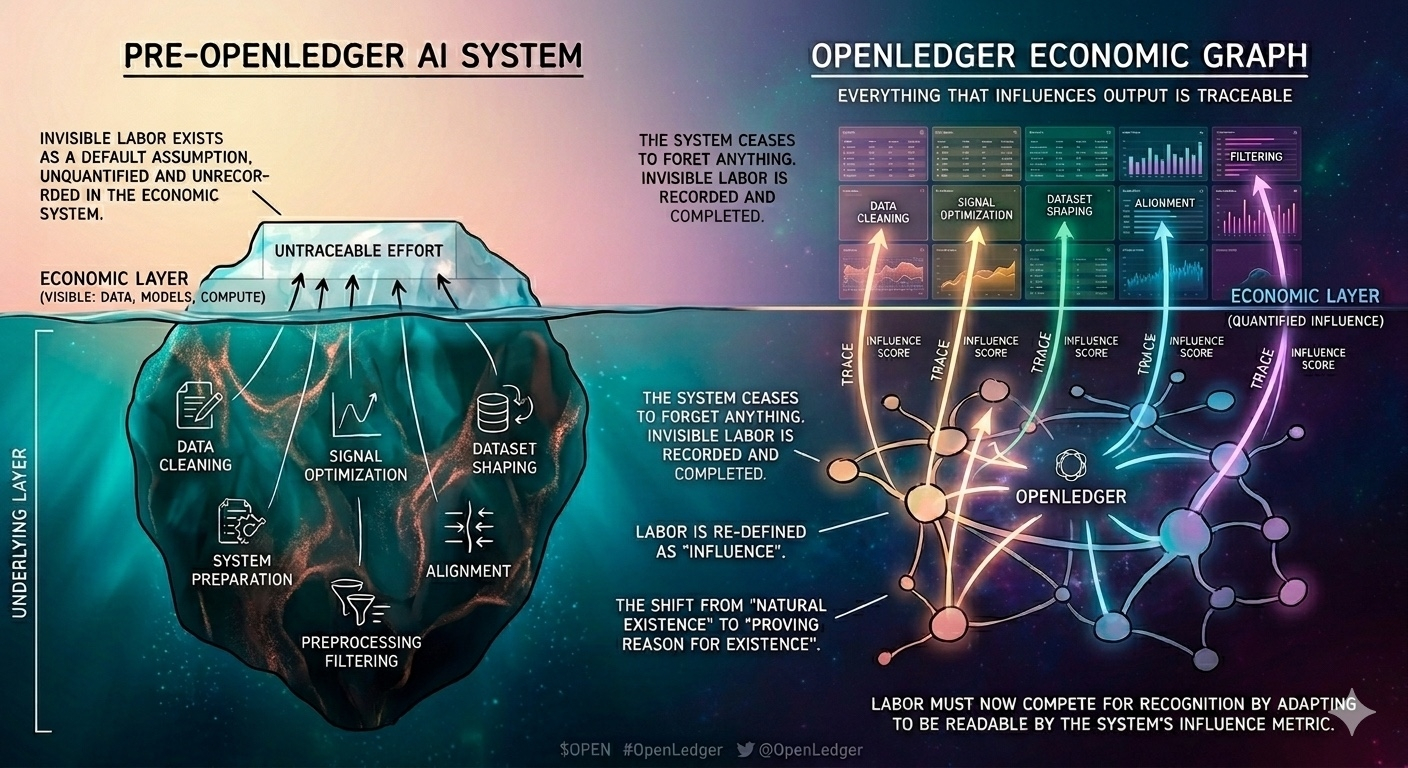
Today, I started to view OpenLedger in a different light, not because of any specific feature, but because of how it redefines 'contribution.' It’s no longer just about data, models, or compute. Everything that can influence the output can be traced back. It sounds like a layer of transparency, but the first impression is: this system doesn’t forget anything.
In most AI systems, there's a very familiar area that few notice, known as the part where everything gets erased. Data cleaning, preprocessing, filtering, alignment… it all sits there. No one sees it, but without it, the system can’t run. OpenLedger doesn’t disrupt that zone, but it starts to flip the script: if this part has an impact, why isn’t it part of the system’s economy?
This approach sounds quite reasonable at first. Because indeed, if a contribution produces better output, it should be recognized. But once you start recognizing, you create something else that the previous system didn't need: the ability to compare. And once comparison exists, invisible labor no longer remains static at the baseline.
Interestingly, OpenLedger doesn't say 'this is the more important work'. It just says 'this is the work that has influence on the output'. But just changing that language, the entire structure of how labor is perceived starts to shift. Because influence is something that can be measured, while roles cannot. And when everything is reduced to influence, the system begins to lose its ability to distinguish layers.
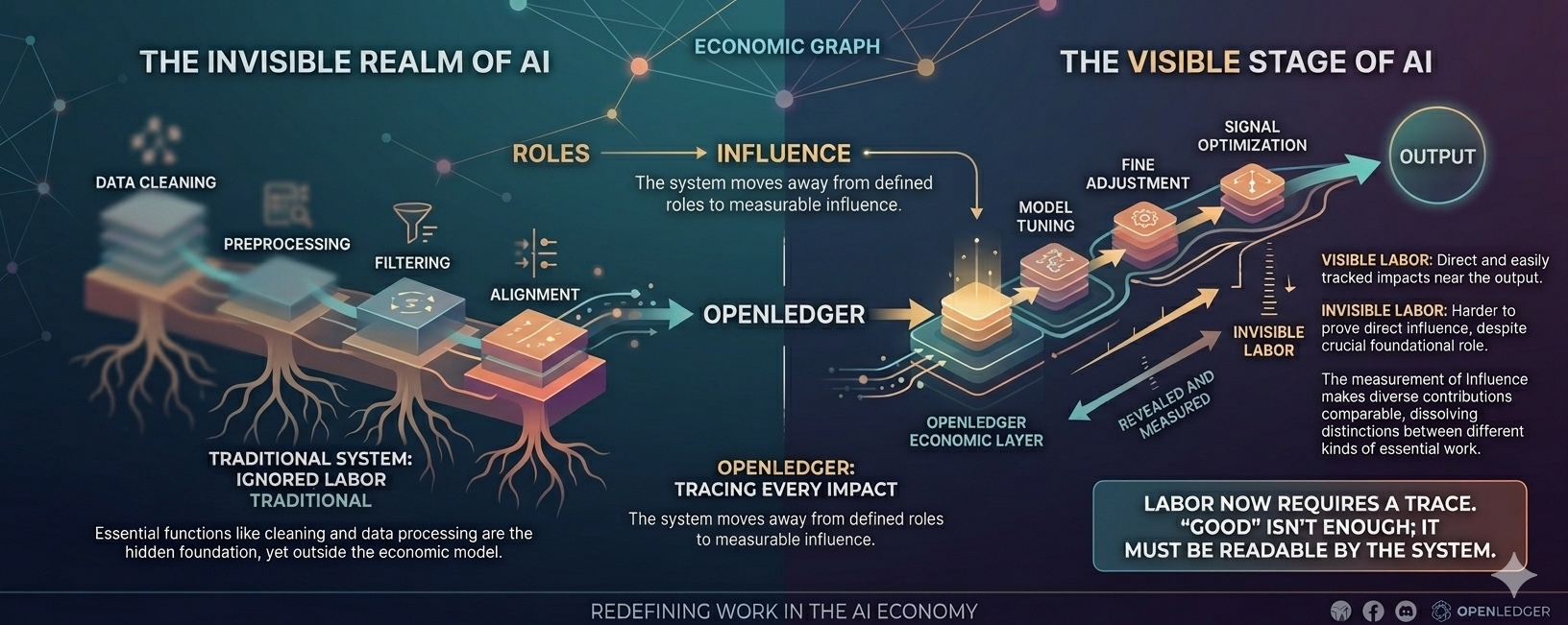
I've noticed this most clearly when thinking about data cleaning and signal optimization. In reality, these two things never sit in the same conversation. One keeps the data from being wrong, while the other makes the model better. But in OpenLedger, both are pulled toward the same question: which one influences the output more. And this question sounds simple, but it erases the differences in nature.
There's a pretty clear everyday example. In a restaurant, the person preparing the ingredients in the morning is often never remembered by the customers. But if they're missing for a day, everything collapses immediately. OpenLedger does something similar with AI systems: it starts to put the 'unnoticed but essential' parts into the same valuation space as the 'everyone can see' parts.
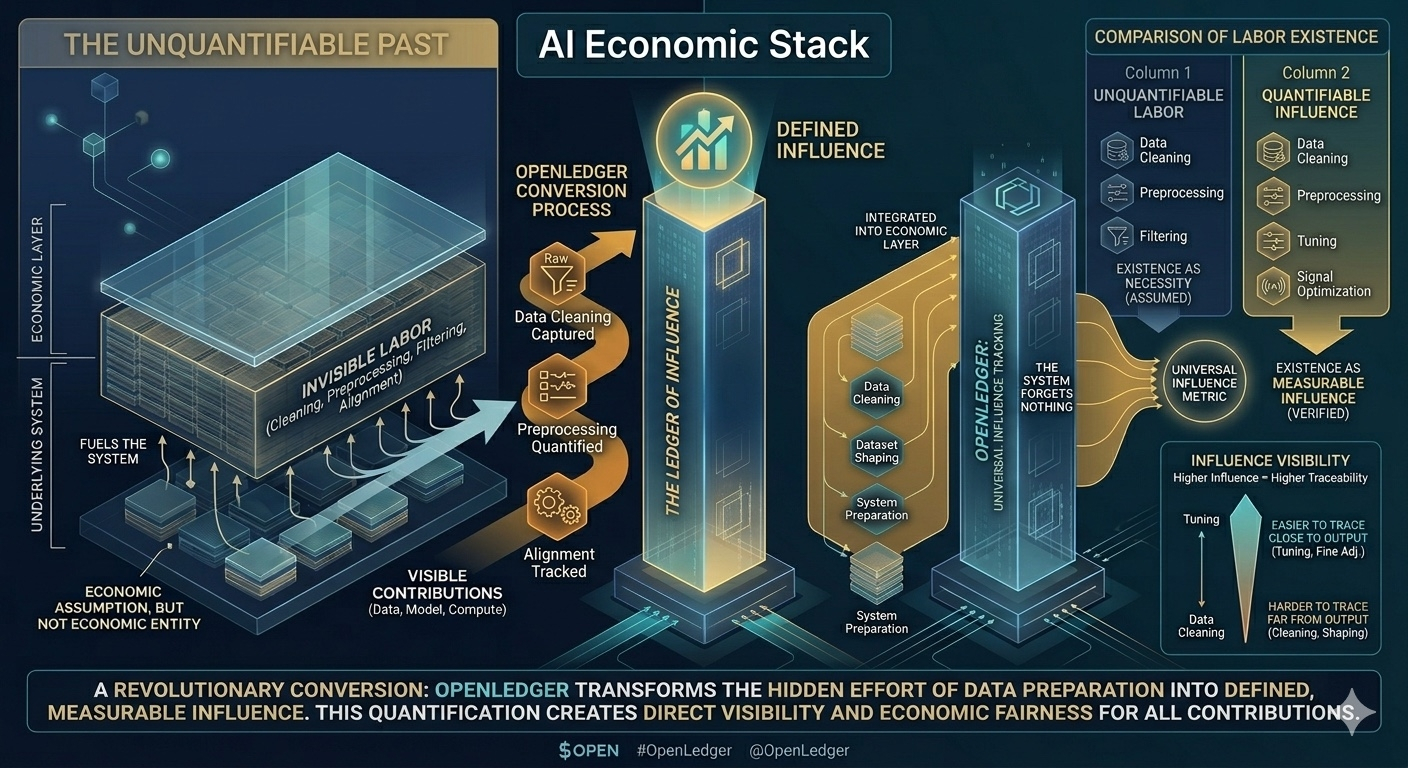
The positive point is clear. Previously, many types of contributions had no way to be recognized in the economic system. They existed as a default assumption. OpenLedger opens up the possibility to turn those parts into distributable value. But the price is that once recognized, they are no longer the baseline.
And when it's no longer the baseline, they have to start competing. Not direct competition like in traditional markets, but in a new space: the ability to be read by the system as influence. A contribution no longer just needs to be 'good', but it needs to 'have trace'.
This is where many people misunderstand OpenLedger. It doesn't say that all contributions are the same. But it forces all contributions to go through the same measurement mechanism before being distributed value. And that measurement mechanism doesn't understand 'roles'; it only understands 'influence'.
When this happens, a slight shift begins to form. Things closer to the output are naturally more visible. Signal optimization, tuning, fine adjustment… they have a clear trace. Meanwhile, data cleaning, dataset shaping, system preparation are harder to prove direct influence. Not because they are less important, but because they are further along in the system's observation chain.
A fair counterargument is: if there's no way to measure it, invisible labor will always remain outside the economic layer. It's important, but it can't distribute value. And OpenLedger is solving a real problem: how to ensure those foundational elements are not completely forgotten in the AI economy.
But the issue isn't whether to measure or not. It's that once everything goes through the same influence measurement, the system starts equating things that are inherently different. Keeping the system accurate and improving the system are placed on the same comparative plane, even though they serve different layers.
I've started to think that invisible labor in OpenLedger is neither disappearing nor being minimized.
It just shifts from a state of 'no need to explain' to a state of 'must prove its reason for existence'. And when it has to prove, it starts to be shaped by the way the system understands.
There's something more important behind this. OpenLedger is not just building a value distribution system for AI. It's changing the conditions for a type of labor to be considered 'truly existing' in the economic graph. If it can't be read as influence, it no longer stands in the economic system.
And when I look back at all that logic, what stops me is not whether it's right or wrong. But the feeling that from this point forward, labor can no longer be understood in a natural way. It's only understood in the way the system can read, recognize, and distribute.
And I'm not sure if that's a step forward or just a change that can't be reversed later. But one thing is quite clear: once invisible labor has entered OpenLedger, it is no longer invisible in the old sense. It's just something trying to find a way to be seen correctly in a system that has changed the rules of the game.