After just a week diving into @OpenLedger I’m starting to realize that it’s not as straightforward as I thought; this time it’s not from the whitepaper or any narrative ‘attribution layer’, but from something very down-to-earth: compute is now so cheap that you don’t even feel it’s being used anymore.
It's like opening an app and everything responds instantly. So fast that you don't even think about how much it takes to run behind the scenes. And just when that feeling fades away, another thing disappears too: the awareness that the output had a history to exist.
Output begins to appear as if it naturally emerged, no longer needing the story behind it.
Initially, I saw this as a very clear advancement. Compute commodity makes AI more accessible, makes experimentation cheaper, and makes the speed of output creation nearly limitless. But the more I observe the system operating at scale, the more I see the opposite: as the cost of creating output approaches zero, the cost of retaining 'the reason why that output exists' invisibly increases.
Not because tracing technology has deteriorated. But because there's no longer economic pressure to maintain the depth of history. The system begins to choose a simpler route: to drop the memory in order to keep things running.
In that context, OpenLedger does not resemble a typical AI project. It resembles a deliberate response to something that is happening naturally within the system: the dissolution of identity as compute becomes too cheap.
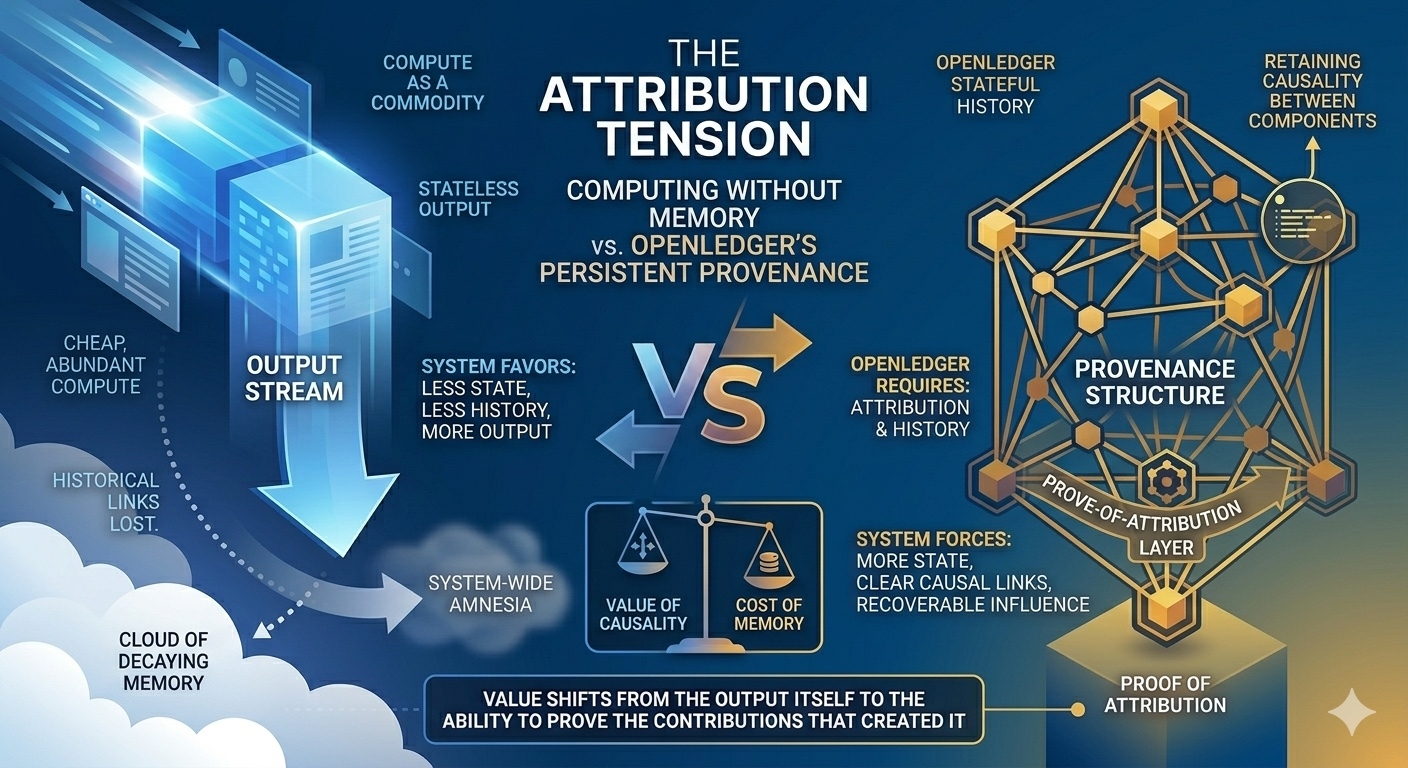
The important thing is that OpenLedger does not oppose compute commodity. It acknowledges it as a foundational condition that has occurred. But instead of allowing the system to drift towards 'output is enough', it poses a tougher question: if every output can be created almost for free, what still holds enough weight to compel the system to remember how it was created.
Proof of Attribution in OpenLedger does not operate as a mere credit mechanism. It functions like a layer that compels the system to retain the causal relationships among the components that generate output, even when that output is produced in a fragmented and high-speed environment.
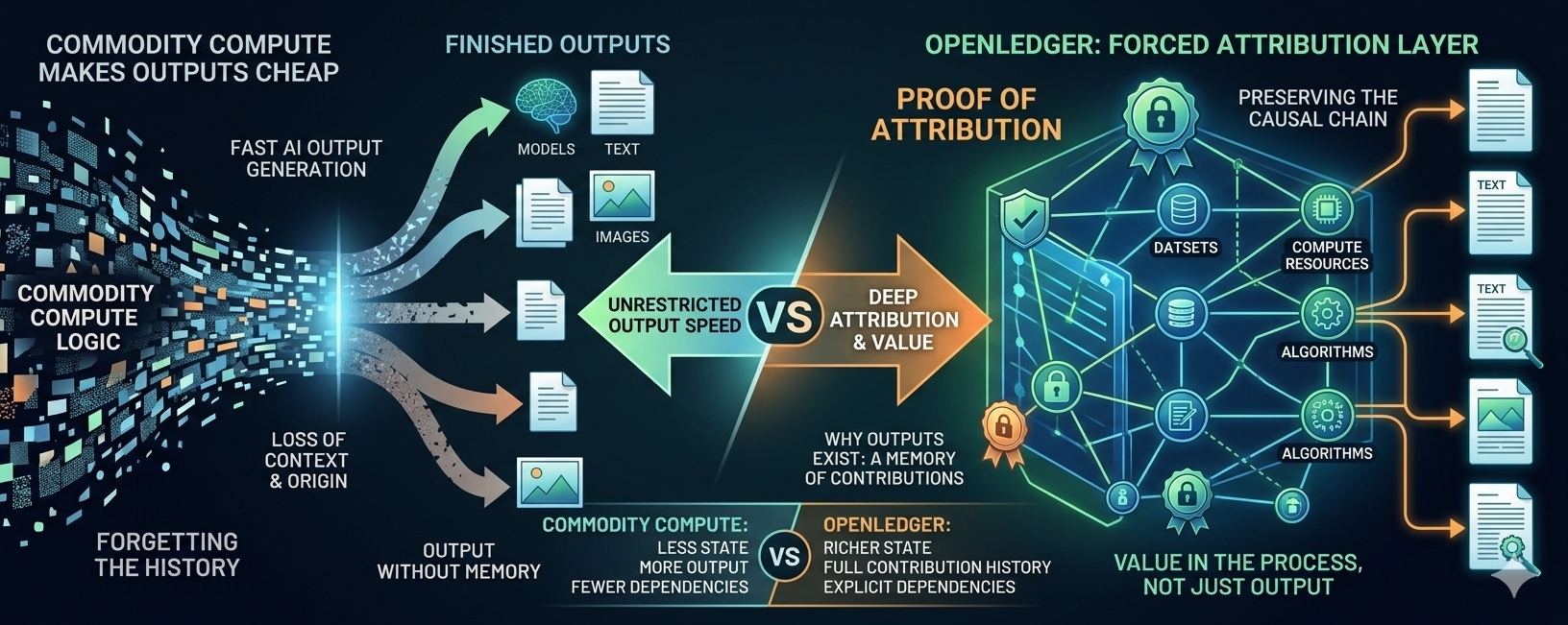
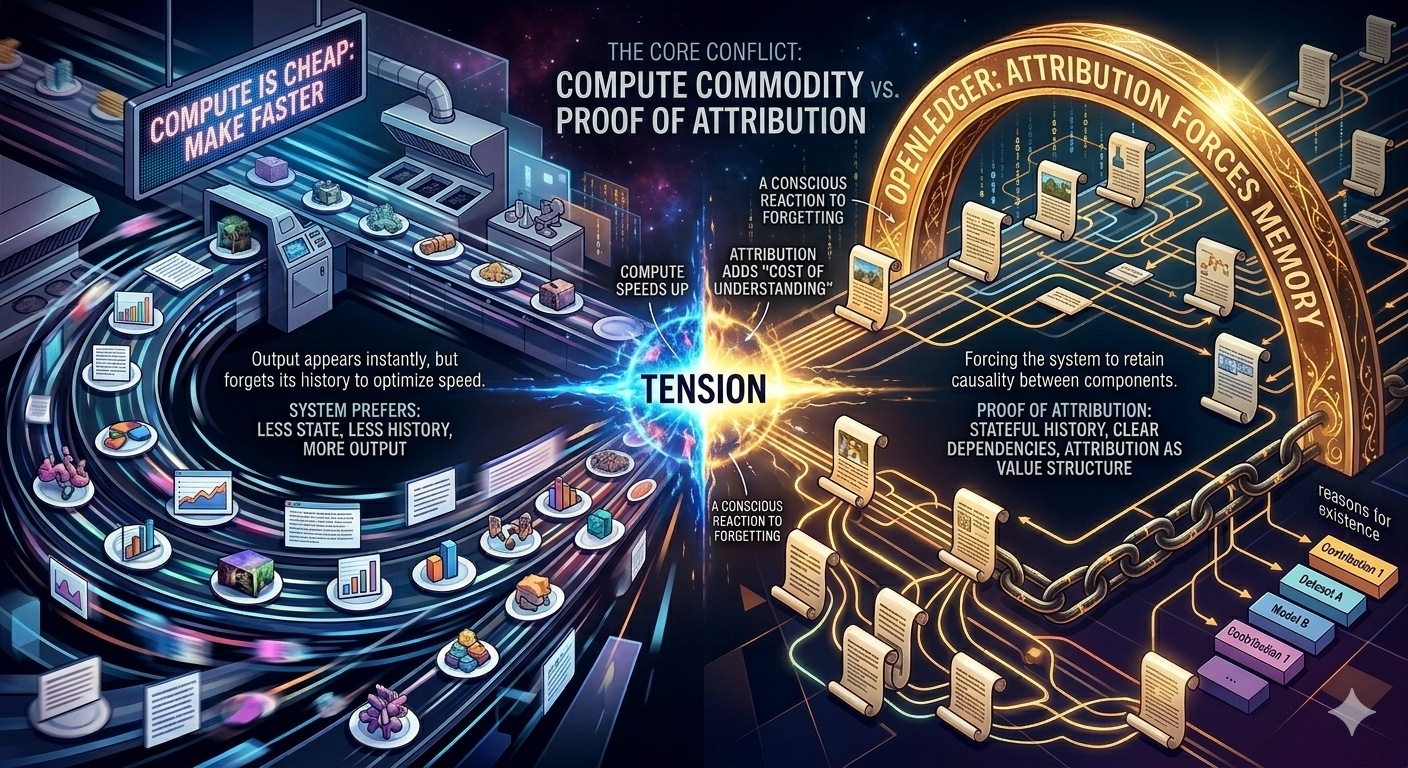
In the logic of compute commodity, the system always wants to move towards: less state, less history, less dependency, more output.
But OpenLedger forces the system to retain a counter part of that logic: longer state, clearer dependency, fuller contribution history, and most importantly: the ability to trace back influence.
This may sound technical, but it actually touches on a very simple point: does the system still distinguish between 'what is created' and 'what makes it possible to be created'.
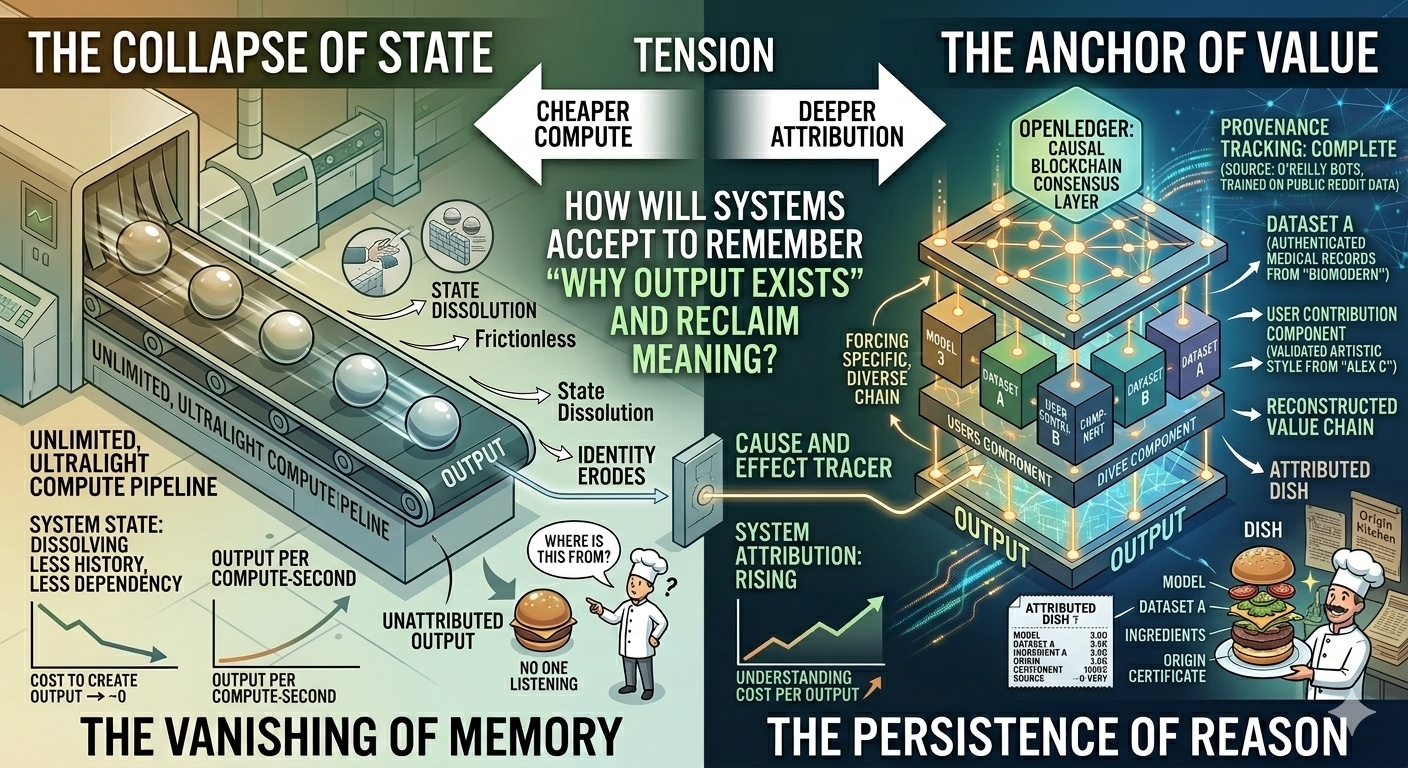
There's a very relatable example: When compute was expensive, each output resembled a carefully cooked dish in a small kitchen. The chef remembers every ingredient, every step, every decision. But when compute becomes cheap, everything resembles an industrial kitchen running continuously. The dish is still created correctly, quickly, fully, but no one has the time to remember each specific component of every dish.
And the noteworthy thing is: no one sees it as wrong. It's just that gradually, the question 'where did this come from' no longer feels natural in the way the system operates.
OpenLedger does not slow down the cooking. It just forces each dish to come with a trace of how it was created, even if the cooking speed remains unchanged.
This creates a very clear tension but few people address directly: the cheaper compute gets, the more the system wants to erase history to optimize speed; but the deeper the attribution, the more the system must reconstruct history to define value.
These two forces do not meet in a state of equilibrium. They pull the system in two different directions. One direction is faster creation. The other direction is better understanding. And there's no natural stopping point between those two directions.
There's an important point: OpenLedger does not seek to retain history for ethical or transparency reasons. It addresses a much more practical problem in a compute commodity world: if the origins are not retained, the system will begin to lose track of what it is paying for.
When every output can be recreated at nearly zero cost, value no longer lies in the output itself, but in the ability to prove that output could not exist without a specific chain of contributions.
And at that point, attribution is not merely 'acknowledgment'. It becomes the structure that prevents value from dissipating.
But there's a light counterargument right within this logic. The deeper the attribution, the more history the system must retain, which introduces a new kind of cost: the cost of understanding. Not the compute cost, but the cost of maintaining the interpretive structure of the entire system.
Compute commodity makes work nearly free. Attribution makes the understanding of what created that work no longer free. And these two do not scale in the same way.
Interestingly, OpenLedger does not position itself as 'the optimal AI economy solution'. It resembles a system that forces AI to carry the memory of its own creation process, even as that memory becomes heavier over time.
In a world where output can be continuously generated, the issue is no longer 'what does AI create', but 'does AI still remember what it had to go through to create that'.
There's a very mundane moment I think back on: opening an app and seeing everything run so smoothly that you can no longer distinguish between an important action and just an intermediary step. Everything becomes a smooth, uninterrupted flow.
Compute commodity is pushing AI towards that state. OpenLedger, on the other hand, intentionally does the opposite: it recreates 'slight breaks' in that smooth flow, so the system does not completely slide into a state where structural distinctions are no longer needed.
And this is the final point, but the most important. If compute continues to become cheaper to the point of being almost infinite, then the question is no longer how much output AI can create, but whether the system still accepts retaining how much 'reason for existence' each output has.
OpenLedger, at its deepest level, does not stand against compute commodity. It stands for retaining the possibility that in a world where everything can be easily created, the system still remembers that nothing ever appeared without a specific chain of contributions behind it.