engineering standpoint, rather than leaving it as a fantasy inside a PPT.
Let’s also rant a bit about the projects out there that loudly claim “decentralized compute packages everything.” In reality, institutions that truly need highly specialized professional models (SLMs) would never hand their core business to decentralized home GPUs that might drop offline at any moment. The logic hinted at deep within OpenLedger’s whitepaper is essentially a separation between the OpenLoRA fine-tuning architecture running off-chain and the consensus on-chain. It doesn’t insist on completing all matrix computations on-chain; instead, it records on-chain the metadata that logs each data contribution.
This approach turns AI training from a previous black box into a ledger that can be audited at any time. Every developer who participates in fine-tuning and provides domain expertise can receive dividends attributed to them at the moment the model is called. Capturing these inference-driven needs at least ensures that the token consumption logic is grounded in reality.
Many project teams like to wrap their vision as if they’re about to send humanity to Mars, but in practice once they run the code, it’s all full of vulnerabilities. After watching enough bull-bear cycles, you’ll understand that Web3 doesn’t need to recreate an inefficient compute center. What it needs instead is to provide, for this gradually centralizing and monopolizing AI world, an immutable, transparent layer for interest settlement. $OPEN
This goes beyond simply distributed technology—more like a gentle refinement about how digital productivity should be allocated. When algorithms ultimately take over reality, the only thing we can use to fight against black boxes may be these lines of利益归因 (profit/benefit attribution) sealed into blocks.