Sigo mirando @OpenLedger y tratando de averiguar si realmente han resuelto una compensación justa para los contribuyentes de datos de IA o si solo han hecho que la extracción sea más transparente sin hacerla menos extractiva.
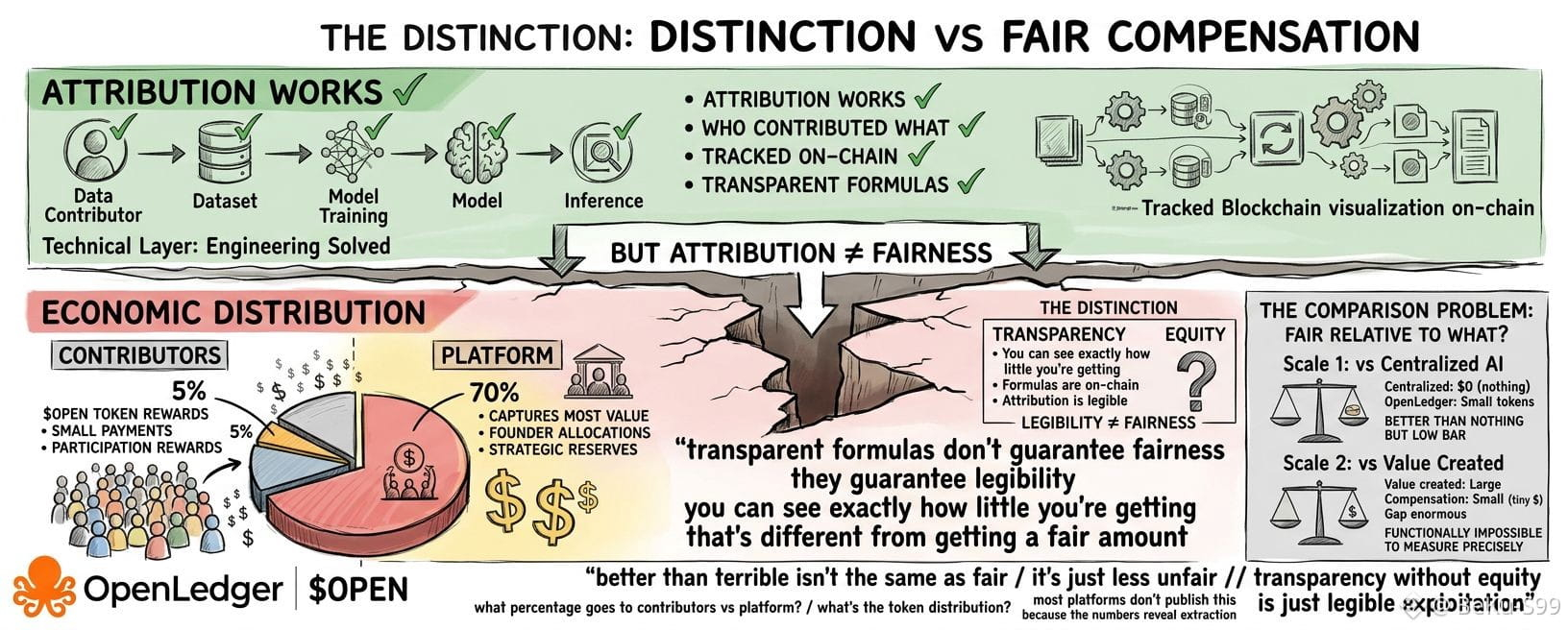
Lo que estoy observando no es si la atribución funciona técnicamente. Rastrear quién contribuyó qué datos a qué modelo es un problema de ingeniería que se puede resolver. Lo que estoy mirando es si la división económica que resulta de esa atribución representa una verdadera equidad o si es una extracción favorable para la plataforma con un mejor registro.
El problema de la compensación justa en la IA descentralizada.
No el mecanismo de atribución. La pregunta fundamental es si el rastreo de contribuciones se traduce en una distribución justa del valor o si las plataformas aún capturan la mayor parte del valor mientras los contribuyentes obtienen tokens que representan reclamos fraccionarios sobre economías que no controlan.
Esa distinción importa porque la transparencia sin equidad es solo explotación legible.
OpenLedger dice que los contribuyentes son compensados cuando sus datos entrenan modelos y cuando esos modelos generan inferencia. Las cargas de datos se verifican en la cadena. Cada interacción de IA se convierte en un evento monetizable para las personas que contribuyeron.
Lo que no puedo decir es si "evento monetizable" significa que los contribuyentes capturan un valor justo o si significa que reciben pequeños pagos en tokens mientras la plataforma captura la economía real.
El desafío es que "justo" requiere comparación. ¿Justo en relación a qué? ¿Justo comparado con contribuir a IA centralizada donde no obtienes nada? Esa es una barra baja. ¿Justo comparado con el valor que tu contribución crea? Eso requiere saber qué parte del rendimiento del modelo proviene de tus datos específicos, lo cual es prácticamente imposible de determinar con precisión.
La mayoría de las plataformas descentralizadas resuelven esto creando fórmulas de asignación de tokens. Tu contribución se pesa mediante algún algoritmo. Recibes tokens proporcionales a ese peso. La fórmula es transparente y está en la cadena.
Pero las fórmulas transparentes no garantizan equidad. Garantizan legibilidad. Puedes ver exactamente cuánto estás recibiendo. Eso es diferente de obtener una cantidad justa.
@OpenLedger usa $OPEN tokens para gobernanza y compensación. Los contribuyentes ganan tokens basados en su participación en datanets, entrenamiento de modelos y atribución de inferencias.
Lo que estoy observando es si esos incentivos realmente se alinean o si crean la apariencia de alineación mientras mantienen la extracción favorable para la plataforma.
La mayoría de las plataformas tokenizadas tienen este problema. Los primeros contribuyentes obtienen propiedad significativa cuando los tokens son baratos. Los contribuyentes tardíos obtienen recompensas de participación que no representan una captura de valor significativa.
Quizás OpenLedger haya evitado esto. Quizás su distribución de tokens crea una propiedad amplia.
Quizás no lo han hecho y este es el manual estándar de cripto. Lanzar con una narrativa de descentralización. Distribuir tokens para la apariencia de participación. Mantener el control a través de asignaciones de fundadores.
Preferiría ver los números reales. ¿Qué porcentaje de los ingresos por inferencia va a los contribuyentes de datos frente a la plataforma? ¿Cuál es la distribución de la propiedad de tokens?
La mayoría de las plataformas no publican esto porque los números revelan la extracción.
Los intereses para la economía de los contribuyentes dependen de si la compensación es competitiva con las alternativas. Si contribuyo datos a OpenLedger, ¿gano más que contribuyendo a plataformas centralizadas?
Si la compensación es mejor que las alternativas, eso valida el modelo.
Si la compensación no es mejor, entonces la propuesta de valor es ideológica, no económica. Participas porque prefieres la extracción transparente sobre la extracción opaca.
La mayoría del trabajo de datos de IA paga muy poco. Etiquetar datos para plataformas centralizadas es un trabajo de bajos salarios sin equidad. Si OpenLedger paga un poco más y da potencial de tokens, eso podría ser una mejora incluso si no es justo.
La capa de atribución es una tecnología interesante. Poder rastrear qué datos contribuyeron a qué salidas del modelo es genuinamente útil.
Si eso se traduce en una compensación justa o solo en una extracción más sofisticada depende de la estructura económica construida encima.
Estoy observando para ver en cuál se convierte OpenLedger.
Lo que estoy observando particularmente es el comportamiento de los contribuyentes. Si las personas siguen contribuyendo después de entender la economía, eso sugiere que la compensación funciona. Si la contribución disminuye una vez que las personas calculan los retornos, eso sugiere que no funciona.
La pregunta de la compensación es fundamental. Puedes construir una infraestructura de atribución impresionante. Puedes rastrear cada contribución con precisión. Si la división económica que resulta de esa precisión no compensa de manera justa a los contribuyentes, solo has hecho que la extracción sea más eficiente.
Y honestamente, confío más en las plataformas que publican claramente su distribución de valor que en las plataformas que enfatizan la transparencia sin mostrar quién captura el valor.
