Sigo observando @OpenLedger y tratando de averiguar si las datanets contribuidas por la comunidad producen datos de calidad o si descentralizar la recolección de datos solo significa descentralizar basura a gran escala.
Lo que estoy observando no es si la infraestructura de atribución funciona. Rastrear quién contribuyó con qué es un tema de ingeniería resuelto. Lo que estoy observando es si los datos que se están contribuyendo son realmente valiosos o si incentivar la contribución crea cantidad sin calidad.
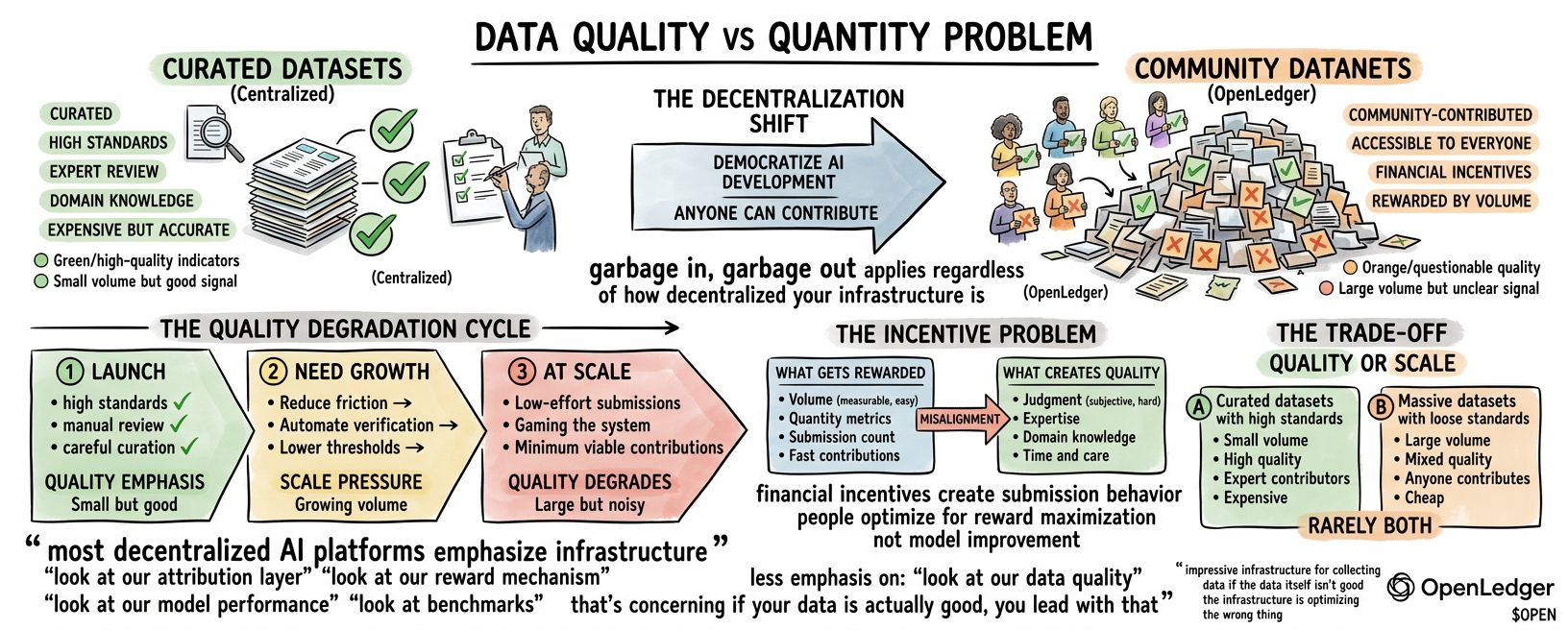
El problema de calidad de datos en la IA descentralizada.
No el mecanismo de verificación. El desafío fundamental de asegurar que cuando recompensas a las personas por contribuir datos, contribuyan buenos datos en lugar de manipular el sistema de recompensas con envíos de bajo esfuerzo que pasan estándares mínimos pero no mejoran el rendimiento del modelo.
Esa distinción importa porque lo que entra, sale aplica sin importar cuán descentralizada sea tu infraestructura.
OpenLedger permite que cualquiera cree datanets o contribuya a las existentes. Los contribuyentes suben datos, se verifican en la cadena y ganan recompensas. Cuanto más contribuyes, más ganas.
Lo que no puedo decir es si "accesible para todos" produce conjuntos de datos valiosos o si produce ruido que diluye la señal.
El desafío es que los incentivos financieros crean un comportamiento de envío. Cuando pagas a las personas para que contribuyan datos, contribuyen datos. Pero los datos que contribuyen se optimizan para la maximización de recompensas, no necesariamente para la mejora del modelo.
La mayoría de la recolección de datos crowdsourced enfrenta este problema. Necesitas volumen. Así que bajas las barreras. Premias la cantidad.
Y recibes envíos de bajo esfuerzo. Manipulando el sistema. Contribuciones viables mínimas que califican para el pago pero no añaden valor.
@OpenLedger tiene mecanismos de verificación. Los datos se revisan. Hay control de calidad.
Lo que estoy observando es si esos mecanismos funcionan a gran escala o si funcionan inicialmente y se desmoronan cuando el volumen aumenta y la verificación se vuelve costosa en relación con las recompensas.
La mayoría de las plataformas comienzan con altos estándares. Luego necesitan crecer. Así que reducen la fricción. Automatizan la verificación.
Y la calidad se degrada. Gradualmente. El conjunto de datos crece pero la calidad promedio de las contribuciones disminuye.
Quizás OpenLedger ha resuelto esto. Quizás su verificación escala sin degradación.
Quizás no lo han hecho y están enfrentando el mismo dilema. Calidad o escala. Puedes tener conjuntos de datos curados con altos estándares. O conjuntos de datos masivos con estándares laxos. Rara vez ambos.
Los riesgos para el rendimiento del modelo dependen de si los incentivos de contribución se alinean con la calidad o solo con la cantidad. Si las recompensas se correlacionan con la mejora real del modelo, los contribuyentes se optimizan para la calidad. Si las recompensas se correlacionan con el volumen, los contribuyentes se optimizan para el volumen.
La mayoría de los sistemas de recompensa se optimizan para cosas medibles. El volumen es medible. La calidad es subjetiva. Así que los sistemas premian el volumen y esperan que la calidad lo siga.
Generalmente no lo hace. La calidad requiere juicio. Experiencia. Conocimiento del dominio. Tiempo. Esos son caros. El volumen es barato.
Preferiría ver evidencia de que las datanets de OpenLedger producen mejores modelos que las alternativas centralizadas. No solo conjuntos de datos más grandes. Mejor rendimiento del modelo.
Si los modelos entrenados con datos de OpenLedger funcionan de manera similar o peor, entonces la descentralización no está añadiendo valor.
La pregunta de la calidad de los datos importa porque los modelos de IA son solo tan buenos como sus datos de entrenamiento. Puedes tener una infraestructura perfecta, atribución transparente, compensación justa. Si los datos subyacentes son mediocres, tus modelos serán mediocres.
La mayoría de las plataformas de IA descentralizadas enfatizan su infraestructura. Mira nuestra capa de atribución.
Menos énfasis en: mira nuestra calidad de datos. Mira el rendimiento del modelo.
Eso es preocupante. Si tus datos son realmente buenos, lideras con eso. Si tu infraestructura es impresionante pero tus datos son cuestionables, hablas de infraestructura.
Quizás OpenLedger tiene datos sólidos. Quizás sus modelos funcionan bien. Quizás no he visto los benchmarks porque aún no los han publicado.
Quizás los datos son mediocres y esperan que los volúmenes compensen la calidad.
Eso podría funcionar para algunos casos de uso. Más datos pueden superar una calidad inferior si tienes suficiente capacidad de cómputo.
No funciona para dominios especializados. Datos médicos, datos legales, datos científicos. No puedes compensar las contribuciones de baja calidad con volumen.
Estoy observando para ver qué tipo de IA se convierte OpenLedger. ¿Modelos genéricos donde el volumen importa? ¿O modelos especializados donde la calidad es crítica?
La pregunta de la calidad de los datos es fundamental. Puedes construir una infraestructura impresionante para recolectar y atribuir datos. Si los datos en sí no son buenos, la infraestructura está optimizando lo incorrecto.
Y honestamente, confío en las plataformas que enfatizan el rendimiento del modelo sobre las plataformas que enfatizan la infraestructura mientras evitan comparaciones de rendimiento.
