
我想先说一件让我有点尴尬的事。
我研究 @OpenLedger 挺久了,PoA 机制、Datanets、持久内存这些我都认真看过。但 OpenLoRA 这个模块,我之前一直没放在心上。我的第一反应是"模型部署工具,技术细节,不影响投资逻辑",然后就跳过去了。直到前几天我跟一个在做垂直 AI 应用的朋友聊天,他跟我抱怨推理成本快把他们搞死了,我才突然把这两件事连起来,重新回去把 OpenLoRA 的文档认真读了一遍。我读完之后的第一反应是:我之前完全搞错了重点。
我们先来说一个很多人没亲身经历过的现实。微调一个大语言模型,这件事现在已经不难了,门槛越来越低,工具越来越多。但微调完之后呢?你得把这个模型部署起来,让它能响应用户请求。而部署一个专属微调模型,意味着你需要一张独占的 GPU 一直在线等着处理推理请求。AWS 或者 GCP 上一张 A100,一个月下来要几千美元,而且你的模型大多数时候可能是空转的,根本跑不满。我认识的好几个小团队,微调出了挺不错的专属模型,最后因为养不起这张 GPU,只能把模型束之高阁,继续去调 OpenAI 的 API。这个结局我觉得挺讽刺的——你花了时间和数据训练出了一个属于你自己的东西,但你用不起它。OpenLoRA 要解决的,正好是这个问题。#OpenLedger
它的核心是多租户架构。我用一个比较直白的方式解释——普通的模型部署是你包了一整栋楼,不管有没有人住,租金每个月都得交。OpenLoRA 做的事情是把这栋楼改成分时出租的公寓,每个租户只占一个房间,共享楼道、电梯、水电,按实际使用量付费。在技术上,它通过优化推理框架,让单张 GPU 可以同时承载几千个不同的微调模型,每个模型在被调用的时候才真正占用计算资源,不用的时候几乎不产生成本。
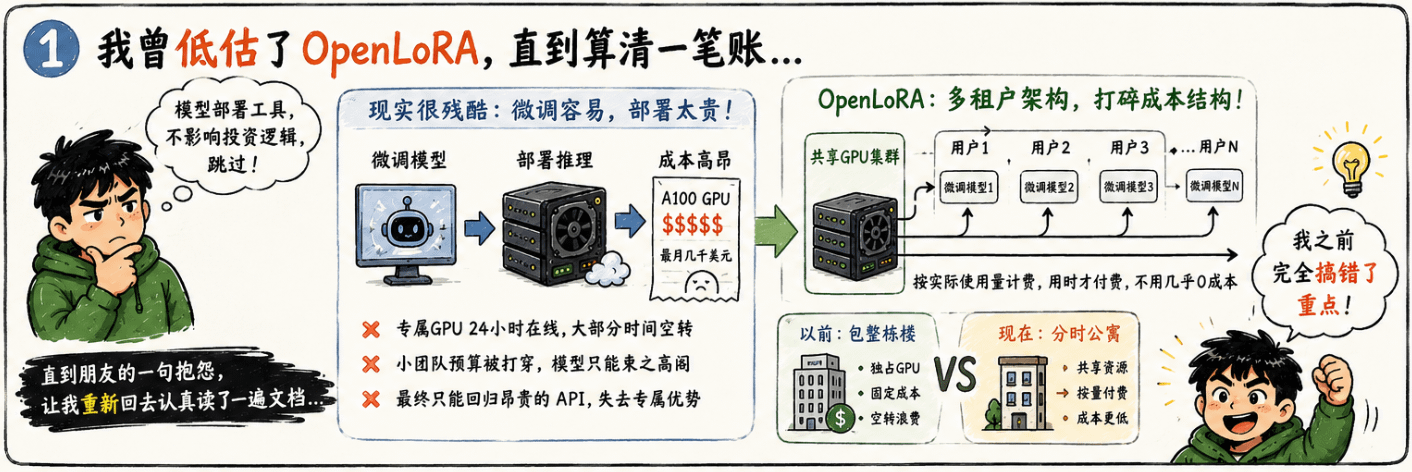
我在想这件事的商业意义的时候,脑子里出现了一个画面。以前 AI 推理这件事,只有大公司玩得起——他们有足够的用量来摊薄 GPU 成本,有足够的工程师来优化部署效率。小团队和个人开发者只能用别人家的 API,用别人训练好的通用模型,永远没有属于自己的专属智能。OpenLoRA 如果真的能把多租户推理这件事跑通,我觉得它实际上是在做一件更大的事:把专属 AI 模型的使用权,从资本密集型的大公司手里,还给那些有数据、有想法但没有大预算的普通开发者和小团队。
这件事和 OpenLedger 整体的叙事逻辑是完全咬合的。我之前理解 OpenLedger 的核心价值是"数据贡献者获得报酬",现在我觉得这只是它想做的事情的一半。另一半是:让训练出来的模型真正能被用起来,而不是因为推理成本太高被锁在硬盘里。Datanets 解决数据层,ModelFactory 解决训练层,OpenLoRA 解决部署层——我现在才算真正把这三件事串起来,理解了为什么它们要放在同一个生态里。
当然我也有我的疑问。几千个模型共享一张 GPU,在并发请求量突然拉满的时候,延迟和稳定性怎么保证?多租户之间的数据隔离是否足够安全?这些问题我在文档里没有找到特别详细的答案,是我目前还在观察的地方。
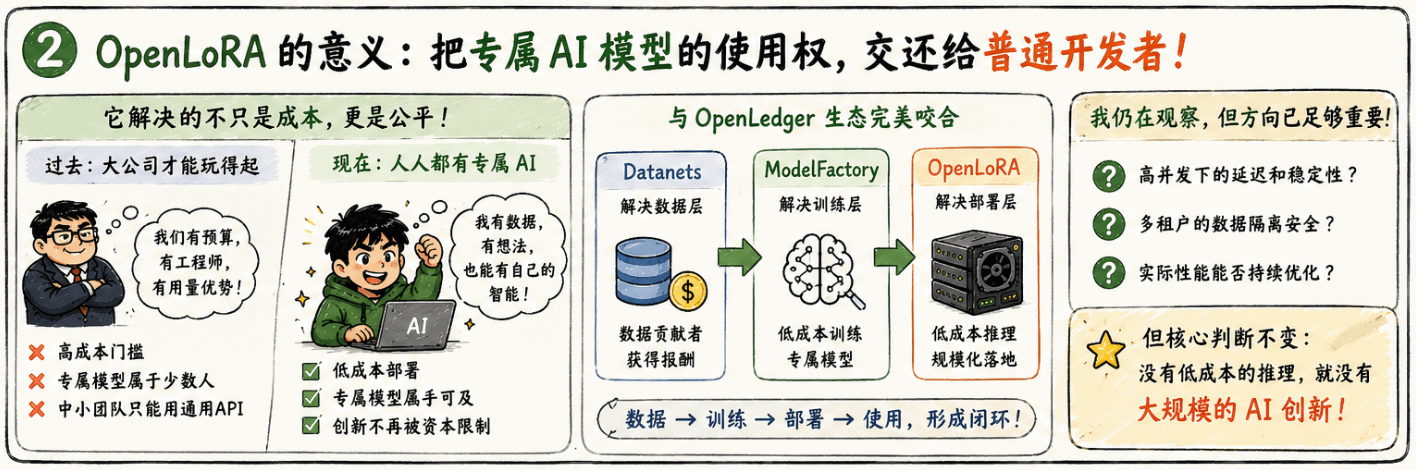
但我想说的核心判断是这个——我们平时讨论 OpenLedger 的时候,90%的内容都在讲 PoA 和数据贡献奖励,OpenLoRA 几乎只是被当成一个名词顺带提一句。我自己也犯了这个错误。但如果我们认真想一想 AI 推理成本这个问题在整个行业里有多普遍、多痛,我们就会意识到 OpenLoRA 不是一个配角,它是整个生态能不能真正跑起来的关键一环。一个让人训练出模型但用不起的系统,和一个让人训练完就能低成本跑起来的系统,长期来看根本不是同一个东西。