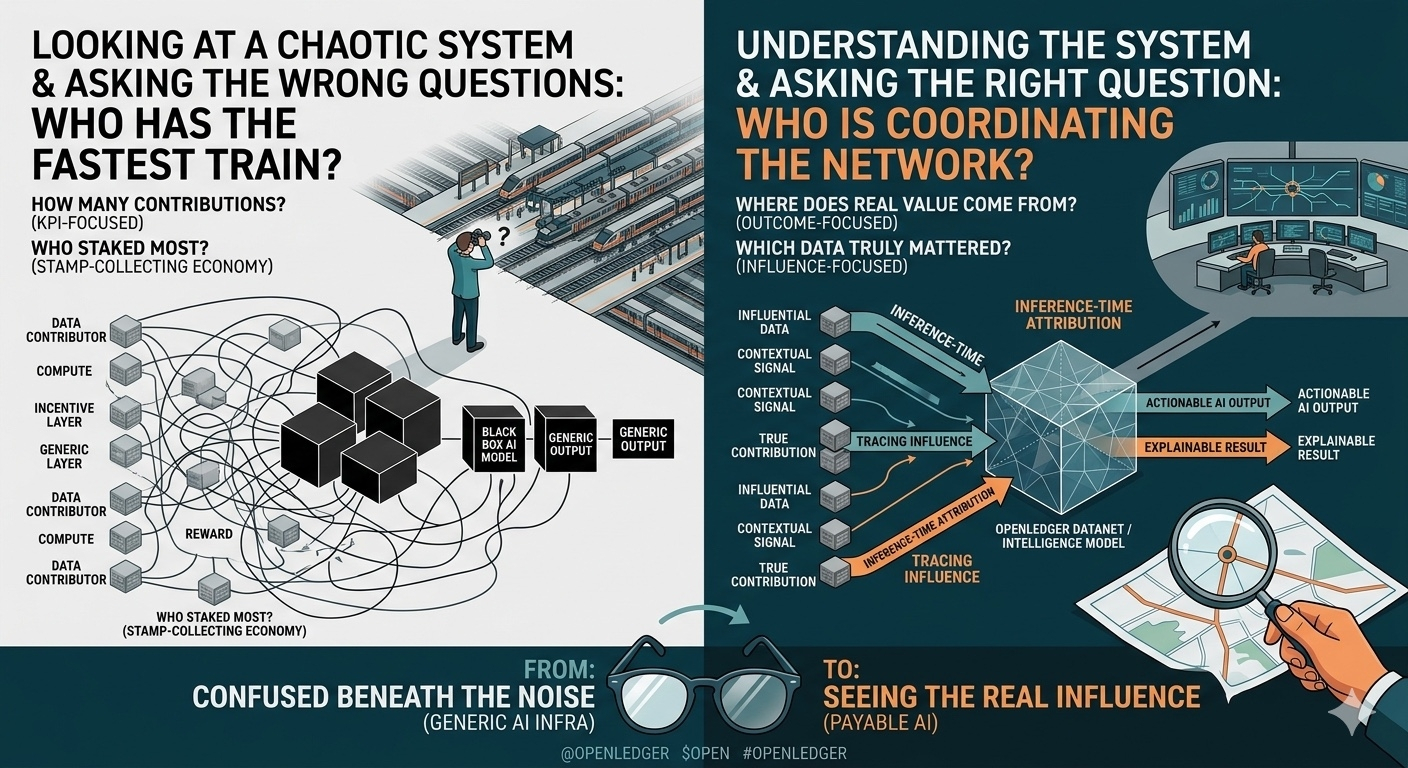
I used to see @OpenLedger as just your typical AI project. But now I’m starting to feel a bit off as I read more about it. It’s not really about whether this 'project' is solid or how long the AI narrative can keep running, since those debates are always going on in the market. What’s keeping me hooked is a rather unsettling feeling: the more I delve into OpenLedger, the more I see folks are looking at it through the wrong lenses. It’s like standing at a train station arguing about which train is the fastest, when maybe the real question is who’s running the entire network.
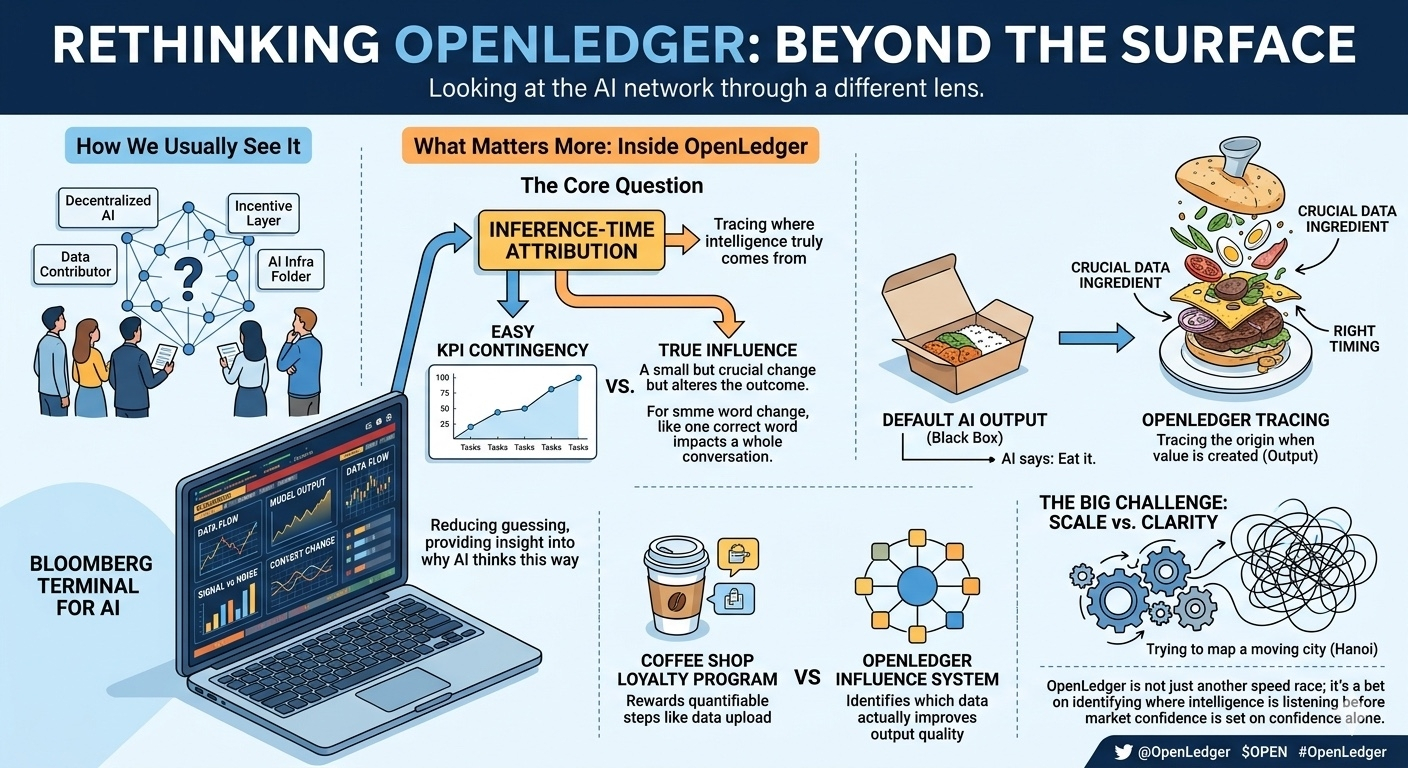
I didn’t think of this right from the start. When I first learned about OpenLedger, I viewed it like most people: decentralized AI, data contributor, incentive layer, toss in some technical buzzwords and file it under 'AI infra'. After reading, it seemed reasonable, a bit hard to understand, and then I moved on. But once I revisited the Proof of Attribution section, I began to notice a small detail that felt slightly off compared to the rest of the market.
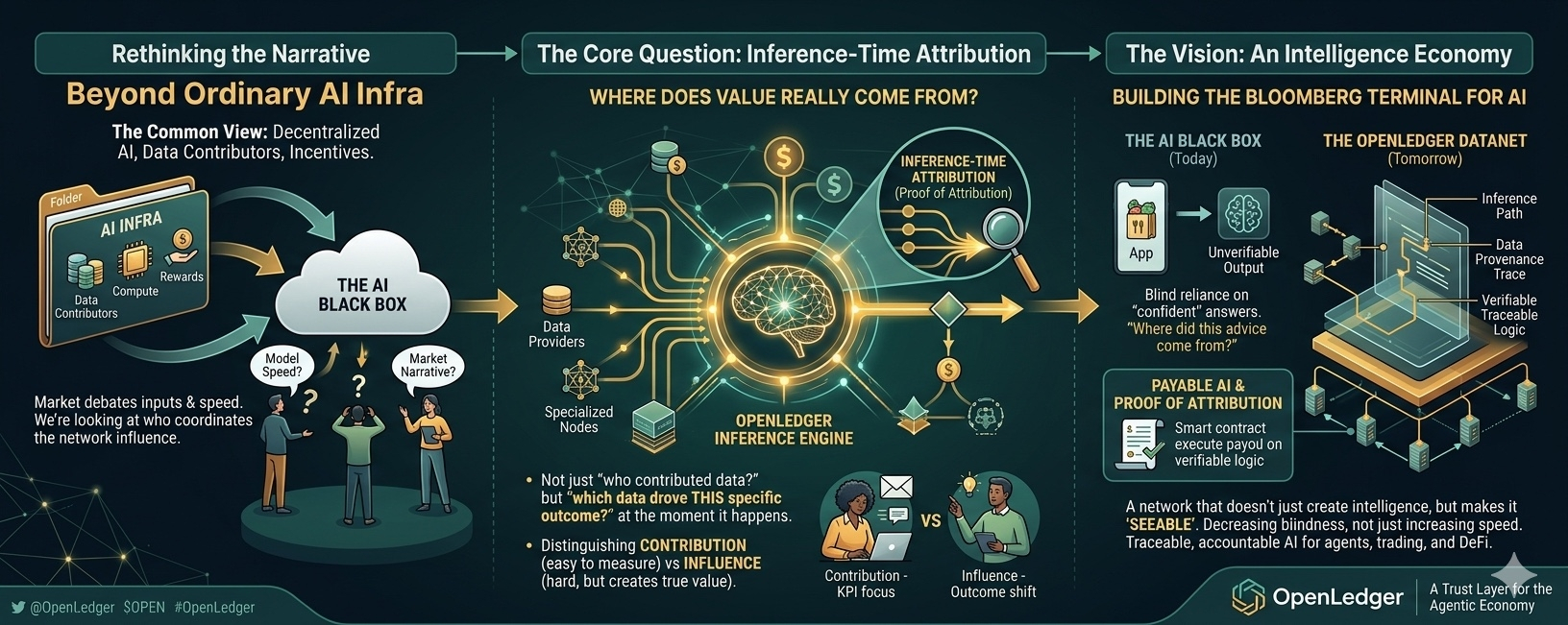
The detail is about inference-time attribution. Initially, I skimmed through it thinking it was just a different way of saying reward contributor. But the more I read, the more I see OpenLedger keeps coming back to that point, like that's what they really care about. And this is when I start to feel slightly uneasy: why are they so obsessed with attribution at the inference time?
Crypto isn’t lacking incentive systems. Anyone who contributes gets rewarded, anyone who stakes receives their share, anyone who provides compute gets incentives; this has become almost a default formula for the whole industry. If OpenLedger just wanted to build an AI network, they could easily tell a much more appealing story: better models, stronger compute, more data. But strangely, the more I read, the more I see they aren’t really in that race.
The question that OpenLedger keeps circling back to is a bit annoying: if intelligence creates value, where does that value actually come from? I know it sounds philosophical. But if you think about it, it's very real-world, like in a company where there are always people super busy, attending meetings, sending emails, and being present everywhere. But when something actually happens, sometimes just one person saying the right thing at the right moment is what turns everything around.
The more I ponder this, the more it seems like it's not about contribution anymore. It's more about influence. Contribution is easily visible, like if someone does a lot of work, their KPI looks good. Influence is much harder, because sometimes a very minor change is the thing that really alters the outcome.
This is when I start thinking about Bloomberg Terminal. I know it sounds far-fetched; I thought the analogy was a bit over the top at first. One side is a system for finance professionals, the other a crypto AI project talking about Datanets, attribution, and Payable AI; it sounds like they are trying to connect two unrelated things to make the writing seem deeper. But the more I think about it, the harder it is to shake that feeling.
If you’ve ever sat next to someone in finance, you’ll see they open Bloomberg not because they lack news. News is everywhere—Reuters, X, Telegram is full of people predicting the market as if they just had a private call with the Fed. Charts can be found anywhere; research reports are abundant on the internet. But the market has a very annoying problem: just because there’s a lot of information doesn’t mean you understand what’s really happening.
There are days when the market is down because of bond yields. Some days it’s due to liquidity pulling out. Other days it's because of skewed positioning. And sometimes it’s just because one big player makes the whole market panic. Bloomberg doesn’t make traders smarter; it just helps them guess a bit less about why the market is going crazy.
I’m beginning to see OpenLedger reflects that logic. It’s not just about building better intelligence immediately; it’s more about building a way for people to be less blind to intelligence. A place where at least you can trace why AI thinks that way, which data influences more strongly, and which contexts are steering the output in which direction. It sounds minor, but the more I think about it, the more I see this could be what the market is overlooking.
AI today feels a bit like ordering food on an app. You open the app, select a dish, and when it arrives, you eat. If it’s good, you order it again next time; if it’s bad, you switch places. Few actually care where the kitchen is, what ingredients are used, who cooked it, or why this dish is good. AI is the same; you ask, the model responds, and if it sounds reasonable, you just use it.

But when AI starts getting involved in real work, suddenly the question 'where does it come from?' isn’t small anymore. If AI writes incorrect content, you can just fix a few lines. But if AI starts getting involved in trading, treasury, DeFi execution, research agents, or capital allocation, that's a whole different story. A trading agent misunderstanding market regimes isn’t like a chatbot giving silly answers; it could misread signals and push money in the wrong direction.
This is when I look back at OpenLedger's inference-time attribution again. What keeps me stuck isn't the reward contributor thing, because every industry talks about that. What makes me linger is their attempt to pull attribution all the way to the moment the output is created, meaning when intelligence starts generating real value. In other words, not just asking who contributed data, but asking where the real influence comes from when the outcome occurs.
Thinking in everyday terms, it’s more like cooking than machinery. A delicious dish isn’t about having the most ingredients, but rather having the right ones at the right time. Sometimes just missing a pinch of salt makes a difference, or adding it at the wrong moment ruins the whole dish. I see OpenLedger trying to view AI through that logic: not everything that’s more is better, but what truly changes the outcome.
The more I think about it, the more I see today's AI economy resembling loyalty programs at coffee shops. Initially, they give stamps to keep customers coming back, which makes a lot of sense. After a while, customers start returning just to collect points for rewards, and some even order extra items they don’t drink just to avoid wasting a stamp. The dashboard retention looks great, the shop is always busy, but if you ask people if they still like coffee, you can't be sure.
I see the AI economy sometimes rewarding in that way. Uploading data is measurable. Computing is measurable. Training steps are measurable. The number of contributors is measurable. But which data actually makes the output better in the right context is much harder, almost messy in the literal sense.
And this is when I see OpenLedger going against the market tide. While most systems are optimizing the easily measurable, they seem to want to look at the harder-to-see: real influence. But the more I think about it, the more I see this is the most uncomfortable part of the whole story, because influence is often very hard to scale. The more you want to look closely, the slower it tends to be.
Bloomberg Terminal works because finance is heavily standardized. Tickers are the same, settlements are clear, accounting has standards, and reporting has formats. No matter how messy the data is, it ultimately has to speak the same language. Intelligence doesn’t behave that nicely; it’s very chaotic and constantly changing.
A slightly different context window can make the output vary. A data source today might be a signal, but weeks later it could turn into noise as the market shifts. A reasoning path that seems reasonable today might start to diverge next month when the environment changes. If you think of it this way, I start to realize that the hardest part of OpenLedger might not be building attribution, but making intelligence 'visible' while the intelligence itself is constantly morphing.
It's like trying to map out Hanoi, but every morning when you wake up, they’ve opened a few new alleys and changed the routes. To see more clearly, you have to accept a heavier system. To trace inference better, the complexity increases. To have less blindness often means it's not as fast as before.
I’m not sure if the market has enough patience for that. Crypto loves speed, AI loves scale, and OpenLedger, at least from what I read in the Proof of Attribution and how they talk about Datanets, feels like they are betting on a different assumption. Maybe what the intelligence economy lacks the most isn't a stronger model or a faster agent. Perhaps it's a place where you can at least trace who that AI is really listening to, before the whole market starts believing the output just because it sounds too confident.
\u003cm-76/\u003e\u003cc-77/\u003e\u003ct-78/\u003e