I've been in the Web3 scene for almost a decade, seen all kinds of patchwork projects that raised millions based on just a few slides. Honestly, most of the so-called AI-driven L1s or middleware out there, when you peel back the fancy narrative, are just centralized APIs in disguise. We've been milked long enough by Web2 giants for behavioral data and original content, and now, in this so-called era of AI tokens, it's just a different place to keep playing the digital cash cow.
Until I recently dug into the white paper of @undefined , steering clear of the cookie-cutter marketing spiel, I noticed a previously overlooked technical detail: the Suffix-Array-Based Token Attribution mechanism.
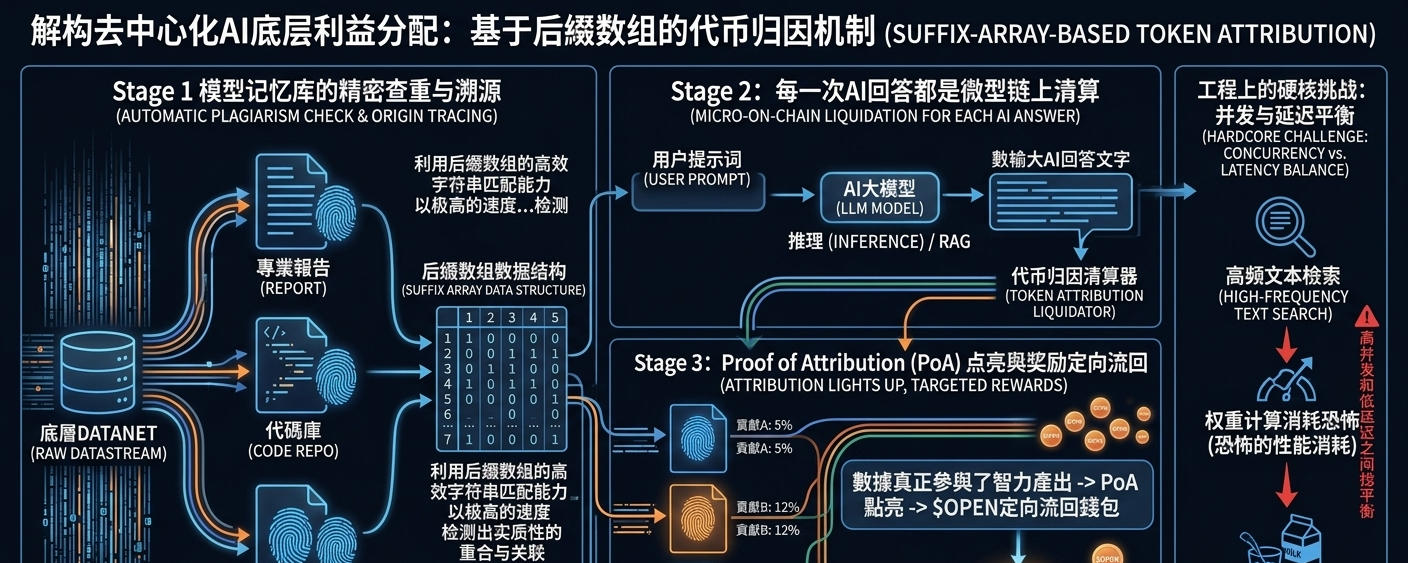
Many people are chatting#OpenLedger Everyone's buzzing about the data market and power crowdfunding, but those in the know understand that getting data onto the chain isn't the hard part; the tough question is, 'Why should I get a cut of this money?' Traditional machine learning is a massive black box—thousands of data points go in, churning out a model with billions of parameters. When a user inputs a prompt and the model delivers the perfect answer, how much of that answer can I attribute to the specialized report I uploaded yesterday? Traditional blockchain can’t really make sense of this fuzzy probability.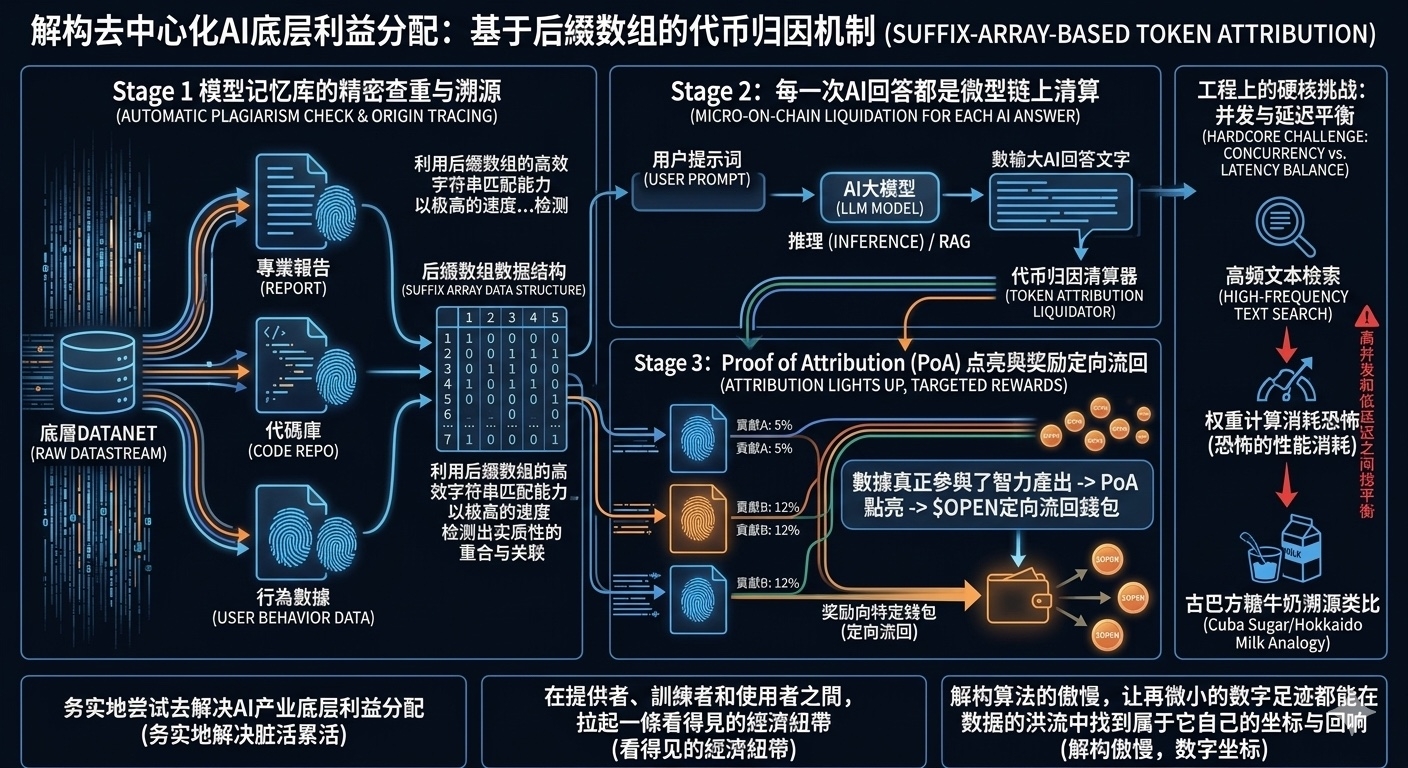
The suffix array attribution mentioned in the white paper is basically like giving the large model's memory bank a super precise 'automated deduplication and tracing.' It leverages the efficient string matching capabilities of suffix arrays to rapidly retrieve on-chain which original data fragments from the underlying Datanet have substantial overlaps and associations at the moment the model is inferring or enhancing retrieval.
This isn't like those past blind box schemes where you uploaded data and got a few tokens regardless of its usefulness. Now, every AI response becomes a micro, precise on-chain settlement. Your data is genuinely contributing to the current intellectual output; Proof of Attribution (PoA) lights up, and rewards flow back to your wallet.
As much as I complain, this design is hardcore from an engineering standpoint, but the friction it faces is quite evident. In actual operation, this high-frequency, complex text retrieval and weighting attribution is a massive drain on node performance. It's like every sip of bubble tea requiring the shop to instantly trace how many sugar cubes came from Cuba and how many milliliters of milk came from Hokkaido, then immediately pay the local farmers. This level of precision is fair in business logic, but balancing high concurrency and low latency in practical implementation is the tough nut the team will have to crack next.
I choose to take a look at $OPEN not because I’m brainwashed by those grand terms, but because amidst a market rife with speculation and shell games, at least someone is realistically trying to tackle the core, gritty issue of underlying interest distribution in the AI industry. It aims to create a visible economic link between data providers, model trainers, and end users.
From a higher-dimensional perspective, this attempt reflects a certain technical philosophical reflection. The knowledge base of human civilization is essentially a massive public asset built over thousands of years through countless individuals' unconscious collaboration. Now, centralized large models are trying to privatize this public asset using capital and computational power walls. The ultimate goal of decentralized AI shouldn't be to create a more centralized deity but, like this attribution mechanism, to deconstruct the arrogance of algorithms, allowing even the smallest digital footprint to find its own coordinates and echoes within the data flood.