

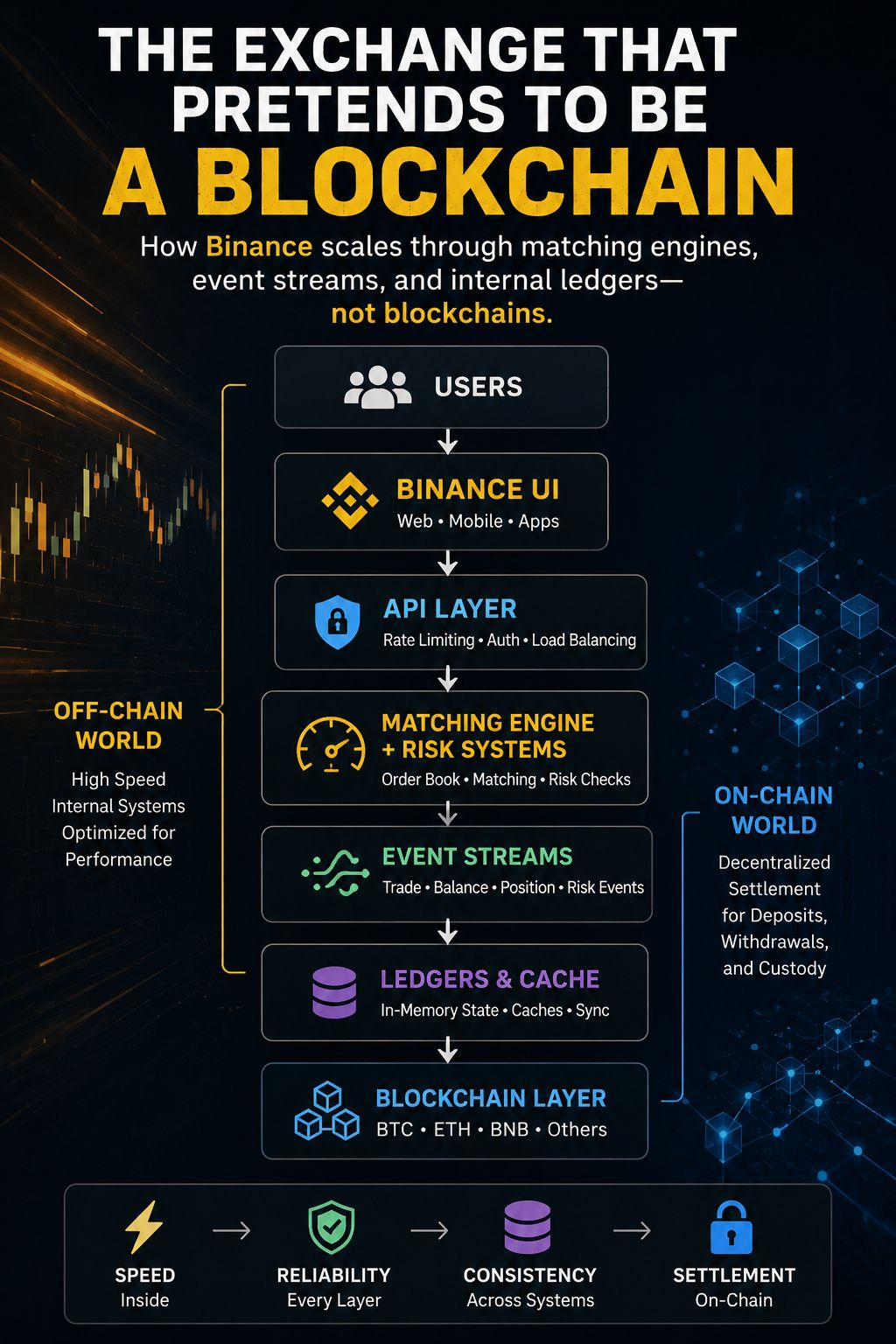
The easiest way to misunderstand Binance is to think of it as a blockchain company.
At first glance, that assumption seems perfectly reasonable. Users deposit crypto, trade crypto, withdraw crypto, and interact with an interface wrapped in the language of decentralization. The entire experience appears to sit on top of blockchains. Yet once you start pulling on the architectural threads, a different picture emerges. The system that actually powers Binance looks far closer to a large-scale financial exchange than anything most people would recognize as a blockchain application.
This isn't a criticism. It's probably the only way a platform of this size could exist.
A public blockchain is remarkably good at establishing shared truth between parties that don't trust one another. What it is not particularly good at is handling the kind of throughput modern markets demand. Traders don't think in block times. They think in milliseconds. Sometimes less. If every order, cancellation, balance update, liquidation, and position adjustment required blockchain settlement, the exchange would collapse under its own latency.
So most of the activity people associate with "crypto trading" never touches a blockchain at all.
When a user buys Bitcoin on Binance, the Bitcoin network is usually unaware that anything happened. The trade exists entirely inside Binance's infrastructure. Internal ledgers change. Account balances move. Risk systems update positions. Market data streams publish new state. The blockchain only re-enters the picture when assets cross the boundary between Binance and the outside world.
That boundary turns out to be one of the most important architectural lines in the entire system.
Everything inside the boundary is optimized for performance. Everything outside it is constrained by the realities of decentralized settlement.
The consequence is a platform that operates as a hybrid of two fundamentally different worlds. One side prioritizes trust minimization. The other prioritizes speed. The engineering challenge isn't choosing one philosophy over the other. It's building the machinery that allows both to coexist without constantly fighting each other.
At the center of that machinery sits the matching engine.
People often talk about exchanges in terms of wallets, user interfaces, mobile apps, token listings, and trading pairs. Those are visible components. The matching engine is invisible. Yet it is the component that dictates almost every performance characteristic users experience.
Its job sounds simple: maintain an order book and match buyers with sellers.
The implementation is anything but simple.
Once trading volume reaches meaningful scale, every microsecond begins to matter. Memory allocation matters. Cache locality matters. Network hops matter. Serialization costs matter. Lock contention matters. Tiny inefficiencies that are irrelevant in most applications become measurable sources of latency.
This is why large exchanges rarely evolve into a single monolithic system. Eventually, too many responsibilities compete for the same resources. User authentication, market data distribution, wallet operations, liquidation systems, compliance workflows, reporting pipelines, and account management all begin demanding their own operational boundaries.
The architecture fragments by necessity.
What emerges is usually some variation of a distributed service ecosystem connected through events.
An order arrives.
A validation service checks it.
An event is published.
The matching engine consumes that event.
A trade occurs.
More events appear.
Balances change.
Risk engines recalculate exposure.
Market data systems update downstream consumers.
Audit systems persist records.
Notification services inform users.
The actual trade may complete in milliseconds while dozens of independent subsystems continue processing the consequences long afterward.
This approach scales remarkably well because responsibilities remain isolated. A reporting service can fail without necessarily affecting order execution. A notification backlog doesn't need to slow a matching engine.
The downside is operational complexity.
I've spent enough time around distributed systems to be suspicious whenever someone describes an event-driven architecture as elegant. It often is elegant—right up until something goes wrong.
Tracing failures across asynchronous boundaries can become surprisingly difficult. A delayed message queue might surface as a balance inconsistency. A dependency timeout might manifest as a missing notification. A retry mechanism designed to improve reliability can accidentally amplify traffic during periods of stress.
The larger the system becomes, the more difficult it becomes to understand causality.
Data management introduces another layer of trade-offs.
There is a persistent myth that scaling problems are solved by choosing the right database. Reality is messier. Different parts of the system need entirely different storage characteristics.
User identities, compliance records, account histories, financial reports, and audit trails demand strong durability guarantees. Losing this information is unacceptable. Consistency is often more valuable than speed.
Trading systems have different priorities.
Order books and active market state are performance-sensitive structures. Pulling them from persistent storage during execution would introduce unacceptable latency. Keeping them in memory is the obvious answer, but that immediately creates a second challenge: maintaining consistency between fast-moving in-memory state and slower durable storage layers.
Eventually the architecture starts looking less like a database and more like a collection of databases with different jobs.
One system stores truth.
Another stores speed.
Another stores history.
Another stores analytical projections derived from historical activity.
Synchronizing these worlds becomes one of the most difficult engineering problems in the stack.
State synchronization is rarely discussed outside engineering circles, yet it quietly determines how reliable a platform feels. Users assume balances are correct. Positions are correct. Trade histories are correct. Achieving that consistency across multiple distributed storage layers operating at different speeds is far more difficult than the interface suggests.
Latency, meanwhile, becomes an obsession.
Not because engineers enjoy chasing benchmark numbers, but because latency compounds.
A few milliseconds here.
A few milliseconds there.
An unnecessary network round trip.
An overloaded cache.
A poorly placed dependency.
Individually these are minor inconveniences. Collectively they shape the experience of an entire platform.
Fast systems are rarely built through revolutionary breakthroughs. More often they emerge from relentless elimination of friction. Data stays in memory longer. Services communicate more efficiently. State moves through streams instead of repeated database queries. Critical paths become shorter. Background work becomes asynchronous.
Most users never notice these optimizations.
They only notice when they're absent.
The blockchain integration layer introduces its own set of architectural compromises.
There is often a tendency to frame systems as either on-chain or off-chain, but large exchanges don't fit neatly into either category. Binance exists in a space between those definitions.
Deposits require blockchain interaction.
Withdrawals require blockchain interaction.
Custody operations require blockchain interaction.
Most trading activity does not.
This separation isn't ideological. It's practical.
Blockchains solve settlement problems exceptionally well. They solve high-frequency execution problems rather poorly. Moving every operation onto a public chain would improve transparency while simultaneously degrading performance to a level most users would find unacceptable.
Somewhere along the way, every large crypto platform discovers that user experience and settlement architecture are not the same thing.
The user experiences instant execution.
Settlement reality is considerably more complicated.
The API layer acts as the bridge between these worlds.
From the outside, APIs appear straightforward. Applications consume them. Trading bots consume them. Institutions consume them.
Internally, they become a control plane responsible for regulating traffic, protecting critical infrastructure, managing access patterns, enforcing rate limits, and preventing localized failures from spreading through the platform.
As volume grows, APIs stop being simple communication mechanisms and start becoming load-balancing instruments for the entire system.
What makes this particularly challenging is that normal operating conditions are almost irrelevant.
Markets are calm until they aren't.
The moments that define exchange reliability usually arrive during periods of panic, euphoria, or extreme volatility. Those moments generate nonlinear behavior. Traffic doesn't increase gradually. It explodes.
Order submissions surge.
Market data volume surges.
Liquidation activity surges.
Withdrawal requests surge.
External blockchains become congested.
Dependencies begin operating under assumptions they were never designed to handle.
This is where distributed systems reveal their true personalities.
Rarely does a single component fail in isolation.
Failures cascade.
A delayed queue increases latency.
Latency triggers retries.
Retries generate additional load.
Additional load creates bottlenecks elsewhere.
Caches become stale.
State propagation slows.
Observability systems begin reporting symptoms long after root causes have already started spreading.
By the time users notice a problem, the underlying chain of events may have begun minutes earlier.
The challenge facing Binance isn't merely scaling infrastructure. Infrastructure can be purchased. Capacity can be added. Compute resources can be expanded.
Complexity accumulates differently.
Every optimization introduces a dependency.
Every dependency introduces a failure mode.
Every scaling solution creates another coordination problem that must eventually be monitored, maintained, and understood by someone at three o'clock in the morning during a market event.
Maybe that's the most fascinating aspect of systems like Binance. Their greatest achievement isn't transaction volume or market share. It's the ability to keep an increasingly complicated machine operating while hiding most of that complexity from the people using it.
The interface presents a simple illusion: click a button, place a trade, see a balance update.
Behind that button sits a sprawling collection of matching engines, event streams, state synchronization mechanisms, caching layers, databases, risk systems, settlement pipelines, blockchain integrations, monitoring infrastructure, and operational safeguards all attempting to stay coherent in real time.
The public narrative around crypto often revolves around protocols, consensus algorithms, and token economics. Those things matter. Yet when systems reach Binance's scale, the harder problems tend to look surprisingly familiar. Distributed coordination. Consistency. Latency. Reliability. Failure containment. Observability.
The blockchain is part of the architecture, but it is not the architecture.
What ultimately determines whether a platform survives years of growth is not how elegantly it settles transactions. It's whether the invisible layers underneath can continue absorbing complexity faster than complexity accumulates.