A la una de la mañana, todavía estaba en la cama revisando mi celular, con la cabeza llena de cosas sobre @OpenLedger . No era nada técnico de un whitepaper, solo pensaba: ¿qué tan difícil es realmente para un proyecto usar incentivos para obtener datos humanos de alta calidad?
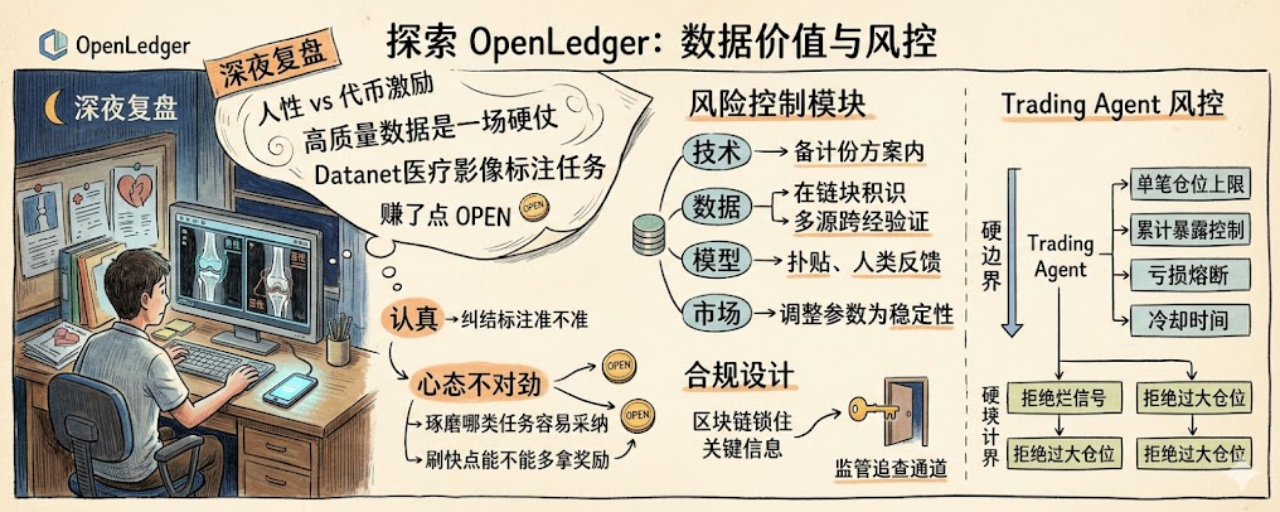
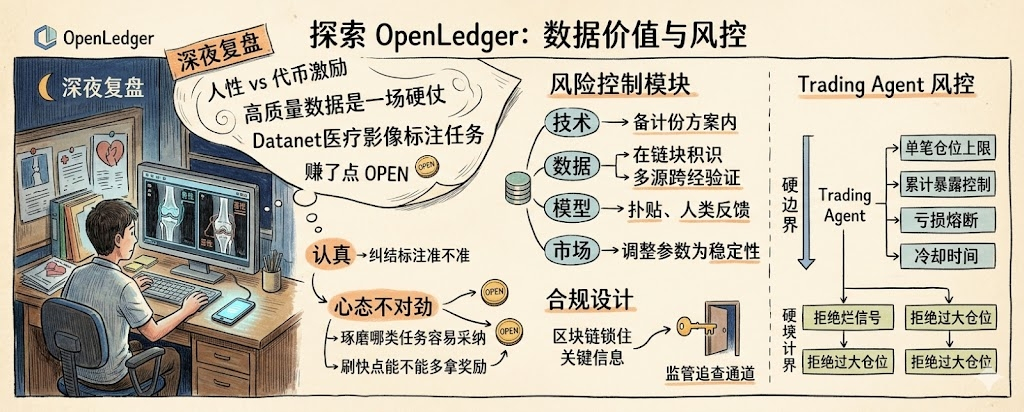
El mes pasado, estuve en modo chill y agarré un par de tareas de etiquetado de imágenes médicas en Datanet, y gané un poco de OPEN. Al principio me lo tomé en serio, revisaba cada imagen con cuidado, pensando que por fin mis conocimientos podrían traducirse en algo de valor. Pero a las dos semanas, me di cuenta de que mi mentalidad había cambiado; ya no me preocupaba tanto por la precisión del etiquetado, sino que empecé a pensar en qué tipo de tareas eran más fáciles de aceptar, si podía acelerar el proceso para obtener más recompensas, o si debía elegir trabajos más simples para subir mi contribución. Este cambio fue tan natural que hasta me asustó un poco.
Definitivamente no es un problema mío, es un bache natural del mecanismo de incentivos. El PoA de OpenLedger, los Datanets, y OpenTask, su suposición central es que todos contribuirán de forma real a largo plazo. Pero en la realidad, una vez que el comportamiento se cuantifica en puntos y tokens, las personas tienden a optimizar el 'puntaje' en lugar de la 'calidad'. Los proyectos de incentivos de contenido como Steemit son un ejemplo; cuando las recompensas bajan, los usuarios se van. En las testnets de Web3, inflar los números es la norma. Especialmente con datos subjetivos, emociones, preferencias y esas expresiones sutiles, esas cosas valiosas se distorsionan más cuanto más se recompensan. Las imágenes médicas están bien, tienen estándares objetivos, pero cuando se trata del verdadero feedback humano, es realmente frágil.
Por supuesto, el equipo del proyecto también ha considerado contramedidas. En el whitepaper mencionaron un mecanismo de validadores y la validación cruzada de múltiples fuentes, al menos para reducir el impacto de un único fraude. La colaboración con Astro AI y Netmarble también es una buena señal; si realmente hay empresas dispuestas a pagar por datos de alta calidad, eso sería el ancla más sólida, no tendrían que depender solo de los tokens. Pero por ahora, las pruebas concretas no son suficientes, así que me mantengo a la expectativa.$OPEN Ha habido una caída considerable en el último año; el mercado ha votado con los pies, y lo que está votando es en realidad la desconfianza hacia si 'los humanos pueden ser incentivados a contribuir verdaderamente a largo plazo'.
Sin embargo, después de leer el whitepaper, la parte sobre el control de riesgos realmente me sorprendió.
Dividen el riesgo en cuatro módulos: técnico, datos, modelo y mercado, cada uno con un plan de respuesta específico: si hay problemas técnicos, hay un plan de respaldo; si hay falsificación de datos, se puede rastrear en la cadena; el modelo tiene un mecanismo de parches; y en caso de volatilidad del mercado, se pueden ajustar parámetros para estabilizar. Esta estructura tiene un alto umbral, es un poco difícil para los novatos, pero es sólida. El diseño regulatorio también es interesante, ya que deja un canal de seguimiento para los reguladores y usa blockchain para bloquear información clave, lo que les da una especie de seguro en este entorno actual. No es la forma más 'descentralizada', pero es más pragmática, adecuada para proyectos que quieren durar.
El sistema económico es el corazón: la plataforma puede ajustar precios y suministro de tokens de manera flexible, cuantas más herramientas en el ecosistema, más fuerte es la capacidad de resistir riesgos. Por supuesto, en un mercado bajista, incluso el mejor algoritmo no puede soportar la fuga masiva de los usuarios; eso es algo que todos saben. En general, OpenLedger sigue una ruta de pasos firmes, como un corredor de fondo, adecuada para quienes entienden las reglas y pueden soportar, no para los apostadores que buscan hacerse ricos de la noche a la mañana.
Hablando de la parte del Trading Agent, personalmento estoy muy atento a su lógica de gestión de riesgos.
He desglosado varias estrategias de trading automático y lo que más temo es el 'perder por exceso de diligencia', donde las llamadas en la cadena parecen emocionantes, pero la cuenta está sangrando en silencio. Un buen Agent no es solo aquel que ejecuta órdenes rápidamente, sino que debe tener límites estrictos: límite de posición por operación, exposición acumulada controlada (se deben consolidar las mismas fuentes de señal, activos y estrategias), mecanismos de cortocircuito en pérdidas, y tiempos de enfriamiento. Estas no son medidas conservadoras, son cosas que salvan vidas. Especialmente la fuente de señales debe ser tratada de manera diferenciada; la estabilidad de la fuente y la cantidad que puede ofrecer en redes sociales son completamente diferentes. Cuando gasto OPEN, espero obtener un registro de ejecución claro, un registro de rechazos y un análisis posterior, no solo un botón automático.
Un Agent que puede rechazar señales malas, rechazar posiciones demasiado grandes, y rechazar seguir adelante después de errores consecutivos, es el que merece confianza. Correr rápido no es difícil, lo impresionante es poder detenerse cuando te estás equivocando.
En términos generales, estoy de acuerdo con la dirección de OpenLedger. En la era de la IA, la prueba de atribución y la retroalimentación humana de alta calidad son realmente necesidades esenciales. Pero el éxito no se mide por cuántos DAU tenemos, sino por dos cosas: la retención real de usuarios y la tendencia de calidad en los Datanets, así como la frecuencia de recompra de los clientes empresariales. La demanda real es el mejor incentivo. (Este artículo es una tarea de la plataforma y no constituye ningún consejo de inversión.)#OpenLedger