I keep circling back to a simple, slightly uncomfortable question:
why does interacting with a regulated system still feel like I’m giving away more than I should, just to do something ordinary?
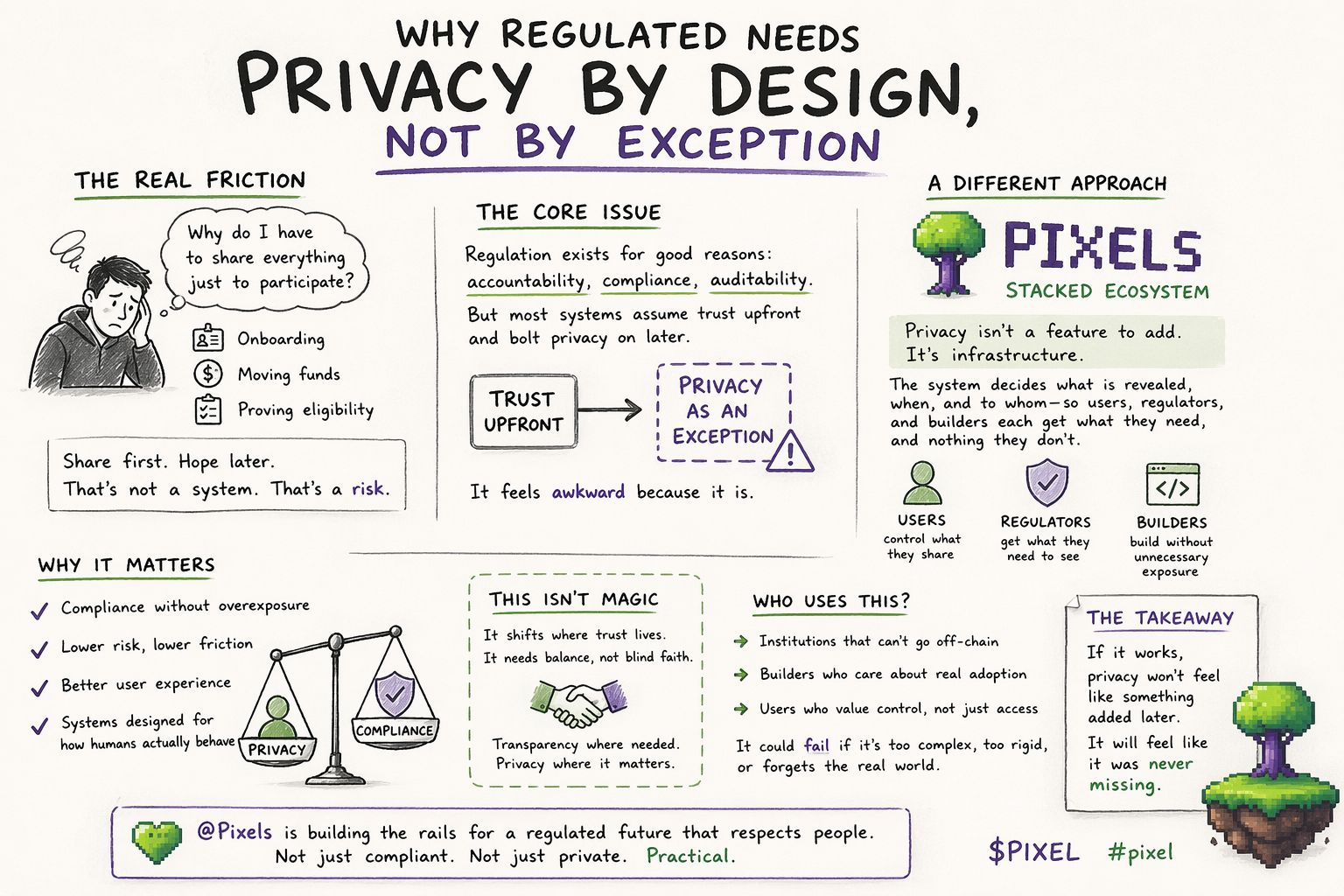
It happens everywhere. Opening an account. Moving funds. Proving eligibility for something small. The process is rarely confusing from a technical standpoint it works but it feels disproportionate. The system asks for everything upfront, even when the action itself is minor. And once that pattern becomes normal, nobody really questions it anymore.
Regulation isn’t the issue. It exists because it has to. Without it, there’s no shared baseline for trust, no enforceable accountability, no clear way to resolve disputes. The problem is how regulation gets translated into systems. Most implementations assume that the safest approach is to collect as much data as possible, store it, and then decide later what to do with it.
That’s where things start to feel off.
Because in practice, this creates a strange imbalance. Users are expected to trust the system immediately, while the system itself doesn’t really trust the user until everything is verified. It’s a one-sided arrangement. Privacy ends up becoming something optional—something that can be added later, patched in, or limited through policy. Not something foundational.
And you can feel that. Systems designed this way often feel heavy, slow, and slightly invasive. Not broken, just… misaligned.
What’s interesting about the direction Pixels is exploring with its Stacked ecosystem is that it seems to treat this as a design flaw, not a feature gap. It’s not trying to make privacy “better” within the same structure. It’s questioning whether the structure itself is wrong.
If different participants users, regulators, builders need different levels of information, then why is the default still “show everything, then restrict”?
Why not reverse that?
That’s where the idea of privacy by design starts to feel less like a principle and more like a practical necessity.
But it also raises another question: how do you actually build something like that without making it too complex to use or too rigid to adapt?
This is where thinking in versions helps.
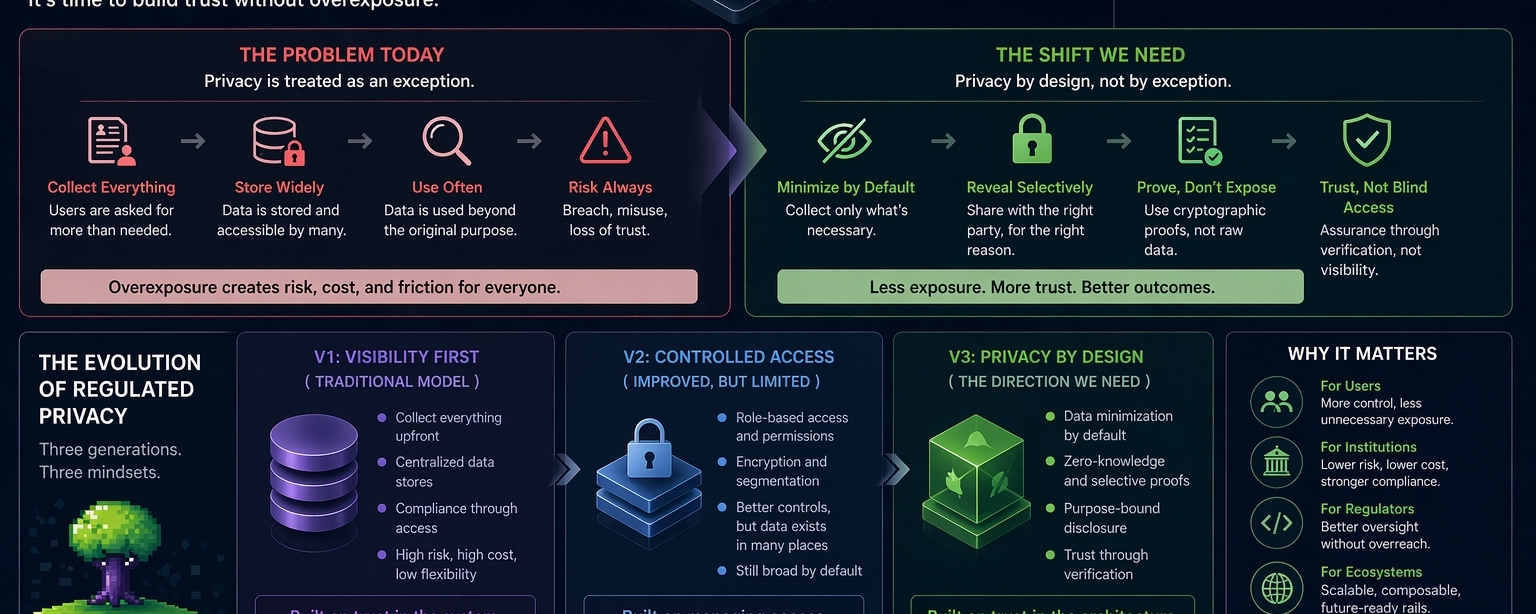
If you look at how most regulated systems behave today, they resemble what you might call a “v1” model. In v1, the priority is control through visibility. Collect everything, verify everything, store everything. Compliance is achieved by having access to complete information at all times. It’s straightforward, and in some ways, reassuring. But it comes with obvious costs: data risk, operational overhead, slower processes, and a user experience that often feels intrusive.
Then you start seeing something like a “v2” approach emerge. Here, systems begin to recognize that overexposure is a problem. So they introduce layers permissions, encryption, limited disclosures. Privacy becomes something that is managed more carefully. But it’s still not native. It’s more like an overlay on top of the original structure. The system is still fundamentally built around collecting data first and organizing it later.
That helps, but it doesn’t fully solve the issue. Because the underlying assumption hasn’t changed.
A “v3” model would look different. Not because it adds more features, but because it changes the starting point. Instead of assuming full visibility, it assumes minimal disclosure. Data isn’t broadly collected and then restricted—it’s selectively revealed when needed, to the appropriate party, for a specific purpose.
That sounds cleaner in theory. In practice, it’s harder.
Because now you’re not just dealing with technical design. You’re dealing with legal expectations, audit requirements, settlement processes, and human behavior. Regulators still need assurance. Institutions still need risk management. Users still want simplicity. Builders still need something they can actually implement without breaking everything else.
So the question becomes: can a system balance all of that without collapsing under its own complexity?
That’s where the idea of treating this as infrastructure not a product starts to make sense.
If the underlying system can define how data flows, how permissions are enforced, and how proofs are generated without exposing raw information, then maybe each participant doesn’t have to solve the problem independently. Maybe the system itself becomes the place where trust is coordinated.
But that also shifts responsibility. If trust moves into infrastructure, then the infrastructure has to be reliable, adaptable, and understandable. Otherwise, you’re just replacing one opaque system with another.
And that’s where skepticism is still warranted.
Because there are a few obvious ways this could fail.
It could become too complex for real-world use. Builders might avoid it if integration feels heavy or unclear. Institutions might hesitate if it doesn’t map cleanly to existing compliance frameworks. Regulators might resist if visibility feels too abstract or indirect.
Or it could become too rigid. Regulation evolves. Edge cases appear. If the system can’t adapt without major changes, it risks becoming obsolete in the same way older systems are today.
There’s also the risk of centralization creeping back in. Even a well-designed privacy system can lose its integrity if control ends up concentrated in a few hands. At that point, the structure might look different, but the outcomes feel familiar.
Still, the alternative isn’t particularly attractive either.
Continuing with systems that treat privacy as an afterthought means carrying forward the same inefficiencies, the same risks, and the same user friction. It works, but it doesn’t improve.
So maybe the real value in what Pixels is building with the Stacked ecosystem isn’t that it has solved these problems already. It’s that it’s approaching them from a different angle one that assumes the current model isn’t good enough.
And that matters more than it sounds.
Because systems rarely change unless the assumptions behind them change first.
In terms of who would actually use something like this, it’s probably not everyone. At least not immediately. The most likely adopters are environments where compliance is unavoidable, but efficiency still matters financial platforms, onchain identity layers, systems where settlement and verification happen frequently and at scale.
For users, the benefit would be subtle. Less friction, fewer unnecessary disclosures, a sense that participation doesn’t require constant overexposure. For institutions, it could mean lower operational costs and reduced data risk. For regulators, it might offer more precise oversight without needing full access to everything.
But all of that depends on execution.
If it works, it won’t feel revolutionary. It will feel normal. Like something that should have been designed that way from the beginning.
If it fails, it will likely fail quietly too complex, too early, or too disconnected from how systems actually operate today.
Either way, the direction is worth paying attention to.
Because privacy by design isn’t just about protecting data. It’s about aligning systems with how trust actually works in the real world.
And right now, most systems still haven’t figured that out.