
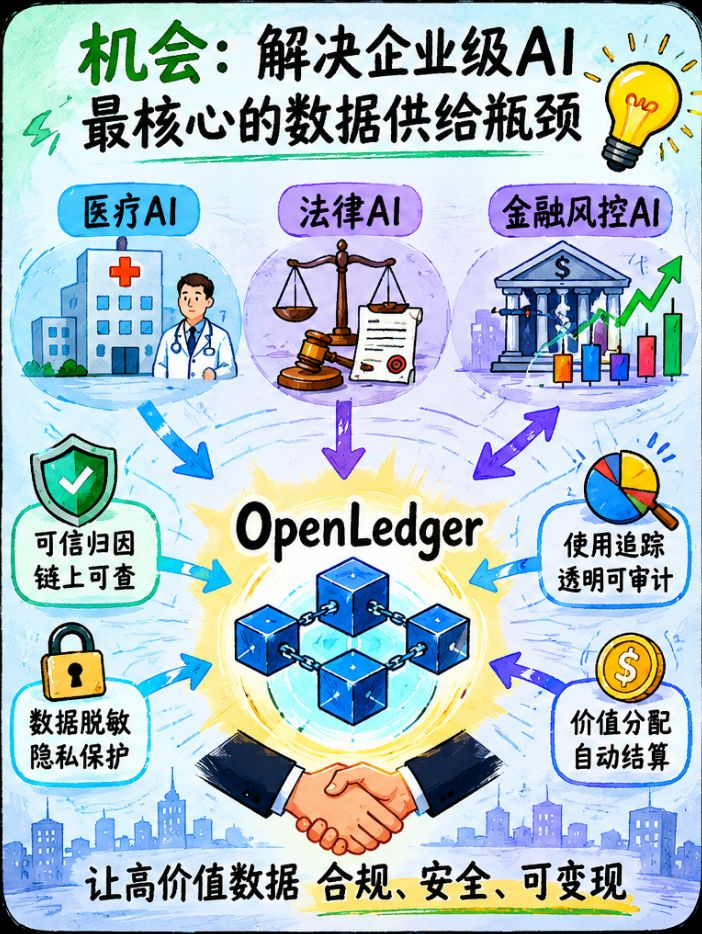
我有一个习惯,研究项目的时候喜欢找那种夹在文档中间、没有被重点标注、但信息密度很高的句子。因为官方重点强调的东西往往是他们希望你看到的,而那些随手写在技术说明里的细节,才是项目真实在做什么的线索。@OpenLedger 文档里有这么一句话,我截图存下来了——Datanet 的设计场景包括:法律合同片段(legal contracts)、医疗数据片段(medical snippets)、DeFi 漏洞案例(DeFi exploits)。
我盯着这句话看了很久。我们先说我的第一反应——我有点担心。不是那种"这个项目要完"的担心,而是"这个方向踩的地雷区我知道有多密"的担心。医疗数据这件事,在我研究过的几乎所有主要市场里,都是监管最严、法律风险最高的数据类型之一。美国有 HIPAA,欧盟有 GDPR,中国有《个人信息保护法》和《数据安全法》,这些法规对医疗数据的收集、存储、跨境传输都有极其严格的限制。把医疗数据片段上链,让 AI 模型训练调用,我很难想象这件事在现有的法律框架下能无摩擦地推进。
法律合同数据同样不简单。合同里包含的不只是条款,还有当事人身份、商业机密、交易结构,这些东西的保密义务在很多司法管辖区是有法律强制力的。律师事务所的数据上链,客户有没有授权?授权的边界在哪里?这些问题我在文档里没找到清晰的答案。

但我强迫自己翻过这一面之后,看到了另一面——而另一面让我重新认真对待这件事。我们想一想,为什么医疗 AI、法律 AI、金融风控 AI 这几个赛道,到现在为止都还没有出现真正意义上的统治性产品?不是因为需求不存在,而是因为数据太难获取。一个想做医疗诊断辅助 AI 的团队,最大的瓶颈不是算法,是高质量的标注医疗数据,而这些数据被医院、保险公司、药企牢牢锁着,根本拿不到。法律 AI 同理,高质量的合同数据、判决书数据、法律意见书数据,都被律所和法院关在自己的系统里,外面的人没有合法渠道拿到足够的量来训练一个真正好用的模型。这就是我真正想说的东西——OpenLedger 如果能在这些领域建立起一套可信的、有归因机制的、链上可验证的数据贡献和使用标准,它解决的不是"让普通人用数据赚点小钱"这个问题,而是整个企业级垂直 AI 市场最核心的数据供给瓶颈。#OpenLedger
我打个比方。现在全球有大量的医疗机构、律所、金融机构,他们手里有高价值数据,但他们没有一个可信的、有法律依据的方式把这些数据变现或者贡献给外部 AI 系统。他们担心数据泄露,担心合规风险,担心贡献出去之后没有归因和收益。OpenLedger 的链上归因和自动分配机制,从技术上恰好可以解决这几个担心——你的数据被用了多少次、被哪个模型用了、产生了多少价值,全部链上可查,收益自动结算。这个价值主张对企业端客户的吸引力,远大于对个人散户贡献者的吸引力。
我现在对这件事的判断是:方向大概率是对的,但执行路径极其复杂。合规问题不是靠技术能绕过去的,OpenLedger 需要在每个主要市场找到真正懂当地法律的合作方,需要在数据脱敏、隐私计算、访问控制这些技术层面做到远超现有 Web3 项目的标准,才有可能真正进入医疗和法律这两个领域。
Polychain 和 Borderless Capital 在后面,我不担心钱和格局的问题。我担心的是执行层面的速度和合规策略——这个赛道等不起,微软、谷歌、Oracle 都在往企业级 AI 数据基础设施这个方向使劲,OpenLedger 的窗口期不是无限的。我不确定它能不能做成。但我觉得如果它做成了,我们今天讨论的那些数据贡献赚钱的故事,会变成这个项目历史里很小的一章,真正的故事在垂直行业那边。