

He estado investigando los Datanets de OpenLedger últimamente y me tomó más tiempo del que esperaba realmente entender por qué esta configuración se siente diferente.
He seguido el proyecto desde la lista en Binance el septiembre pasado, vi el lanzamiento de la mainnet en noviembre, y he estado monitoreando el token. Pero la capa de datos es donde las cosas realmente empiezan a tener sentido una vez que haces zoom.
Lo que noté hoy
Los Datanets son básicamente redes de datos específicas de dominio, propiedad de la comunidad, que viven en la cadena. Puedes crear uno o unirte a uno existente — cosas como pools enfocados en Inteligencia de Datos, Creadores, Desarrolladores de Web3 o DePIN. Los contribuyentes aportan datos (texto, imágenes, documentos, etiquetas), los validadores chequean la calidad, y los propietarios establecen las reglas para ese nicho.
La pieza que destaca es la Prueba de Atribución. Cuando un modelo se entrena o realiza inferencias sobre datos de estos pools, la cadena registra qué contribuciones realmente influyeron en el resultado y en qué medida. Luego, los contratos inteligentes manejan los pagos automáticos a las personas que proporcionaron los datos. Sin hojas de cálculo, sin promesas de 'confía en mí más tarde'. Está diseñado para hacer que los datos sean líquidos y pagables.

El mainnet ha estado en vivo desde mediados de noviembre. El testnet ya mostró una escala real con más de 25 millones de transacciones y millones de nodos. Hoy $OPEN se está negociando alrededor de $0.212, subiendo aproximadamente un 2% en las últimas 24 horas con más de $33 millones en volumen. La capitalización de mercado se sitúa cerca de $45 millones con alrededor de 215 millones de tokens circulando. Aún estamos aproximadamente un 88% por debajo del ATH de $1.82 desde el día de listado en Binance, pero el volumen se ha mantenido decente incluso a través de la caída.

La mayoría de los proyectos de AI-crypto se enfocan en la computación, agentes o simplemente le ponen 'descentralizado' a un mercado de modelos. $OPEN Ledger está tratando de resolver el verdadero problema de los datos desde la raíz: la parte que actualmente está dominada por scraping centralizado sin compensación para las personas que crearon los datos.
La capa de atribución cambia el incentivo. En lugar de esperar que alguien te acredite más tarde, tu contribución se rastrea y recompensa proporcionalmente cada vez que se utiliza. Eso convierte conjuntos de datos estáticos en algo que puede seguir generando. También hace que los datos especializados y de alta calidad sean más valiosos, porque los Datanets específicos de dominio deberían producir mejores resultados que las extracciones genéricas.
El volumen manteniéndose por encima de $30M mientras el precio está tan bajo me dice que todavía hay un interés genuino, no solo hype de listado. El hecho de que el mainnet ha estado funcionando durante seis meses sin drama importante también es digno de mención; muchas cadenas de IA todavía prometen infraestructura que aún no existe.
Dicho esto, la adopción aún está en sus inicios. No tenemos números públicos masivos sobre cuántos modelos están extrayendo activamente de Datanets en vivo o cuánto se está pagando diariamente. La ejecución del lado del contribuyente decidirá si esto se queda como una idea genial o se convierte en un uso real.
Soy cautelosamente optimista. El diseño de incentivos en torno a la propiedad de datos y las recompensas automáticas se siente más limpio que la mayoría de las narrativas en este espacio. No creo que vaya a cambiar toda la industria de IA de la noche a la mañana, pero aborda un verdadero punto de dolor que los actores centralizados han ignorado durante años.
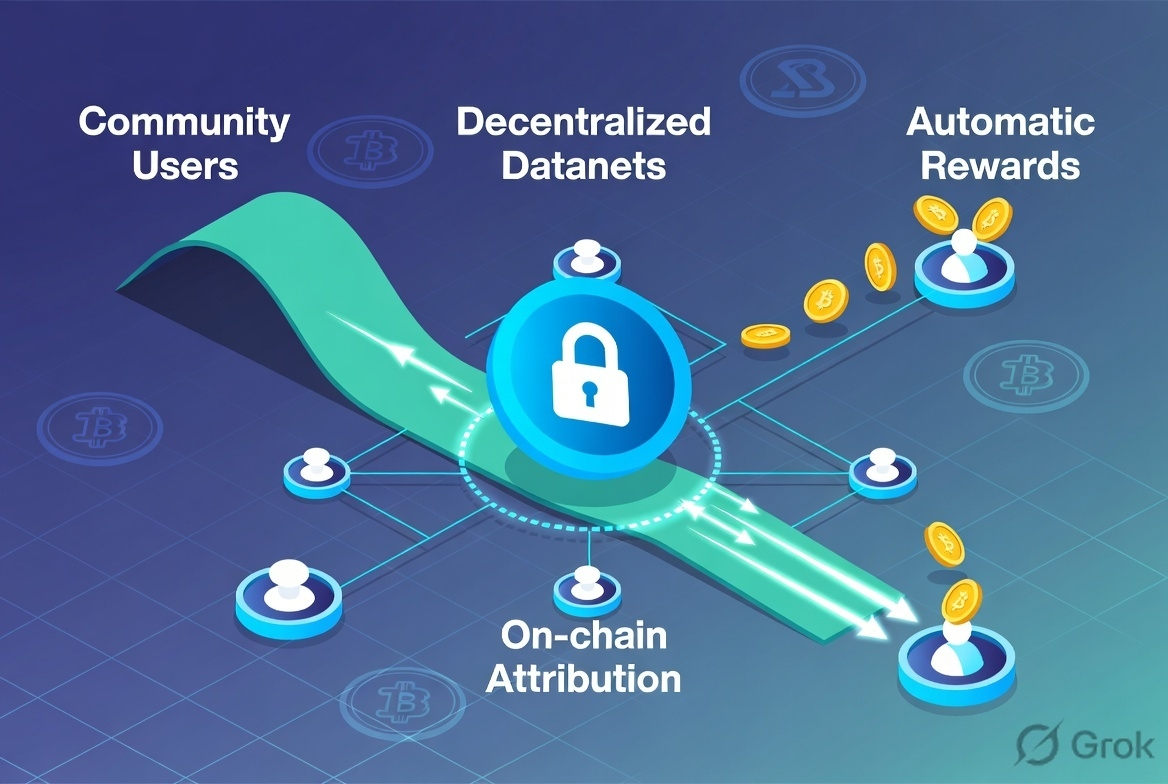
Hoy agregué un poco más a mi posición después de dedicar tiempo a mapear cómo un Datanet simple realmente fluye desde la contribución hasta el pago. Todavía estoy observando de cerca, sin embargo; si la mecánica de atribución y recompensa funciona en la práctica, esto podría acumularse muy bien. Si se queda mayormente teórico, el token seguirá en modo 'grind'.
¿Qué te está deteniendo realmente para contribuir con datos o comenzar tu propio Datanet ahora mismo? ¿Has revisado el flujo del contribuyente ya, o todavía se siente demasiado temprano/complicado? Deja tus pensamientos honestos; tengo curiosidad por lo que otros están viendo.