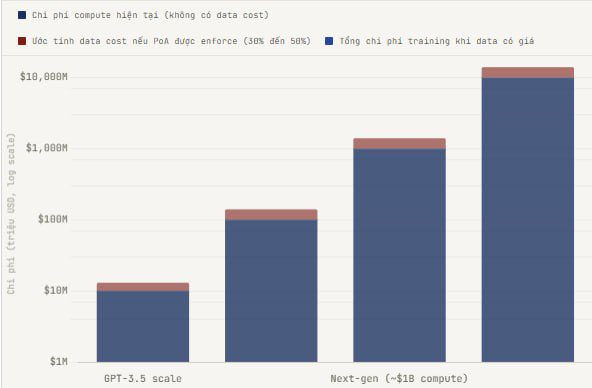
I started thinking about this after reading a figure in Goldman Sachs' 2024 report: it estimates the cost to train GPT-4 at around $100 million. That figure doesn't account for the cost of data, since data is sourced for free from the internet. If data wasn't free, how much would that figure be? No one knows for sure, but many estimates suggest that high-quality curated data could account for 30 to 50% of the training value if priced at market rates. With GPT-4, that's $30 to $50 million just for one training run. For the next model, it could cost $1 billion to train, with data costs hitting $300 to $500 million.
This is what @OpenLedger and $OPEN are trying to build infrastructure for: a world where each dataset has a price tag, each inference has a royalty trail, and AI labs can no longer continue the "free data buffet" business model they’re currently running. Not through legislation, not through advocacy, but through an on-chain protocol layer that, with enough adoption, becomes a standard that cannot be ignored.
I want to be straightforward about something that both research files I read hinted at but didn’t outright say. The Spotify model is the closest example to what OpenLedger is trying to do. Before Spotify, small musicians got nothing from illegal downloads. After Spotify, they earn micro-royalties every time a song is streamed, even if the amount is small. More importantly, that standard has transformed the entire music industry. Not because Spotify is generous, but because they built infrastructure good enough to enforce royalties at scale in a way that the music industry can’t ignore.
The issue is that OpenLedger can’t force Big Tech to do anything, at least not in a direct sense. Google can keep training on Common Crawl for free even if OpenLedger exists. No one can stop that with a smart contract. This is the real weakness of the thesis, and I think it’s important to state it rather than just write one-sided bullish content.
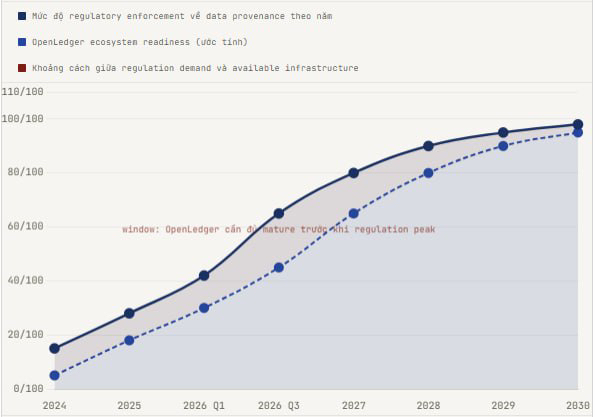
But this is how OpenLedger can create change not through direct enforcement but through alternatives: if models trained on OpenLedger DataNet with verified, curated, domain-specific data consistently outperform models trained on noisy internet data in regulated domains like healthcare or legal AI, then enterprise buyers will prefer models from OpenLedger. Not because they care about fairness, but because the EU AI Act and other regulatory frameworks are starting to require provenance documentation. A hospital buying an AI diagnostic tool needs to prove to regulators that the training data for that tool meets quality standards. OpenLedger's PoA trail provides just that. Naturally, without forcing anyone.
When I check out the investor list of OpenLedger, particularly Balaji Srinivasan, who has predicted many major tech shifts before hitting the market, it boosts my confidence not because Balaji is always right, but because he usually only bets when he sees clear regulatory tailwinds. The EU AI Act, US AI Executive Order, and Singapore's AI governance framework are all pushing towards mandatory data provenance. OpenLedger doesn’t need to convince Big Tech. They just need to wait for regulators to do that for them.
 What makes me believe in this long-term thesis isn’t hype or FOMO. It’s simple economic logic. In 20 years of the internet, everything that seems free eventually gets priced in. Free email, then spam filters and email marketing became a billion-dollar industry. Free search, then SEO and Google Ads became a major part of internet GDP. Free social media, then the attention economy and data brokerage became the business models for Meta and Twitter. Free AI data, what will it become? OpenLedger is betting the answer is the attribution economy, where every trace of data has an on-chain price tag.
What makes me believe in this long-term thesis isn’t hype or FOMO. It’s simple economic logic. In 20 years of the internet, everything that seems free eventually gets priced in. Free email, then spam filters and email marketing became a billion-dollar industry. Free search, then SEO and Google Ads became a major part of internet GDP. Free social media, then the attention economy and data brokerage became the business models for Meta and Twitter. Free AI data, what will it become? OpenLedger is betting the answer is the attribution economy, where every trace of data has an on-chain price tag.
I’m not sure about the exact timeline. It could be 3 years, it could be 7 years. But while everyone is shorting $OPEN because it’s down 91%, I see what I’m buying not as a token in the red. It’s a bet that AI will have to pay for data just like Netflix pays for content, and OpenLedger is building the infrastructure to collect that cash.
If the EU AI Act truly enforces data provenance documentation requirements for high-risk AI systems starting in 2026, and OpenLedger is the only infrastructure with an on-chain PoA trail granular enough to satisfy those requirements, do you think Big Tech will choose to integrate OpenLedger into their pipeline or build their own alternatives to avoid reliance on an on-chain protocol they can’t control?