A lot of people talking about AI are primarily stuck in the 'model layer' rat race.
Whose parameter count has doubled, whose inference costs have dropped by 90%, and whose newly released Agent is crushing the competition in IQ.
But as a long-time player in this arena, I'm more focused on a bottom-line crisis that the whole industry tacitly acknowledges but has long ignored: **In this AI empire that's inflated by trillions, where is the money really flowing?**
Especially when it comes to model training.
Over the past decade, Web2 has ingrained an absurd default logic in us: **Platforms build the workshops, and users provide free labor.** We chat, post, upload photos, and contribute feedback in our fields every day; these intangible assets are ultimately packaged as AI's 'fuel.'
You know AI is getting stronger every day.
But you don't know what makes it stronger.
What you don’t know is who’s sitting in offshore offices turning the value you contributed into their multi-billion dollar funding PPT.
This is a pure black box. The entire AI industry is like a **company raking in profits but never keeping accounts or disclosing financial statements.**
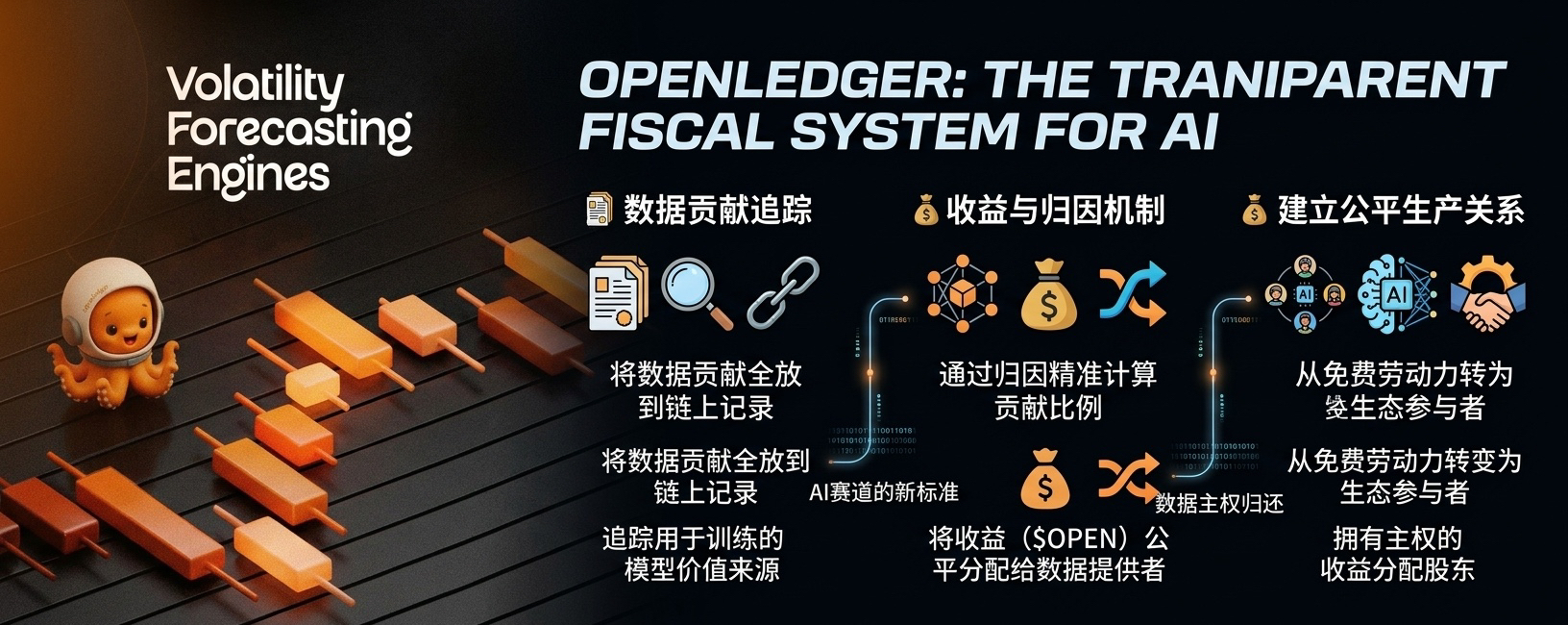
The recent surge in discussions about @OpenLedger on Twitter is because this project has done something revolutionary—it’s creating a 'transparent financial system' for the AI industry.
We need to shove the production relationships into the 'public ledger'.
What does transparent finance in the AI field mean?
In simple terms, it’s about leveraging the immutability of blockchain to record the contributions of data, model evolution, and profit distribution during the AI training process on-chain.
If we visualize the AI industry as a modern large factory:
Model companies are the factory bosses.
Computing power is like a production line machine.
Data is the raw material.
In the past, bosses held the pricing power, assuming that raw materials on the internet could be 'zero-cost purchased' indefinitely. But with large models diving deeper, this overexploitation model can't hold up anymore.
Because the high-quality data that can truly bridge the model gap—like real industry cases, expert feedback from specialized scenarios, and behavior logic that is highly personalized—are extremely scarce on the public web and can't be harvested in bulk.
OpenLedger is cutting into this traceable data contribution system.
The logic it tries to solve is hardcore: which data actually participated in the training? Which data made a core contribution to the final accuracy improvement? Once clarified, it uses on-chain attribution mechanisms to fairly distribute the corresponding $OPEN profits to contributors.
This disrupts the production relationships that the internet has accumulated over twenty years: users are no longer the data nutrients being exploited for free but are becoming true stakeholders with sovereignty in the AI ecosystem.
Why does 'transparency' determine the life and death of the AI track?
When the industry was still small, opacity could be explained as the rough growth of 'grassroots entrepreneurship'. But now, AI is reshaping the societal foundations of finance, healthcare, education, and other highly sensitive, heavy asset areas.
If a financial agent recommends an asset portfolio but the training data sources are unclear, would you dare to throw millions into it?
It's like a medical diagnostic model; if the flow of benefits behind it is murky, how can doctors and patients trust it?
So, the combination of the Web3 industry and AI is definitely not as simple as just launching an 'AI Meme token'. The AI industry has reached a point where a public, verifiable ledger is absolutely necessary.
OpenLedger has stepped up to provide a blockchain record solution, presenting what seems to be the most logical industrial-grade answer.
Ideals are sexy, but reality is pretty tough.
Of course, let’s talk pragmatically behind closed doors: This sounds explosively sexy, but the engineering difficulties in making it a reality are also significant.
Training AI models is an extremely complex chemical reaction. Fine-tuning hundreds of billions of parameters involves a lot of data cross-contamination, multiple rounds of complex gradient descent, and the collaboration of thousands of GPUs.
How can we accurately and cost-effectively record the contribution of a specific dataset amidst such complex calculations?
How do we ensure absolute fairness in profit distribution while preventing data manipulation and witch attacks?
These are still pain points at the forefront of computer science and cryptography. So at this stage, I prefer to see OpenLedger as a **pioneering direction exploration**.
It didn’t jump on the bandwagon to create upper-layer applications that won’t lead to the future; instead, it rolled up its sleeves to try to bring the greed and chaos hidden in the black box of the AI industry slowly into the light.
As for how far it can push things in the future, we as observers need to give it time to validate its mainnet data and ecosystem density. But at least it poses an unavoidable soul-searching question to the entire industry:
In the future, in the trillion-dollar AI world, should profit distribution be more transparent?
Feel free to chat in the comments: Where do you think the biggest resistance to making AI platforms 'publicly reconcile accounts' will come from?