Not the boring “admin access” kind. The deeper kind—who gets to use what, under which conditions, and how you can tell if those conditions were actually followed.
Because robotics isn’t just building a robot. It’s building a chain of permissions that stretches across data, compute, and real-world action. And that chain is usually held together by informal trust until something goes wrong.
You can usually tell when permissions are the weak point because the questions people ask start sounding the same.
“Are we allowed to use this dataset for this?”
“Can this agent call that tool in production?”
“Who approved this model update?”
“Is this robot allowed to do this action without a person watching?”
These are not edge cases. They’re the everyday friction of deploying systems that can act in the world.
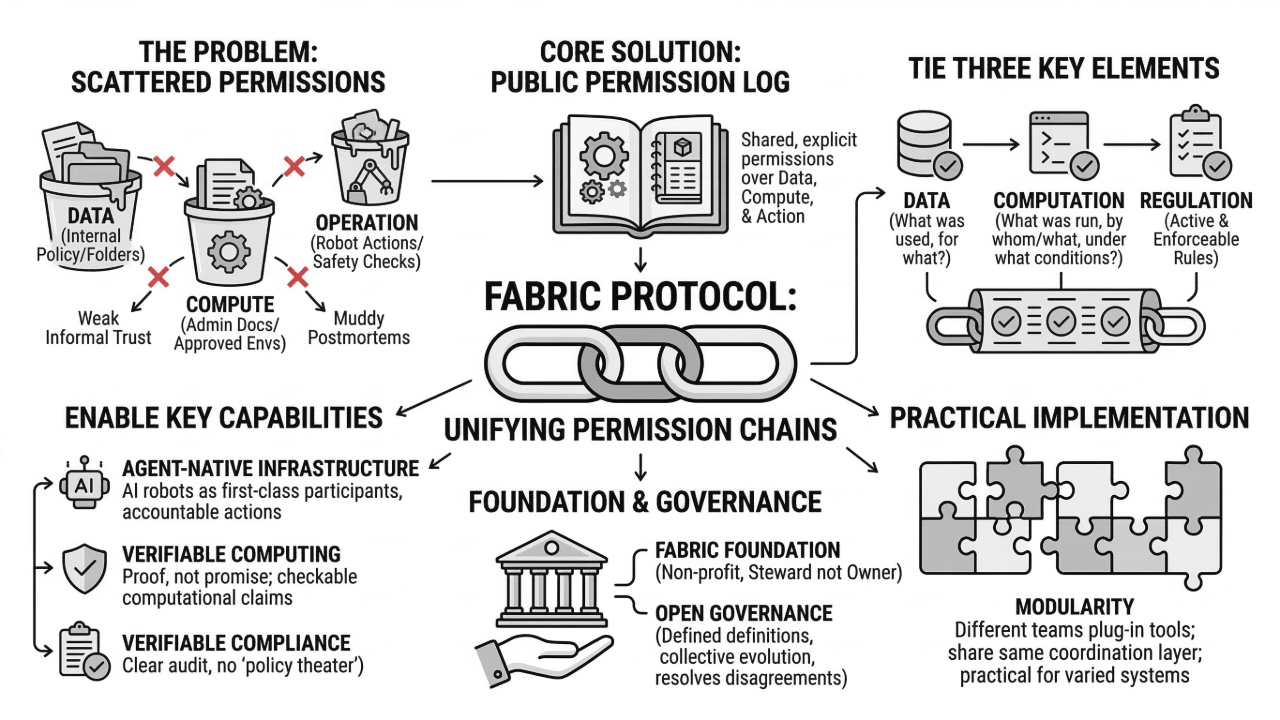
@Fabric Foundation Protocol is described as a global open network supported by the non-profit Fabric Foundation, enabling the construction, governance, and collaborative evolution of general-purpose robots. It coordinates data, computation, and regulation through a public ledger, using verifiable computing and agent-native infrastructure. I read that as an attempt to make permission chains explicit instead of implied.
Because right now, permission is often handled in scattered ways.
Data permissions live in one place—maybe a data governance doc, maybe an internal policy, maybe a folder with restricted access. Compute permissions live somewhere else—who can run training jobs, who can deploy models, which environments are “approved.” And operational permissions live in the final system—what actions the robot can execute, what it needs confirmation for, what safety checks must run.
The problem is that these permissions don’t naturally link together. So you can end up in situations where the robot is technically doing something “allowed,” but the chain behind it doesn’t add up. Like, the model was trained using data that wasn’t meant for deployment. Or an agent has the ability to deploy, but the evaluation it relies on wasn’t run under the right constraints. Or rules exist in theory, but the enforcement layer is optional.
That’s where Fabric’s public ledger idea becomes interesting. A ledger can act like a shared permission log. Not just “this happened,” but “this happened under these constraints, with these approvals, using these inputs.”
It’s basically a way to tie together three things that are often separate:
Data: what was used, and what it was allowed to be used for
Computation: what was run, by whom (human or agent), under which conditions
Regulation: what rules were active and enforceable at the time
When those are linked, permissions stop being a vague promise and start being something you can audit.
That’s where “verifiable computing” fits naturally. Permission is only meaningful if you can verify compliance. Otherwise it’s just policy theater. Verifiable computing suggests that Fabric wants key computational claims to be checkable. Not every detail, but enough to confirm that an evaluation actually happened, that a training run used the dataset it claims, or that an agent’s output came from approved steps.
You can usually tell the difference between “we follow rules” and “we can prove we followed rules” when something breaks and people need to do a postmortem. If you can’t verify, you end up with arguments and guesswork. If you can verify, you at least have a shared starting point.
The “agent-native infrastructure” part matters here because agents complicate permission in a new way. Agents don’t just suggest actions. They can initiate processes. They can request compute, move data, run evaluations, and sometimes even trigger deployments. So now permission isn’t just “which humans can do what.” It’s “which agents can do what,” under what constraints, and with what record.
If you don’t make that explicit, you get odd outcomes. Agents end up with broad privileges because it’s convenient. Or their actions aren’t recorded cleanly. Or people rely on “the agent is supposed to follow the rules” without having a way to confirm it did.
Fabric seems to be designed to avoid that drift. If agents are first-class participants, they also need first-class accountability. Identity, permissions, traceable actions, verifiable records. Otherwise the system becomes harder to trust as it scales.
Governance is the last layer of permission, really. Who gets to define the rules? Who changes them? How do upgrades happen? How do you resolve disagreements when different groups want different safety boundaries or different standards?
A foundation-backed protocol doesn’t solve governance, but it changes the tone. It suggests stewardship rather than ownership, which matters when you’re trying to build an open network that people will rely on for high-stakes systems.
And modularity ties it together in a practical way. Permission systems fail when they require everyone to use the same stack. In robotics, that’s not realistic. So a modular approach means different teams can plug into the protocol while keeping their own tools, as long as they can still express permissions and constraints in the shared coordination layer.
So from this angle, Fabric Protocol isn’t about making robots more capable in some headline sense. It’s about making the whole chain of permission—data → compute → action—clear enough that collaboration doesn’t depend on informal trust.
And that’s a quieter goal. But it’s the kind of goal you start valuing once you’ve seen how quickly things get muddy when robots move from “our lab’s project” to “a shared system that keeps changing.” And once it gets muddy, it rarely clears on its own.
Article
For some reason, I keep thinking about Fabric Protocol mostly in terms of permission.