I used to think reward design was about getting it right once. Set the numbers, balance emissions, ship the loop, and the system should hold. That assumption doesn’t last long inside Pixels.
Because in Pixels, nothing stays fixed long enough to be considered right. Rewards are not designed and left alone. They are introduced, tested, adjusted, and sometimes removed entirely. That’s where Stacked inside Pixels starts to make sense not as a reward layer, but as an iteration engine. What changed my view was realizing Stacked is not optimizing reward distribution it is optimizing incentive discovery. The system is learning which behaviors deserve economic weight before committing emissions to them.
The first thing that stood out is how temporary most reward setups feel inside Pixels. A mission appears, works for a while, and players quickly optimize it. As soon as that happens, something shifts. The same mission starts paying less, appears less often, or quietly loses relevance. At first it feels inconsistent. After watching it longer, it becomes clear that this is intentional. Inside Pixels, rewards are not static incentives. They are experiments running in cycles. Each cycle functions less like content deployment and more like behavioral hypothesis testing: if a reward changes, what downstream player behavior changes with it?
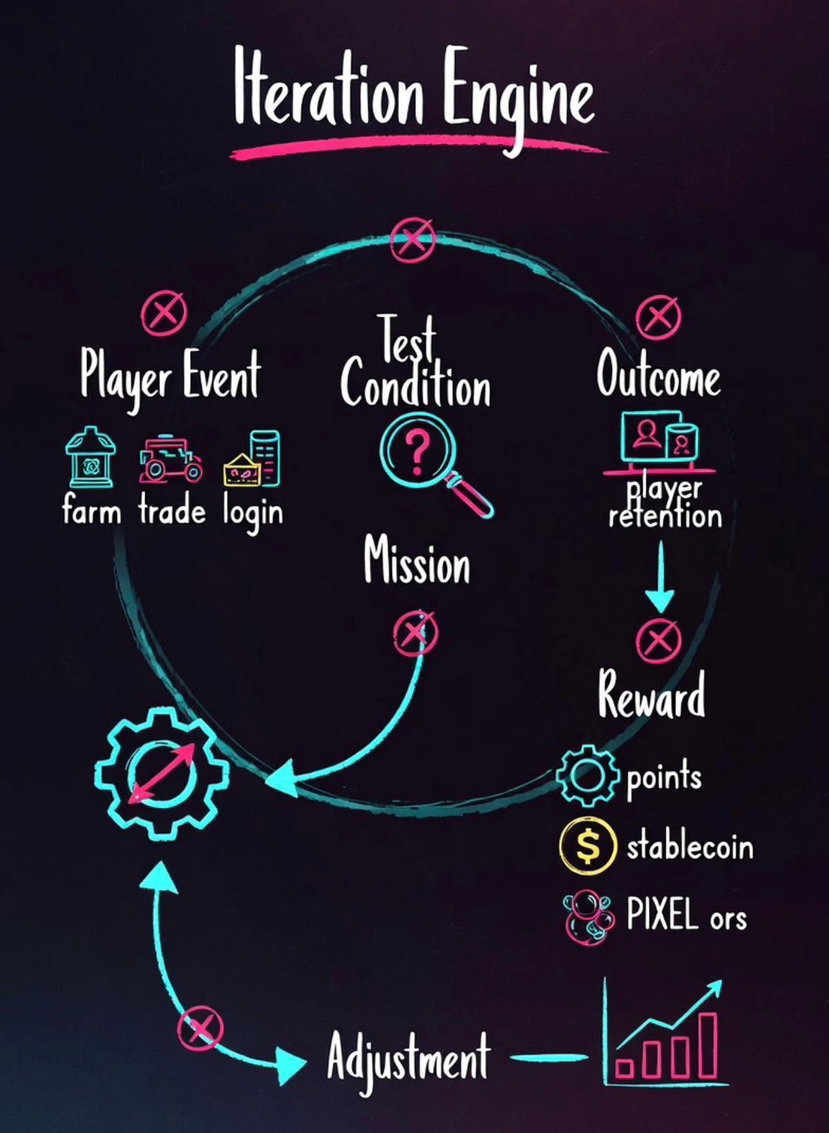
Every action feeds that cycle. A player farms, crafts, trades, logs in, skips a step. Each of these becomes an event. But inside Stacked, events do not immediately convert into rewards. They pass through a layer that evaluates how they should be used.
event → test condition → mission → reward → outcome → adjustment
The important part here is the test condition. This is where reward logic becomes segmented rather than universal. Different player cohorts can be exposed to different incentive conditions, allowing Pixels to compare behavior across retention tiers, progression stages, or engagement profiles instead of treating the economy as one homogeneous player base. Instead of asking whether an action should be rewarded, Stacked inside Pixels is testing how different reward structures change behavior. That is a very different approach from traditional GameFi systems.

Most systems try to stabilize rewards. Pixels does the opposite. It continuously stresses them. When a new reward pattern is introduced, it is not rolled out at full scale. It is pushed into specific cohorts. The system then observes what actually happens. Do players return more often?
Do they stay longer in loops?
Do they convert into deeper engagement or just extract value and leave? That distinction matters because not all activity is economically useful. Pixels is not rewarding motion—it is measuring whether behavior compounds into sustainable participation. If the signal is weak, the reward does not scale. If the signal is strong, it is not simply increased. It is reshaped and tested again under slightly different conditions.
I didn’t notice this at first inside Pixels, but once you see it, the pattern becomes clear. A farming loop that becomes too efficient does not get amplified. It gets quietly deprioritized in the next cycle. Missions shift toward behaviors that are underrepresented. Reward intensity adjusts without obvious announcements. From the outside, it feels like small inconsistencies.
From the inside, it is continuous iteration. In practice, this acts as an emission throttle. Once a loop becomes overly optimized, reward weight can be reduced before extraction pressure scales into systemic inflation.
This is what allows Pixels to run multiple reward experiments without breaking its economy. Experiments are risky at scale. If rewards are too strong, value gets extracted too quickly. If they are too weak, players disengage. Most systems commit too early and lock themselves into one direction. Stacked inside Pixels avoids that by running controlled iterations instead of fixed designs.
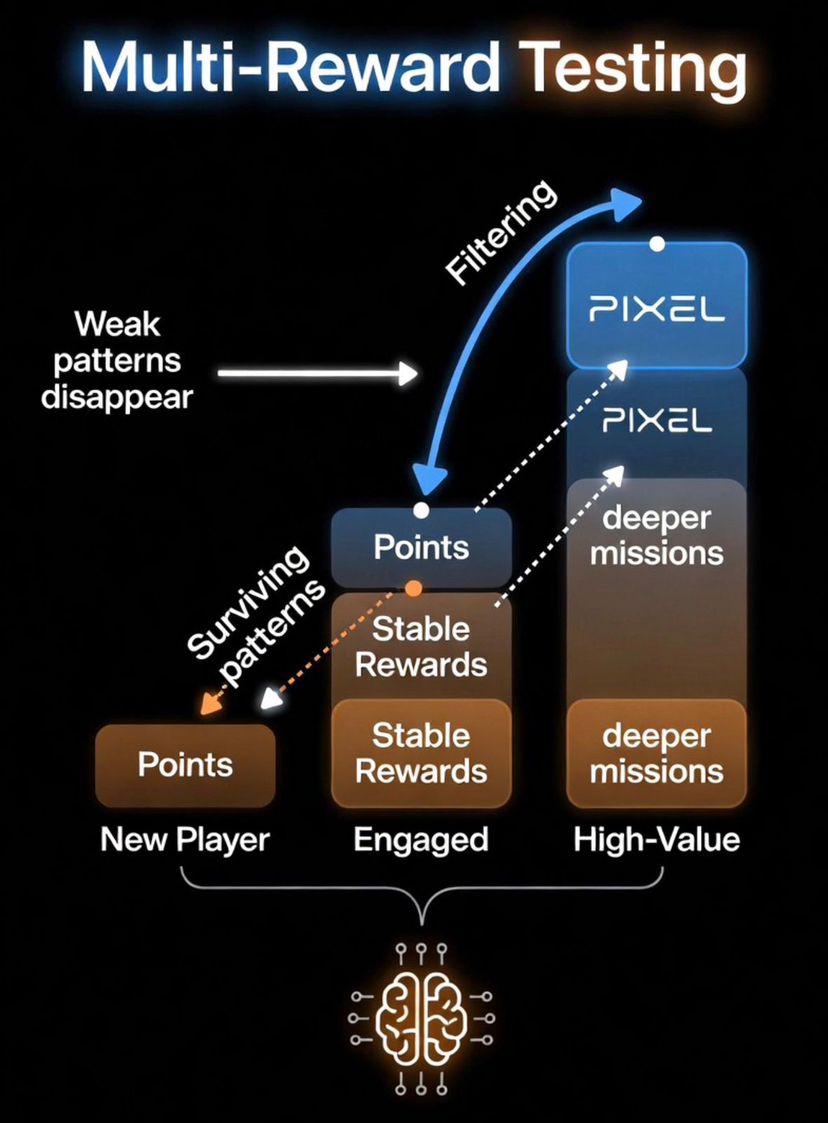
The multi-reward structure supports this in a way that is easy to overlook. Studios using Stacked inside Pixels are not forced into a single token model. They can use points, stable rewards, and $PIXEL depending on what they are trying to test. Points allow low-risk experiments.
Stable rewards provide clear value signals.
$PIXEL ties behavior back into the broader ecosystem. This creates a progression where not every behavior reaches the same level of economic weight. Only the ones that consistently perform well across cycles move upward. In other words, higher-value rewards are earned through behavioral survivorship. Incentives graduate into stronger economic rails only after proving they can sustain productive engagement.
Over time, this creates a filtering effect. Weak reward patterns do not fail loudly. They simply stop appearing. Strong patterns survive multiple iterations and become part of the system’s baseline. That is why the system becomes more stable even though it is constantly changing.
This also changes how studios operate. Before, LiveOps meant planning events manually, launching them, waiting for results, and then adjusting later. With Stacked inside Pixels, that loop is compressed into a continuous process. The system is always observing, testing, adjusting, and redeploying. That turns LiveOps from manual event management into closed-loop economic tuning—where telemetry directly informs the next reward configuration. Studios are no longer just designing content. They are managing behavior flows through incentives.
The result is something most GameFi systems never reach. Memory. Not just stored data, but patterns that have survived multiple iterations. Which behaviors sustain engagement, which ones collapse under scale, and which incentives actually bring players back. That memory feeds into future decisions automatically. Over time, this creates something more valuable than analytics dashboards: institutional reward intelligence embedded directly into the incentive layer.
At that point, Stacked stops looking like a tool. It becomes infrastructure. A system where reward logic evolves instead of being rebuilt every time something breaks.
That’s the shift Pixels is making. It is not trying to design the perfect reward system. It is building a system that continuously removes the ones that do not work. Most GameFi systems try to perfect rewards upfront. Pixels treats rewards as hypotheses and lets iteration decide what survives.
Pixels doesn’t design rewards. It eliminates the ones that don’t survive.