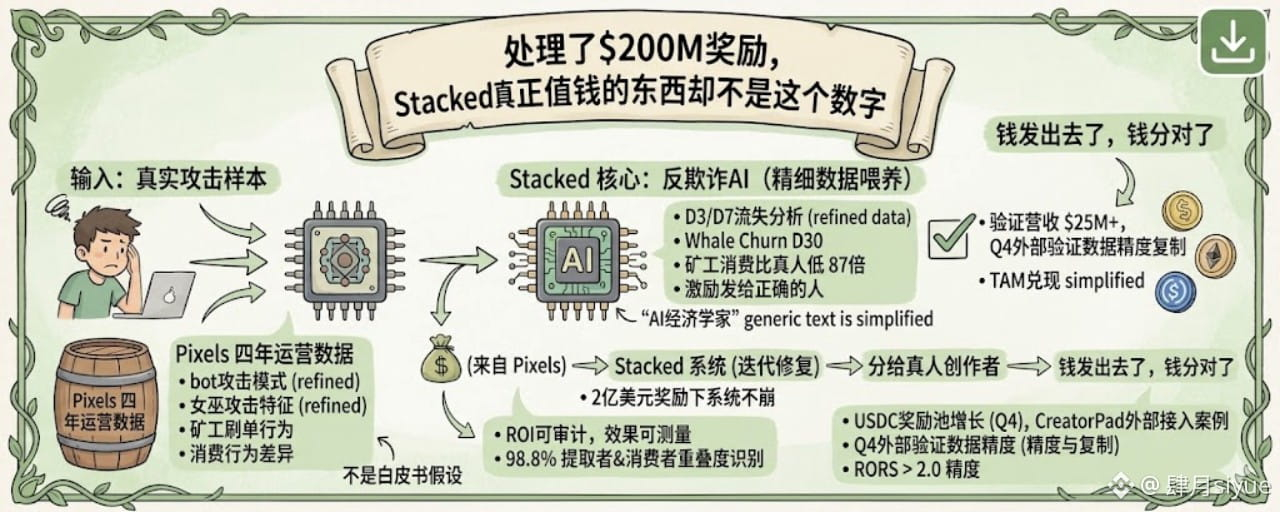

The first time I saw Stacked's "historical cumulative processing of $200 million in rewards," I thought the key was the scale: lots of users, high volume.
Later, I took a different angle on that number: $200 million, how much was actually distributed, and to whom?
The reward systems in Web3 games have a common issue: it's not that they can't distribute funds, but that the money doesn't reach the right players. Bots farm, studios claim in bulk, while real players miss out. This isn't uncommon; every P2E project that reaches a certain scale faces this challenge. The result? The numbers look good, but the distribution is a mess.
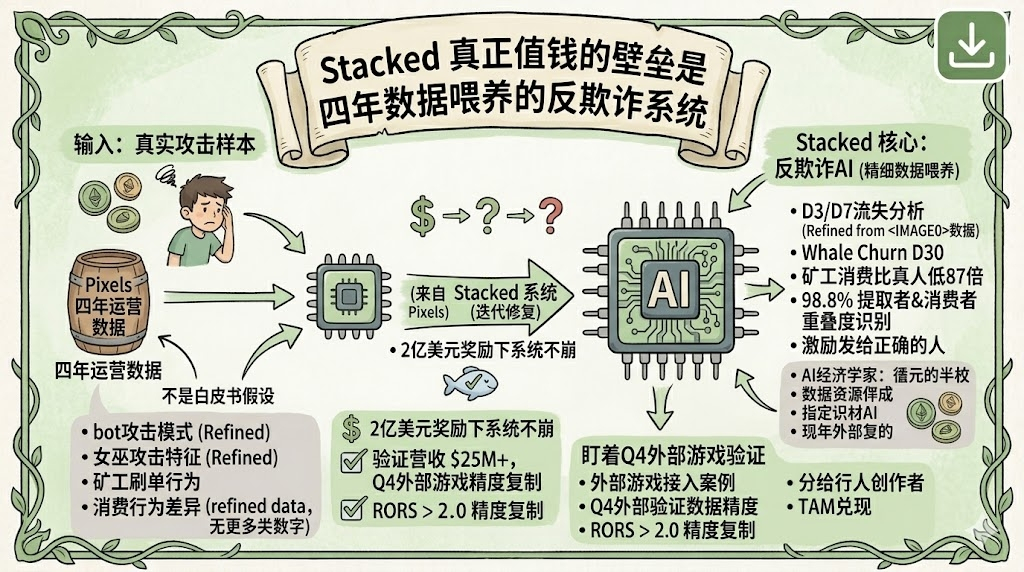
Stacked claims to use AI to identify 'resource extractors' and 'real consumers,' with training data sourced from Pixels' four years of real operations and attack records. This $200 million isn't all perfectly allocated, but there is a system in place that is continuously iterating to manage this.
This is why I think this figure is truly noteworthy: it's not about how much money has been distributed, but how long this system has operated under the pressure of $200 million and how many times it has been repaired.
Once external games are integrated, the next question is whether the correct distribution can continue.
Stacked has handled a cumulative reward history of $200 million, which is no small feat. But as I repeatedly review Stacked's materials, the more I feel there's something more critical than this figure: under the $200 million reward scale, the anti-fraud system has not collapsed.
This may sound like nonsense, but for the Web3 gaming track, it's not.
In the history of P2E, almost all projects with failing economic models share a common precursor: once the rewards scale up, the cost of bot and witch attacks starts to fall below the profits. This isn't a tech issue; it's an economic one. As long as there's enough capital in the system, there will be people motivated to exploit it. During the peak of Axie, the 'scholarship' studios were essentially scaled-up farming factories, wrapped in a guild shell to mask the reality.
Stacked's anti-fraud system is based on a behavior pattern recognition machine learning model. Its training is not based on hypothetical assumptions in white papers, but on real attacks that occurred during Pixels' four years of operations. This includes specifics on how bots were exploited, the distribution of time, and the characteristics of consumer behavior—there are actual samples for these. I saw a number in a research report: AI can recognize the overlap between 'resource extractors' and 'consumers' at a staggering 98.8%. This means that those exhibiting both behaviors have been almost perfectly tagged.
How rare is this capability? To independently develop an anti-fraud system that can handle a reward scale of $200 million, at least two conditions are required: enough real attack samples and sufficient iteration time. Most new projects lack both. A team starting from scratch in the Web3 gaming scene is unlikely to face large-scale attacks in the first year—not because there are no black market activities, but because the pie isn't big enough to justify a dedicated attack. By the time the project really takes off, if the anti-fraud system isn't ready, the economic model will collapse. Stacked avoided this trap because Pixels already paved the way.
This is the real barrier posed by four years of data: it's not about how much data there is, but how many failures and fixes these data points record.
Of course, the $200 million historical scale was achieved within the @Pixels ecosystem, not validated in external games. After external games are integrated, whether the bots will change their tricks or the attack methods will evolve, and whether this model can adapt—these questions remain unanswered publicly. This is why I think the external data integration in Q4 is worth keeping an eye on, not just to see if revenue scales are climbing, but to see if the anti-fraud measures can hold up in unfamiliar environments.