I want to spend some time on an idea that's embedded in OpenLedger's Datanet architecture but that I don't think has been adequately examined as an economic thesis in its own right.
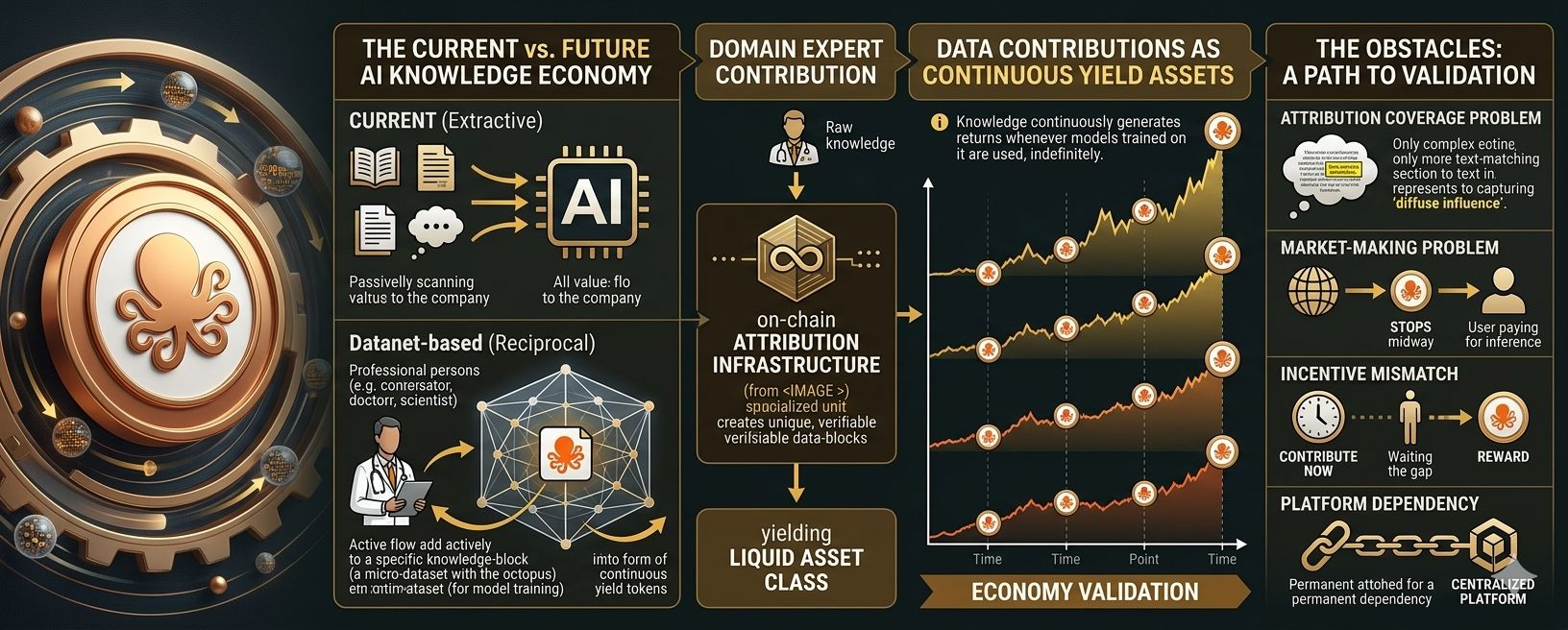
The thesis, in its clearest form: specialized domain knowledge can become a liquid, yield-bearing economic asset through on-chain attribution infrastructure. Not a one-time payment for data. Not a consulting contract. A continuously yielding asset that generates returns whenever the models trained on it are used, indefinitely.
This would be new. Let me explain why, and then let me explain the significant obstacles between the idea and the reality.
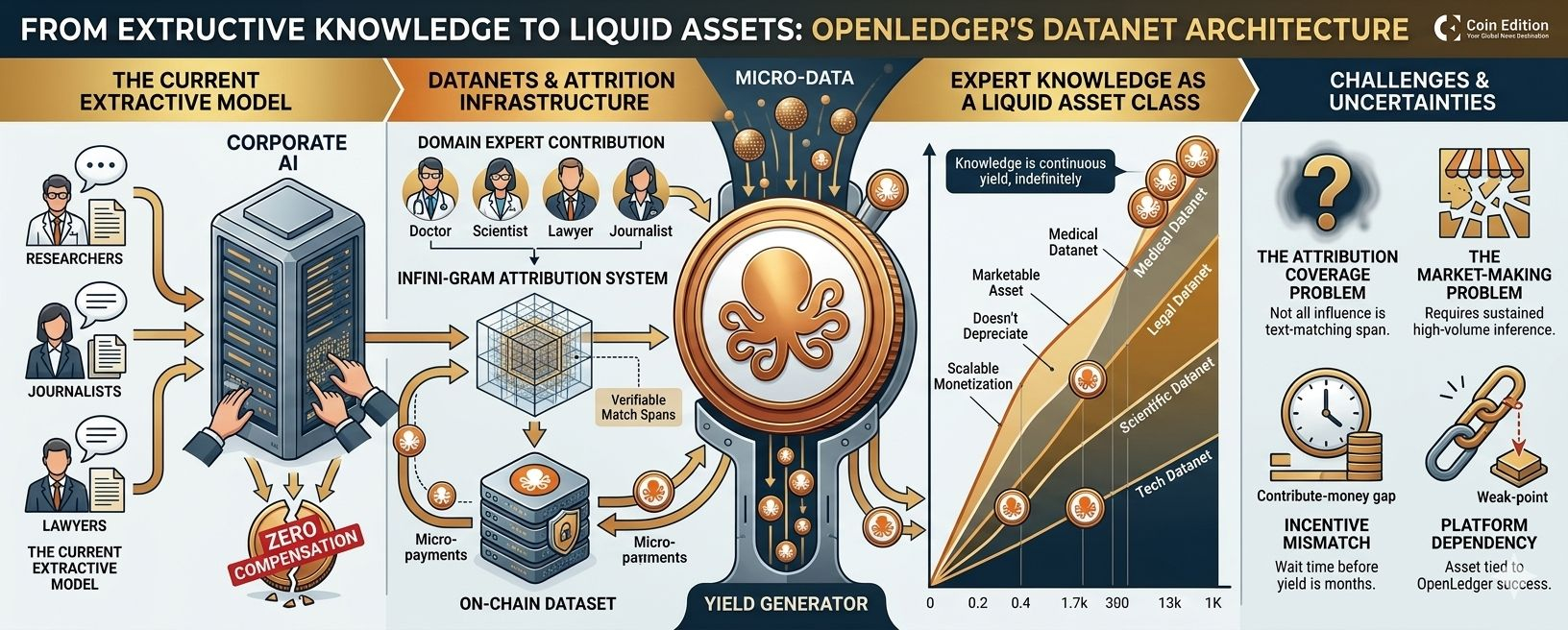
The current economic relationship between domain experts and AI systems is essentially extractive from the expert's perspective. Knowledge moves from expert to company without ongoing compensation. A clinical researcher whose published papers were scraped and used to train a medical AI model received zero compensation for their work's use in that model. A journalist whose articles trained a large language model received zero compensation. A lawyer whose drafted briefs were processed without consent received zero compensation. The work generated value for AI companies. None of that value flowed back.
This is the status quo. Most domain experts who think about this at all have concluded that it's unjust but unchangeable, because there's no mechanism to track which specific work influenced which specific model output. The connection is invisible and unprovable.
OpenLedger's Infini-gram attribution system makes this connection visible and provable, at least for a subset of influence that manifests as detectable span matches. Once the connection is provable, the compensation mechanism can be built. The OPEN token and the on-chain reward distribution implement that mechanism.
The economic implication: if a cardiologist contributes carefully structured clinical notes to a medical Datanet, and models trained on that Datanet are used for medical AI inference thousands of times per day, the cardiologist's Datanet contribution is a yield-bearing asset. Every inference that attributes to their contribution generates a micropayment. The asset doesn't depreciate in the traditional sense: good training data continues to influence models indefinitely. It might appreciate if the models trained on it are increasingly used as medical AI adoption grows.
This is a new asset class. The closest analogues are royalties from intellectual property: a songwriter whose song is played gets a royalty each time. But music royalties require industry infrastructure, collecting societies, registration with rights organizations, and legal enforcement mechanisms. They also require that the "playing" be tracked, which the music industry has built infrastructure for over decades.
OpenLedger is trying to build the equivalent infrastructure for AI training data contribution, faster, through blockchain infrastructure, and without requiring the contributor to understand the infrastructure layer underneath.
The scale potential here is significant. The global population of domain experts, people with specialized knowledge that would improve AI model performance in their field, is in the hundreds of millions. Physicians, lawyers, accountants, engineers, scientists, educators, researchers. Each of them has knowledge that has genuine value for AI training. Almost none of them currently have any mechanism to monetize that knowledge through AI.
If even a fraction of that population can be activated as Datanet contributors, and if the attribution system correctly tracks and compensates their contributions, the result is a new income stream for hundreds of millions of people who currently receive nothing from the AI economy that's built on their professional expertise.
That's the bold version of the thesis. Now let me explain why I hold it with uncertainty rather than confidence.
The attribution coverage problem. As I've described elsewhere, Infini-gram-based attribution captures influence that manifests as detectable text spans. Diffuse influence, where a domain expert's reasoning style or judgment patterns shape a model without producing recognizable text matches, isn't captured. For some types of contribution, the detectable span fraction might be large enough that the yield is meaningful. For others, the expert's most valuable contributions might be exactly the ones that don't produce detectable spans. The economic return on contribution will vary by domain in ways that aren't currently documented.
The market-making problem. For a Datanet contribution to generate yield, models trained on that Datanet need to be used for inference, at volume, with attribution computed and rewards distributed. This requires: a Datanet that's been contributed to sufficiently to train a useful model, a model that's been fine-tuned on that Datanet, deployment of that model for inference workloads, users who are paying for that inference, and the payment being routed through the attribution system to contributors. Every one of those steps represents a potential failure point. The last step, users paying for inference in a way that flows through attribution, is where most free-to-use AI products fail the economic model entirely.
The incentive to contribute before yield. Domain experts considering contribution face a temporal mismatch: they contribute now, models get trained, models need to be deployed and used, attribution runs, rewards flow. The time from contribution to first meaningful reward might be months. Asking experts to contribute significant professional expertise on the expectation of future micropayments, without a clear timeline or certainty of reward, is a behavioral ask that needs careful design to succeed.
The platform dependency. A Datanet contribution is a yield-bearing asset only as long as OpenLedger operates, the attribution system functions correctly, and the models trained on the Datanet remain in use. These dependencies aren't temporary; they're permanent. The contributor's asset is permanently contingent on platform success. This is true of many digital assets, but for professionals being asked to contribute real professional work, the question "what happens to my contribution if this project fails" is not an unreasonable one.
None of these obstacles are insurmountable. They're design problems that good product development and ecosystem building can address. But they're also obstacles that make the bold version of the economic thesis a future-state argument, not a current-state description.
The economic primitive is real. The market it could create, an economy where domain expertise generates ongoing returns through AI attribution, would be genuinely new and valuable. Whether OpenLedger can execute the path from "this could exist" to "this exists and works at scale" is what I'm watching for in the next two years.
The potential is among the most interesting I've seen in the crypto-AI space. The current state is much earlier than the potential. Both of those things are true simultaneously.
@OpenLedger $OPEN #OpenLedger $BSB
