One night, the automation queue for Fabric Foundation looked perfectly fine. Jobs were moving, workers were breathing, and the dashboard was green. No alerts. No fires.
But there was this one task that just wouldn't stay finished. It kept sliding back into the queue.
It wasn’t failing, exactly. It just kept retrying.
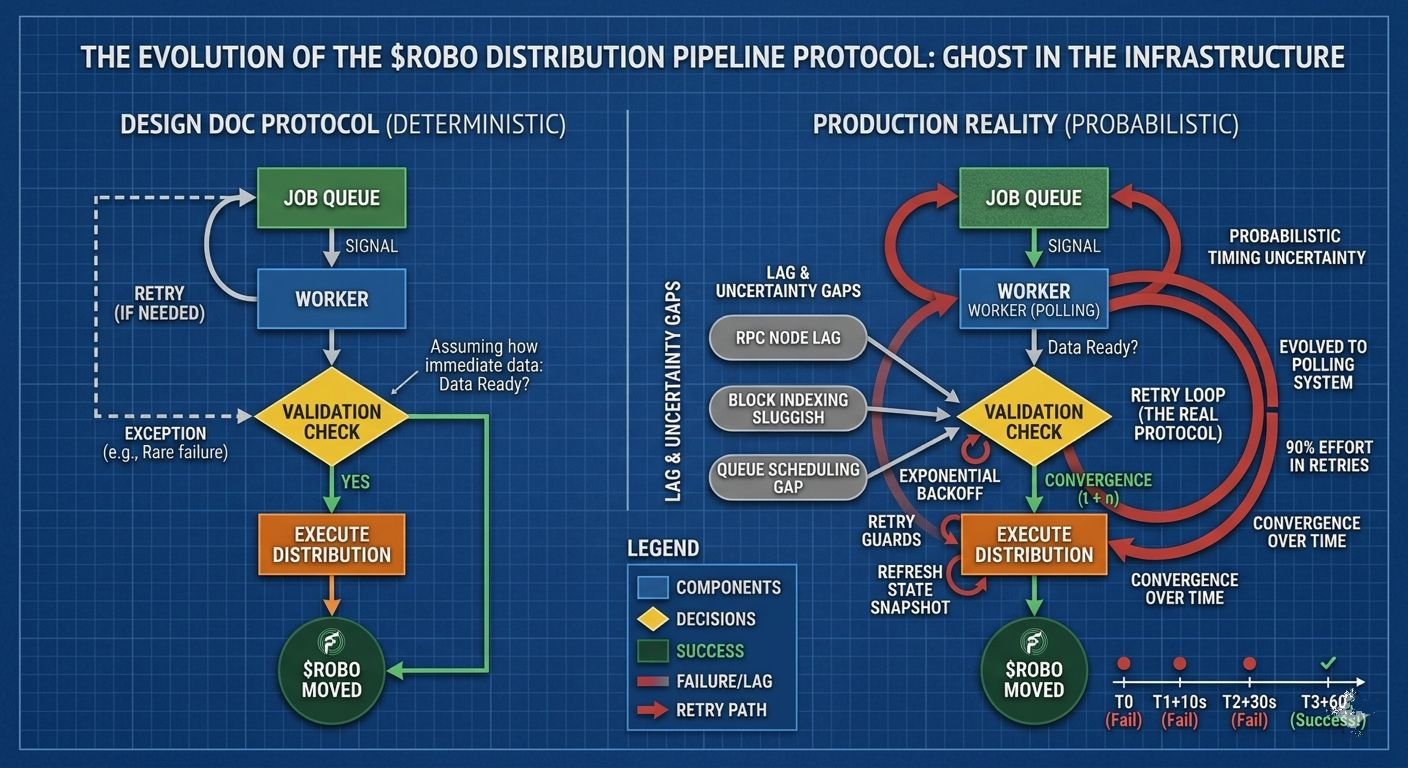
The job was a simple piece of the $ROBO distribution pipeline. The logic was as basic as it gets: a worker checks a confirmation state, validates it against a specific block height, and moves on if everything matches. Standard stuff.
In the design docs, the assumption was easy: if the data isn’t there, retry once or twice until it is. But production has a habit of eating design docs for breakfast.
In the real world, that worker wasn’t retrying twice. It was retrying dozens of times.
It wasn’t because the code was broken—it was because the data was always just a few seconds late. RPC nodes lagged. Queue scheduling added tiny gaps. Block indexing was occasionally sluggish. None of these were "bugs" on their own, but together, they created this weird, stuttering rhythm.
The worker would check. Not ready. Retry. By the second or third attempt, the data had finally caught up.
At first, we didn't think much of it. The system was self-healing. Retries were doing their job. But after a few months, the metrics started telling a different story. Retry traffic wasn't just there; it was growing. Quietly.
Eventually, almost every single task relied on a retry cycle. Sometimes five. Retries weren't the exception anymore—they were the baseline.
And that’s the uncomfortable part. When retries become normal, the system starts to depend on them. The original logic assumed the data would be there when the worker arrived. Reality disagreed. Without us even realizing it, our verification worker had turned into a glorified polling system.
We tried all the "obvious" fixes. We increased delays so we wouldn't hammer the RPCs. We added retry guards and exponential backoffs when the queue started to backlog. We built watcher jobs to refresh state snapshots and pipelines to rebuild stale caches. We added alerts and manual procedures for when the queues got "weird."
Each fix was small. None of them changed the protocol logic. But slowly, these operational patches became the actual system.
The pipeline wasn't just executing an event anymore; it was navigating a maze of delays, refreshes, and "eventual" readiness. We had to admit something: the protocol for $ROBO distribution was written as a series of deterministic steps, but in production, it was entirely probabilistic.
The workers didn't expect the system to be ready. They just expected it to become ready, eventually.
The retry loop had quietly moved from a "safety net" to a core part of the protocol. It wasn’t documented or designed that way, but the system couldn't run without it.
It changes the way you think about distributed automation. You aren’t really coordinating tasks anymore—you’re coordinating timing uncertainty. Every retry is an admission that the network, the queue, and the data are all out of sync.
Retries smooth that out. They give the system time to catch up with itself. But they also hide the fact that the machine rarely works the way it was intended to.
After months of running this infrastructure, the pattern is clear. Protocols describe the dream, but operations describe the reality. In Fabric Foundation, the thing actually keeping $ROBO moving isn't the smart contracts or the scripts.
It’s the retry behavior sitting quietly in the gaps. The system works, but definitely not for the reasons we originally wrote down.
$ROBO @Fabric Foundation #ROBO