Un réseau de robots peut traiter des tâches rapidement et échouer stratégiquement si les mises à jour des politiques prennent du retard par rapport aux incidents réels.
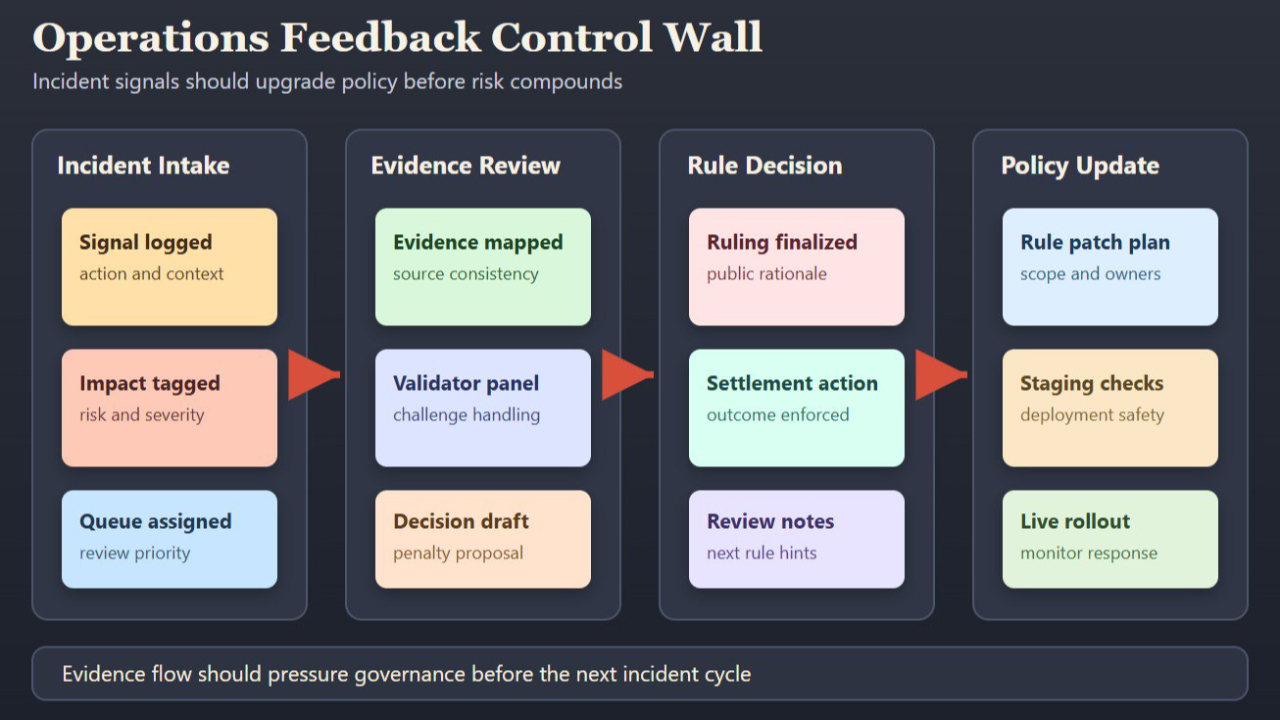
La plupart des systèmes considèrent la gouvernance comme une documentation statique alors que les opérations changent chaque semaine. Cet écart crée un risque silencieux. De nouveaux modes de défaillance apparaissent, les opérateurs improvisent et les règles s'éloignent de la réalité jusqu'à ce qu'un conflit majeur nécessite une intervention d'urgence. La rapidité n'est pas le goulet d'étranglement dans ce scénario. La réactivité de la gouvernance l'est.
Le cadre de Fabric est utile car il relie le retour d'exécution à un modèle de coordination public au lieu d'une boucle de comité fermée. Les mécaniques de défi, l'économie des validateurs et les voies de règles visibles créent une structure où les preuves des opérations peuvent exercer une pression sur les changements de politique avant que les dommages ne s'aggravent. C'est une thèse de fiabilité plus forte que "nous avons de bons modèles et de bonnes intentions."
Cela redéfinit aussi ma lecture de `$ROBO`. La valeur d'utilité et de gouvernance devrait venir d'une utilisation réelle de la surface de contrôle : participation à la supervision, alignement des incitations et continuité de l'évolution des règles sous pression. Si ces mécanismes sont actifs, le réseau peut s'améliorer grâce à la pression. S'ils sont inactifs, la gouvernance devient du branding.
Pour les équipes déployant des services robotiques de longue durée, la question pratique n'est pas de savoir si des incidents se produisent. Ils se produiront. La question clé est de savoir si chaque incident rend le système plus governable ou plus fragile.
Quand le prochain résultat contesté de robot passe en production, votre couche de politique s'adaptera-t-elle grâce à des preuves publiques, ou dépendra-t-elle d'exceptions privées et d'une réparation de confiance retardée ?
@Fabric Foundation $ROBO #ROBO