The moment Fabric Protocol stopped looking simple to me was when I stopped reading it as a robot story and started reading it as a rule story. I was sitting with the verification side of it, the validator monitoring, the challenge-based enforcement, the uptime and quality thresholds, and one thought kept getting louder. Fabric Protocol may say it wants general-purpose robots, but its early economics may reward the most predictable robots first.
That is not because the protocol is weak. It is because the protocol is trying to be serious.
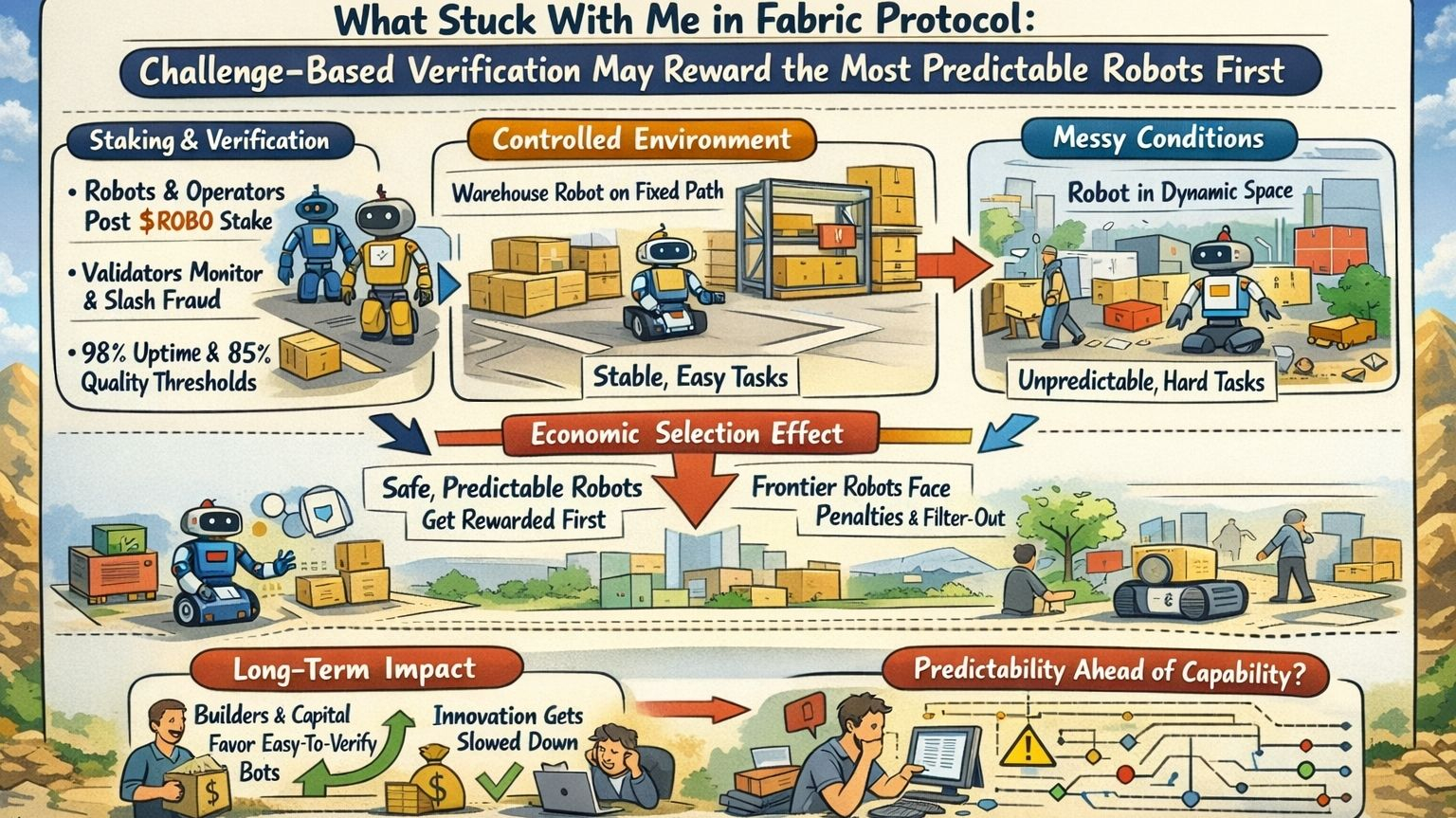
Fabric is built to make robot work legible enough to price, verify, and punish. Robots and operators post stake. Validators monitor performance. Proven fraud can be slashed. Public discussion around Fabric has also pointed to penalties below roughly 98 percent availability and suspension below roughly 85 percent quality. I understand the logic. If real machine work is going to touch money, logistics, access, or physical environments, the network cannot run on vibes. It needs rules. It needs thresholds. It needs consequences. That is the whole point of bringing $ROBO, validators, and challenge-based verification into the loop.
But the minute you do that, you are not just measuring behavior. You are selecting for a kind of behavior.
That is the part I think the market is reading too simply. A robot repeating a narrow task in a highly controlled environment has a much easier path to clean uptime and stable quality than a robot working in noisy, mixed, shifting conditions. Put one machine on a tightly mapped warehouse route with known handoff points and low human interference. Put another in a more dynamic space where layouts drift, people improvise, objects appear in the wrong place, and exceptions pile up faster than simulation promised. Which one is more likely to stay above a hard threshold early? The answer is obvious. It is also important.
The cleanest robot is not automatically the most important robot.
That is why I think Fabric’s rule surface can become a market filter. Validators do not just observe performance. Their presence helps define what performance is worth backing with stake, what performance is cheap enough to defend, and what performance looks too noisy to scale. Once availability and quality floors matter economically, operators will optimize toward the deployments most likely to survive them. Capital will do the same. So will developer attention. The result is subtle, but powerful. The protocol can start steering the robot economy toward narrow predictability long before it proves broad capability.
A good rulebook can still be conservative.
I do not mean conservative in the political sense. I mean economically conservative. If a network is serious about slashing, dispute resolution, and quality enforcement, it will naturally be friendlier to machines working in environments where error is easier to bound, performance is easier to measure, and edge cases are easier to avoid. That is rational. It is also a problem if the story around the protocol is bigger than that. Because general-purpose robotics does not begin in neat zones. It begins in mess. More interruptions. More ambiguity. More state drift. More borderline cases that lower clean metrics before they produce real learning.
So the bullish reading needs pressure. People hear stricter verification and assume that means the network is accelerating the right kind of robot economy. Sometimes it does. Sometimes it is only accelerating the easiest kind. That difference matters. Fabric can absolutely improve trust, discipline, and accountability with its validator layer and $ROBO-linked enforcement. But if those same mechanics make frontier deployments economically harder to sustain, then the network may scale reliable narrow work first and call it progress toward something broader.
That would not be fake progress. Just narrower progress than people think.
The second-order effect is where this gets more serious. Once operators learn that predictable task classes survive challenge-based verification with less pain, they will choose those tasks more often. Once developers see which robots clear the quality floor most easily, they will build for those conditions. Once validators get used to certain kinds of measurable performance, the whole network starts to normalize that profile as the safe center of activity. None of this requires a conspiracy. It only requires incentives. That is enough to shape the early robot economy in a direction that looks disciplined on paper and selective in practice.
What is safest to verify is not always what matters most to scale.
The falsifiable part is clean. If Fabric Protocol can keep strong validator oversight, preserve hard uptime and quality discipline, and still leave real room for messier, edge-heavy, less-controlled deployments to participate without being economically filtered out, then this concern weakens. If the network can distinguish between bad operators and simply harder environments, then the rulebook is doing more than protecting order. It is protecting growth. But I would not assume that outcome just because the thresholds sound rigorous.
The more I look at Fabric, the more I think the real question is not whether it can verify robot work. It is whether its verification economics can reward ambitious capability without forcing everything to behave like factory-grade predictability. If the answer is no, Fabric Protocol will still scale robots. It just may reward the safest ones first, and mistake that for the whole future.
@Fabric Foundation $ROBO #robo
