
I started noticing something strange while using AI tools for research.
The answers looked polished.
The explanations sounded convincing.
But sometimes when I double-checked the details… parts of the information simply didn’t exist.Not intentionally wrong.Just confidently incorrect.
The more I read about how large language models work, the clearer it became. These systems don’t really “know” facts. They generate the most probable sequence of words based on patterns in training data. That process is powerful for creativity and reasoning, but it also creates two persistent problems in AI systems.
Hallucinations.
And bias.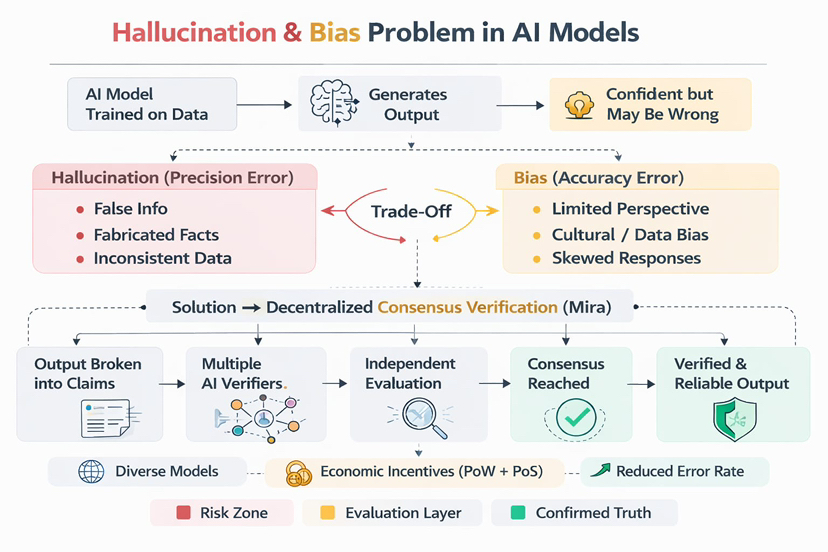
Hallucinations appear when the model confidently generates information that is false or fabricated. Bias appears when the model systematically leans toward certain perspectives or patterns embedded in its training data.
Trying to fix one often makes the other worse.
If developers reduce hallucinations by carefully filtering datasets, the model may become more biased because it learns from a narrower set of perspectives. If they widen the training data to reduce bias, hallucinations tend to increase because the knowledge base becomes more inconsistent.
It’s almost like a trade-off built into the architecture itself.
While reading about this problem recently, I came across the approach proposed by Mira.
Instead of trying to build a single perfect model, Mira treats reliability as a network problem rather than a model problem.
That shift in thinking immediately stood out to me.
The system works by taking AI-generated outputs and breaking them into smaller verifiable claims. Each claim is then evaluated by multiple independent AI verifiers operating within the network.
Rather than trusting one model’s reasoning, the system relies on collective verification.
Different models check the same claim.
Different perspectives analyze it.
If enough validators agree, the claim is considered reliable.
What makes the system interesting is that this process happens inside a decentralized infrastructure secured through economic incentives. Node operators performing verification tasks are rewarded for honest participation through mechanisms combining Proof-of-Work style computation and Proof-of-Stake style commitment.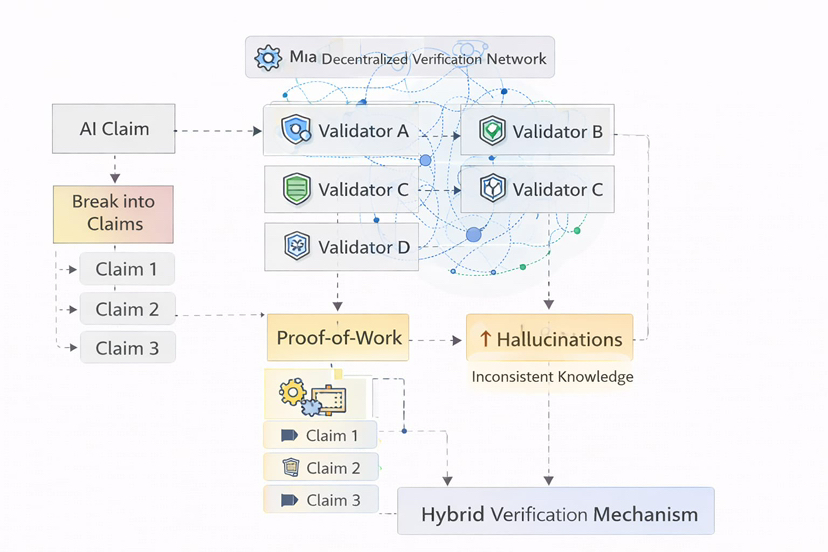
This means validators are economically motivated to provide accurate verification rather than manipulated outputs.
In a way, the system treats information like a blockchain transaction.
Not accepted because one entity says it’s true…but because a network reaches consensus.
Another part that caught my attention is how this structure could encourage diversity among AI models. Instead of relying on one dominant model architecture, the network benefits from having different specialized models participating as verifiers.
Some might be better at scientific reasoning.Others might specialize in historical knowledge or regional context.
Together they create something closer to collective intelligence than isolated machine reasoning.
When thinking about the future of autonomous AI systems, this idea becomes even more relevant. If AI is expected to operate without constant human supervision — managing infrastructure, coordinating robotics, or assisting scientific research — reliability becomes critical.
A single hallucinated output could trigger real-world consequences.But if every claim passes through a decentralized verification layer first, the risk becomes much smaller.
What I find interesting about Mira is that it doesn’t promise perfect AI.
Instead, it tries to build a system that detects and filters errors before they matter.The AI industry today is mostly focused on building bigger models with more parameters and more training data.
But sometimes the real breakthrough isn’t making the machine smarter.Sometimes it’s building systems that make intelligence trustworthy.
@Mira - Trust Layer of AI #Mira $MIRA
