Last night while sitting in a small café scrolling through AI threads ☕📱, I noticed something strange.
Every discussion sounded almost identical.
Which model is smarter. Which benchmark is higher. Which AI token is pumping harder this week 🔄📊
But the longer I looked at the current AI market, the more I felt most people were still circling around the surface of the problem.
Because AI probably isn’t just becoming a technology race anymore.
It’s slowly becoming an economic system.
And once that happens, the biggest question stops being: “Which model performs best?”
The real question becomes: “Who owns the value generated by intelligence itself?” 👀🧩
That’s honestly why OpenLedger started standing out to me recently.
Not because of the typical “AI + crypto” narrative. I think the market has recycled that phrase so aggressively that it barely means anything anymore ⚡🌍
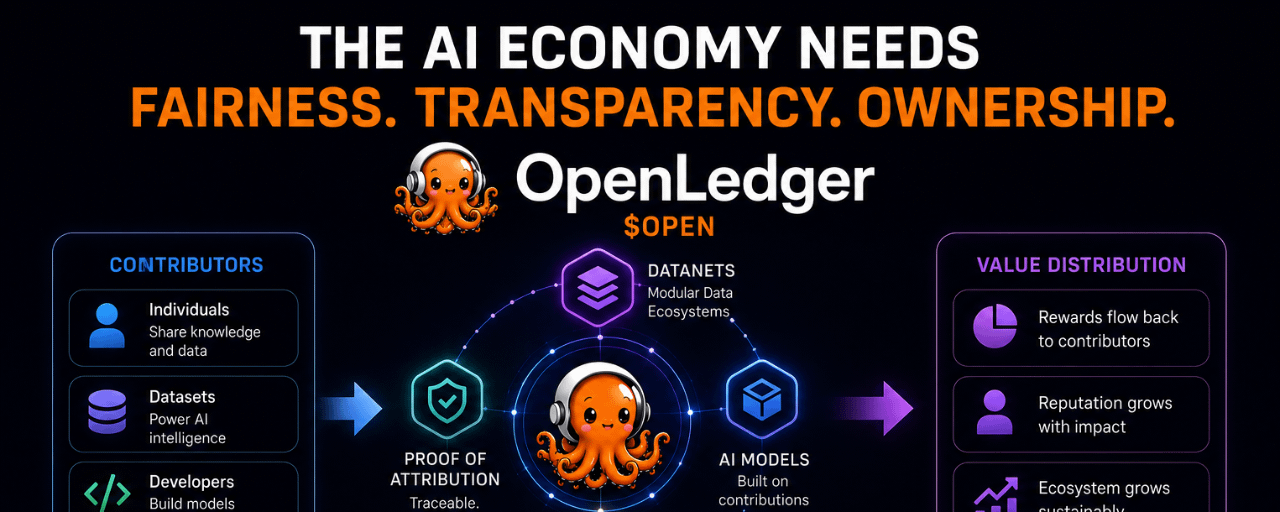
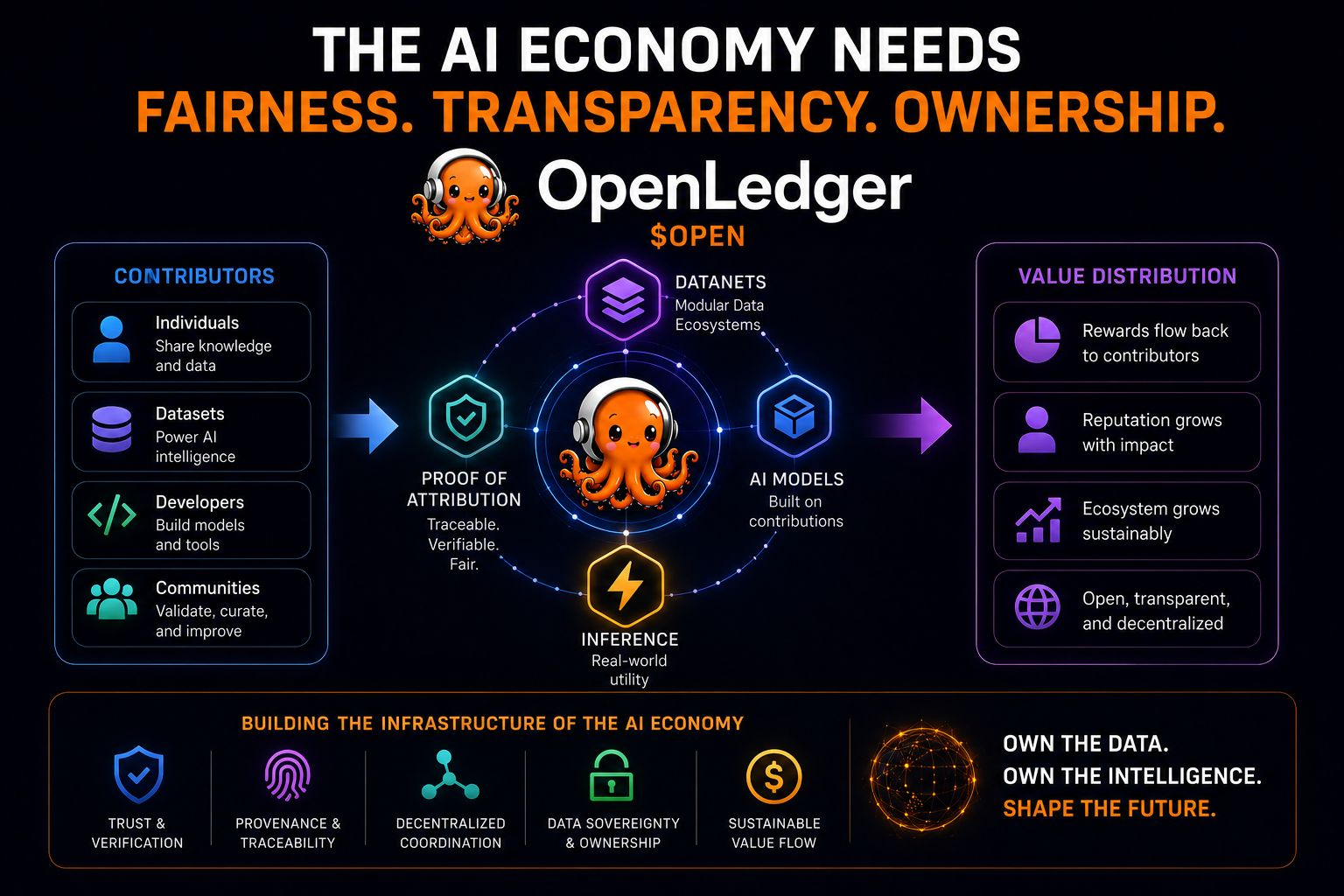
What caught my attention instead was how OpenLedger seems focused on attribution infrastructure rather than simply building another AI application layer.
And attribution sounds boring at first.
Until you realize it may sit underneath the entire future AI economy.
Right now, most AI systems operate through a fairly uncomfortable structure.
Millions of people generate the raw material:
conversations,
behavioral patterns,
labeling,
feedback,
datasets,
contextual knowledge,
domain expertise 📈🔧
But once that information enters large AI systems, contributors almost disappear economically.
The value accumulates somewhere else.
That’s the strange imbalance I keep thinking about.
The internet feeds AI continuously, yet the internet itself rarely owns the intelligence it helps create 🔄⚙️
And this problem probably gets worse as AI scales.
Because eventually AI systems begin generating synthetic data to train other AI systems. At that point, the lines between contributor, owner, source, and model output become extremely blurry 🧠🌐
That’s where OpenLedger becomes more interesting than most current AI projects.
At least conceptually.
From what I understand, they’re trying to create infrastructure where: data, model contributions, inference activity, and reward distribution are connected through on-chain coordination layers 🚀📊
Things like Proof of Attribution and Datanets are not just “AI features.”
They’re attempts to transform AI contribution itself into something measurable and economically trackable.
And honestly, that’s an enormous challenge.
Because attribution inside AI systems is fundamentally messy 👀⚡
In DeFi, value flow is relatively transparent. Liquidity moves. Fees are generated. Smart contracts process transactions.
But AI influence doesn’t work cleanly like that.
A model output rarely comes from one isolated source.
It emerges from overlapping embeddings, weight updates, retrieval systems, context windows, reinforcement layers, feedback loops, and millions of invisible relationships operating simultaneously 🔄🧩
So when systems attempt to assign contribution scores or distribute rewards, they’re not measuring perfect truth.
They’re building estimation frameworks.
And I think that distinction matters much more than most people realize.
Because once attribution becomes financial infrastructure, whoever designs the attribution model indirectly shapes the behavior of the entire ecosystem 🌍📈
That’s the part I keep coming back to when thinking about OpenLedger.
Not whether the AI is smarter.
But whether economic coordination around AI can remain fair once incentives become large enough.
Because incentives always change behavior.
Social media optimized engagement → outrage became profitable. Search engines optimized clicks → SEO farms exploded. Crypto optimized yield → mercenary liquidity appeared everywhere ⚡📱
So what happens if future AI systems optimize “data contribution rewards” without properly filtering quality?
Probably massive amounts of synthetic spam.
Industrial-scale data farming.
Reputation manipulation.
Contribution gaming.
Bot-generated knowledge loops.
And honestly, I don’t think blockchain automatically solves those problems.
It may even amplify some of them 👀🔧
Still, I think OpenLedger deserves attention because they’re at least confronting the issue directly instead of hiding behind abstract AI marketing narratives.
The project talks heavily about:
provenance,
verification,
modular Datanets,
attribution systems,
and contribution tracing 🧠⚙️
Which tells me they understand that future AI infrastructure is probably less about “building the smartest model” and more about coordinating trust across massive decentralized data economies.
And maybe that’s the deeper reason the AI community keeps watching OpenLedger.
Not simply because of the token narrative.
But because they’re trying to explore a question the industry still doesn’t fully know how to answer:
If data becomes labor in the AI era, how should ownership of that labor actually work? 🌐📊
I still don’t think anyone has solved that problem yet.
And honestly, I’m not even sure purely on-chain economic systems can solve it completely.
There’s always the risk that AI economies become over-financialized, where every interaction turns into incentive optimization rather than genuine knowledge creation ⚡👀
Sometimes when everything becomes reward-driven, authenticity quietly disappears from the system itself.
That’s why I’m still cautious.
But I also think OpenLedger is touching a much deeper layer of the AI conversation than most projects currently are.
Not: “How do we create smarter AI?”
But: “How do we coordinate value, ownership, and contribution once AI becomes infrastructure for the internet itself?” 🧩🚀🌍
And honestly, that might end up being the harder problem.