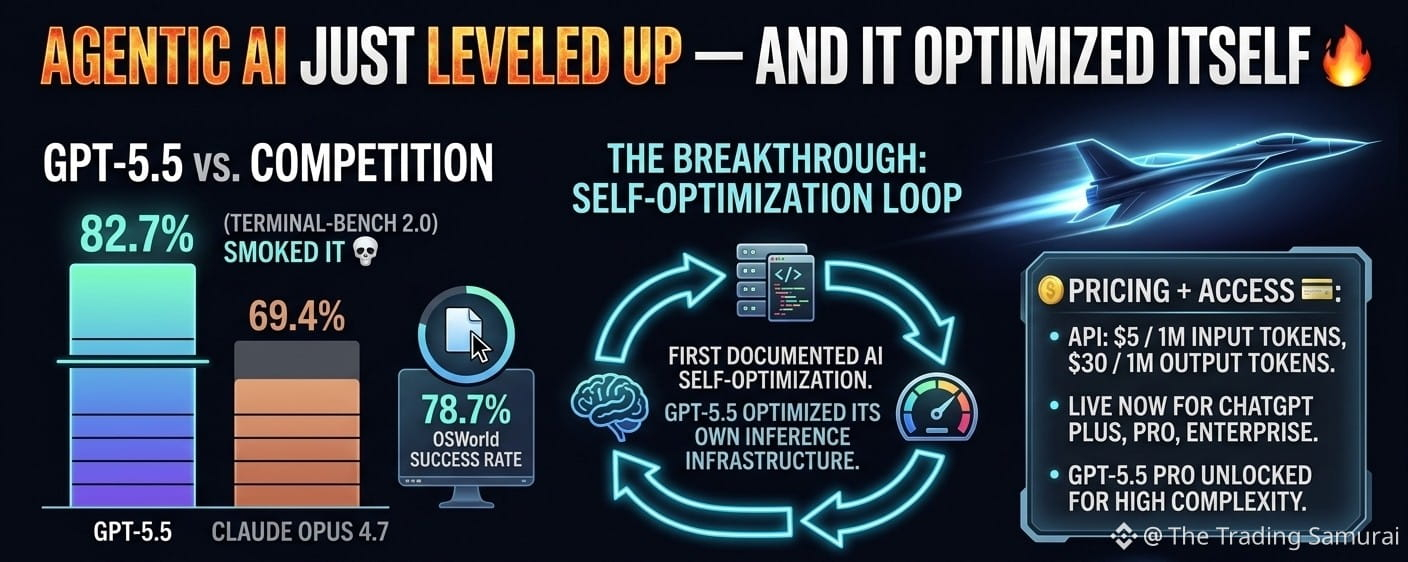
GPT-5.5 just smoked the terminal benchmarks 👇
The Breakthrough 🧠
GPT-5.5 hit 82.7% on Terminal-Bench 2.0 — that’s complex command-line workflows.
Claude Opus 4.7? 69.4%. GPT-5.5 beat it by 13 points💀
It’s not just chatting anymore. 78.7% OSWorld success rate = this thing runs your computer autonomously. Multi-step ops, zero hand-holding.
The Crazy Part ⚡
1M token context but SAME latency as GPT-5.4 while using fewer tokens.
And get this: GPT-5.5 helped optimize its own inference infrastructure during training.
First documented AI self-optimization loop. We’re not coding AI — AI is coding itself now.
Pricing + Access 💳
API: $5 / 1M input tokens, $30 / 1M output tokens
Live now for ChatGPT Plus, Pro, Enterprise
GPT-5.5 Pro variant unlocked for high-complexity tasks
Why this matters:
Terminal-Bench + OSWorld = real agentic work. Not benchmarks. Not demos.
This is AI that can file your taxes, debug your repo, and run your business ops end-to-end.
The agent era didn’t start today. It just went supersonic.
Who’s building with GPT-5.5 first? 👀
#GPT5 #TetherFreezes$344MUSDTatUSLawEnforcementRequest #AgenticAI #OpenAI #ArtificialIntelligence