1. Introduction | Le Changement de Modèle-Couche dans Crypto AI
Les données, les modèles et le calcul forment les trois piliers fondamentaux de l'infrastructure AI—comparable à du carburant (données), un moteur (modèle) et de l'énergie (calcul)—tous indispensables. Tout comme l'évolution de l'infrastructure dans l'industrie AI traditionnelle, le secteur Crypto AI a suivi une trajectoire similaire. Au début de 2024, le marché était dominé par des projets GPU décentralisés (tels qu'Akash, Render et io.net), caractérisés par un modèle de croissance lourd en ressources axé sur la puissance de calcul brute. Cependant, d'ici 2025, l'attention de l'industrie s'est progressivement déplacée vers les couches de modèle et de données, marquant une transition d'une concurrence d'infrastructure de bas niveau vers un développement de couche intermédiaire plus durable et axé sur les applications.
Masters en droit généraliste vs. Masters en sciences spécialisées
Les modèles de langage traditionnels de grande taille (LLM) reposent fortement sur des ensembles de données massifs et des infrastructures d'entraînement distribuées complexes, avec des tailles de paramètres allant souvent de 70 à 500 milliards d'octets, et un seul entraînement coûtant des millions de dollars. À l'inverse, les modèles de langage spécialisés (SLM) adoptent un paradigme d'ajustement fin léger qui réutilise des modèles de base open source comme LLaMA, Mistral ou DeepSeek, et les combine avec des ensembles de données spécifiques au domaine, petits mais de haute qualité, et des outils comme LoRA pour construire rapidement des modèles experts à un coût et une complexité considérablement réduits.
Il est important de noter que les SLM ne sont pas intégrés aux pondérations des LLM, mais fonctionnent de concert avec ces derniers grâce à des mécanismes tels que l'orchestration par agents, le routage par plugins, les adaptateurs LoRa remplaçables à chaud et les systèmes RAG (génération augmentée par la récupération). Cette architecture modulaire préserve la large couverture des LLM tout en améliorant les performances dans des domaines spécialisés, permettant ainsi la création d'un système d'IA hautement flexible et composable.
Rôle et limites de l'IA cryptographique au niveau de la modélisation
Par nature, les projets d'IA cryptographique peinent à améliorer directement les capacités fondamentales des LLM. Cela s'explique par :
Obstacles techniques importants : l’entraînement des modèles de base nécessite des ensembles de données massifs, une puissance de calcul et une expertise en ingénierie – des capacités actuellement détenues uniquement par les principaux acteurs technologiques aux États-Unis (par exemple, OpenAI) et en Chine (par exemple, DeepSeek).
limitations de l'écosystème open sourceBien que des modèles comme LLaMA et Mixtral soient open source, les avancées majeures reposent encore sur des institutions de recherche externes et des processus d'ingénierie propriétaires. Les projets on-chain ont une influence limitée au niveau du modèle de base.
Cela dit, l'IA crypto peut tout de même créer de la valeur en affinant les modèles de vie sociale (SLM) à partir de modèles de base open source et en tirant parti des primitives Web3 telles que la vérifiabilité et les incitations basées sur les jetons. Positionnés comme la « couche d'interface » de la pile d'IA, les projets d'IA crypto contribuent généralement dans deux domaines principaux :
Couche de vérification fiable : l’enregistrement sur la chaîne des chemins de génération de modèles, des contributions de données et des enregistrements d’utilisation améliore la traçabilité et la résistance à la falsification des résultats de l’IA.
Mécanismes d'incitation : des jetons natifs sont utilisés pour récompenser les chargements de données, les appels de modèles et les exécutions d'agents, créant ainsi une boucle de rétroaction positive pour l'entraînement et l'utilisation des modèles.
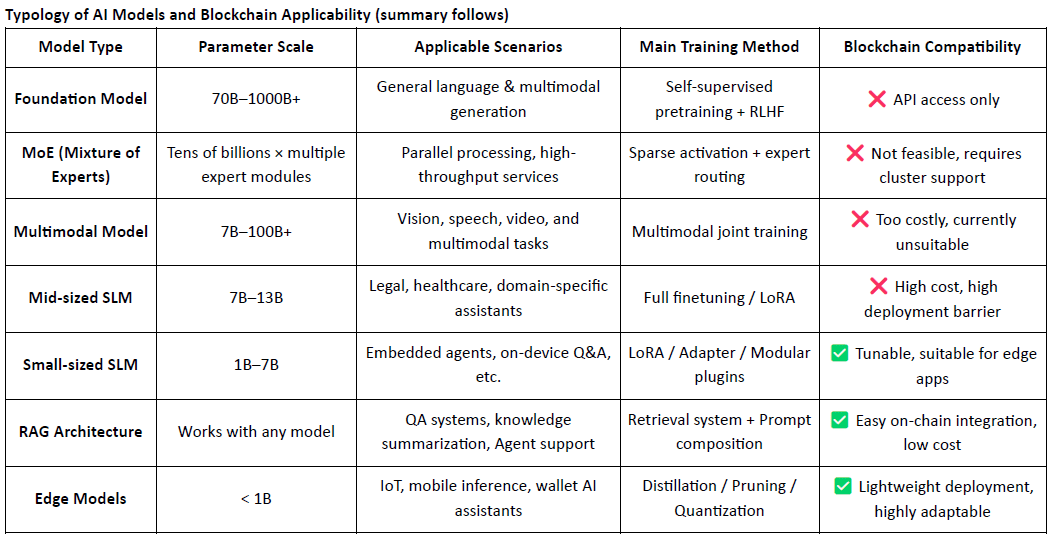
Les applications concrètes des projets d'IA crypto centrés sur les modèles se concentrent principalement dans trois domaines : l'optimisation légère de petits modèles logiciels, l'intégration et la vérification des données sur la blockchain via des architectures RAG, et le déploiement local et l'incitation des modèles périphériques. En combinant la vérifiabilité de la blockchain avec des mécanismes d'incitation basés sur des jetons, la crypto peut offrir une valeur unique dans ces scénarios de modèles à ressources moyennes et faibles, constituant ainsi un avantage concurrentiel au niveau de l'interface de la pile d'IA.
Une blockchain d'IA axée sur les données et les modèles permet un enregistrement transparent et immuable de chaque contribution, renforçant considérablement la crédibilité des données et la traçabilité de l'entraînement des modèles. Grâce aux contrats intelligents, elle déclenche automatiquement la distribution de récompenses à chaque utilisation de données ou de modèles, convertissant l'activité d'IA en une valeur tokenisée mesurable et échangeable – créant ainsi un système d'incitation durable. De plus, les membres de la communauté peuvent participer à la gouvernance décentralisée en votant sur les performances des modèles et en contribuant à la définition des règles et à l'itération grâce aux tokens.
2. Présentation du projet | La vision d'OpenLedger pour une chaîne d'IA
@OpenLedger est l'un des rares projets d'IA blockchain du marché actuel axés spécifiquement sur les mécanismes d'incitation liés aux données et aux modèles. Pionnier du concept d'« IA payante », il vise à créer un environnement d'exécution d'IA équitable, transparent et modulaire, incitant les contributeurs de données, les développeurs de modèles et les créateurs d'applications d'IA à collaborer sur une plateforme unique et à percevoir des récompenses sur la blockchain en fonction de leurs contributions réelles.
@OpenLedger offre un système complet de bout en bout, allant de la « contribution de données » au « déploiement de modèles » jusqu’au « partage des revenus basé sur l’utilisation ». Ses modules principaux comprennent :
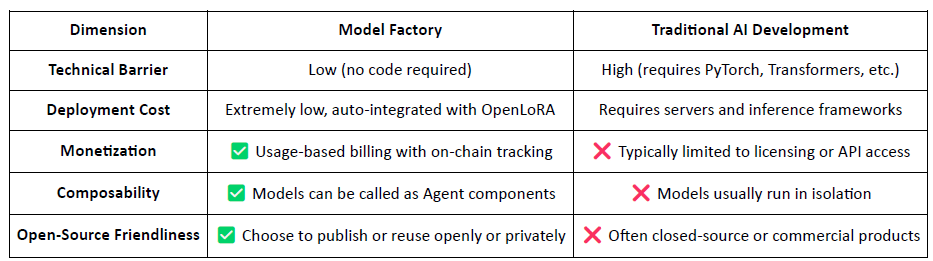
Model Factory : Mise au point et déploiement sans code de modèles personnalisés à l’aide de LLM open-source avec LoRA ;
OpenLoRA : Prend en charge la coexistence de milliers de modèles, chargés dynamiquement à la demande pour réduire les coûts de déploiement ;
PoA (Preuve d'attribution) : suit l'utilisation sur la chaîne pour répartir équitablement les récompenses en fonction de la contribution ;
Réseaux de données : réseaux de données structurés et pilotés par la communauté, adaptés aux domaines verticaux ;
Plateforme de proposition de modèles: Une place de marché en mode on-chain composable, appelable et payable.
Ensemble, ces modules forment une infrastructure de modèle composable et axée sur les données, jetant les bases d'une économie d'agents sur la chaîne.
Côté blockchain, @OpenLedger construit sur OP Stack + EigenDA, offrant un environnement performant, économique et vérifiable pour l'exécution de modèles d'IA et de contrats intelligents :
Construit sur OP Stack : exploite la pile technologique Optimism pour un débit élevé et des frais réduits ;
Règlement sur le réseau principal Ethereum : garantit la sécurité des transactions et l’intégrité des actifs ;
Compatible EVM : permet un déploiement rapide et une évolutivité pour les développeurs Solidity ;
Disponibilité des données optimisée par EigenDA : réduit les coûts de stockage tout en garantissant un accès vérifiable aux données.
Comparée aux blockchains d'IA généralistes comme NEAR (axées sur l'infrastructure de base, la souveraineté des données et le framework « Agents IA sur BOS »), OpenLedger est plus spécialisée. Elle vise à construire une blockchain dédiée à l'IA, centrée sur les données et l'incitation au niveau des modèles. Son objectif est de rendre le développement et l'invocation des modèles vérifiables, composables et monétisables durablement sur la blockchain. En tant que couche d'incitation centrée sur les modèles dans l'écosystème Web3, OpenLedger combine l'hébergement de modèles de type Hugging Face, la facturation à l'usage de type Stripe et la composabilité sur la blockchain de type Infura pour promouvoir la vision du « modèle comme actif ».
3. Composants principaux et architecture technique d'OpenLedger
3.1 Fabrique de modèles sans code
ModelFactory est la plateforme intégrée d'ajustement fin des grands modèles de langage (LLM). Contrairement aux frameworks d'ajustement fin traditionnels, elle offre une interface entièrement graphique et sans code, éliminant ainsi le besoin d'outils en ligne de commande ou d'intégrations API. Les utilisateurs peuvent ajuster leurs modèles à l'aide d'ensembles de données autorisés et validés via ModelFactory, permettant un flux de travail complet couvrant l'autorisation des données, l'entraînement du modèle et son déploiement.
Les principales étapes du flux de travail comprennent :
Contrôle d'accès aux données : les utilisateurs demandent l'accès aux ensembles de données ; une fois approuvés par les fournisseurs de données, les ensembles de données sont automatiquement connectés à l'interface de formation.
Sélection et configuration du modèle : Choisissez parmi les principaux LLM (par exemple, LLaMA, Mistral) et configurez les hyperparamètres via l’interface graphique.
Réglage fin et léger : la prise en charge intégrée de LoRA/QLoRA permet un entraînement efficace avec un suivi des progrès en temps réel.
Évaluation et déploiement : des outils intégrés permettent aux utilisateurs d’évaluer les performances et d’exporter des modèles en vue de leur déploiement ou de leur réutilisation au sein de l’écosystème.
Interface de test interactive : une interface utilisateur basée sur le chat permet aux utilisateurs de tester directement le modèle optimisé dans des scénarios de questions-réponses.
Attribution RAG : Les résultats de la génération augmentée par la récupération incluent des citations de sources pour renforcer la confiance et la vérifiabilité.
L’architecture de ModelFactory comprend six modules clés, couvrant la vérification d’identité, la gestion des autorisations d’accès aux données, l’ajustement fin du modèle, l’évaluation, le déploiement et la traçabilité basée sur RAG, offrant une plateforme de services de modèles sécurisée, interactive et monétisable.
Voici un bref aperçu des grands modèles de langage actuellement pris en charge par ModelFactory :
Série LLaMA : L’un des modèles de base open source les plus largement adoptés, reconnu pour ses excellentes performances générales et sa communauté dynamique.
Mistral : une architecture efficace offrant d’excellentes performances d’inférence, idéale pour un déploiement flexible dans des environnements aux ressources limitées.
Qwen : Développée par Alibaba, cette plateforme excelle dans les tâches en langue chinoise et offre de solides capacités globales ; un choix optimal pour les développeurs en Chine.
ChatGLM : reconnu pour ses performances conversationnelles exceptionnelles en chinois, parfaitement adapté au service client vertical et aux applications localisées.
Deepseek : excelle dans la génération de code et le raisonnement mathématique, ce qui le rend idéal pour les assistants de développement intelligents.
Gemma : Un modèle léger proposé par Google, doté d’une structure épurée et d’une grande facilité d’utilisation, idéal pour le prototypage rapide et l’expérimentation.
Falcon : Autrefois une référence en matière de performance, il est désormais plus adapté à la recherche fondamentale ou aux tests comparatifs, bien que l'activité de la communauté ait diminué.
BLOOM : Offre une prise en charge multilingue solide, mais des performances d’inférence relativement plus faibles, ce qui le rend plus adapté aux études de couverture linguistique.
GPT-2: Un modèle classique ancien, désormais principalement utile à des fins d'enseignement et de test ; son déploiement en production n'est pas recommandé.
Bien que la gamme de modèles d'OpenLedger n'inclue pas encore les modèles MoE haute performance les plus récents ni les architectures multimodales, ce choix n'est pas obsolète. Il reflète plutôt une stratégie axée sur la praticité, tenant compte des contraintes du déploiement sur la blockchain, notamment les coûts d'inférence, la compatibilité RAG, l'intégration LoRa et les limitations de l'environnement EVM.
Model Factory : une chaîne d’outils sans code avec attribution de contribution intégrée
En tant que chaîne d'outils sans code, Model Factory intègre un mécanisme de preuve d'attribution pour tous les modèles, garantissant ainsi les droits des contributeurs de données et des développeurs de modèles. Son accessibilité, ses possibilités de monétisation natives et sa composabilité la distinguent des flux de travail d'IA traditionnels.
Pour les développeurs : Fournit un pipeline complet allant de la création et de la distribution du modèle à la génération de revenus.
Pour la plateforme : Permet un écosystème liquide et composable pour les actifs modèles.
Pour les utilisateurs : les modèles et les agents peuvent être appelés et composés comme des API.
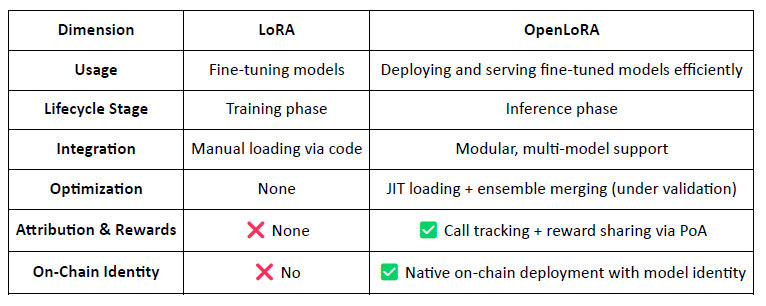
3.2 OpenLoRA, intégration sur la blockchain des modèles finement paramétrés
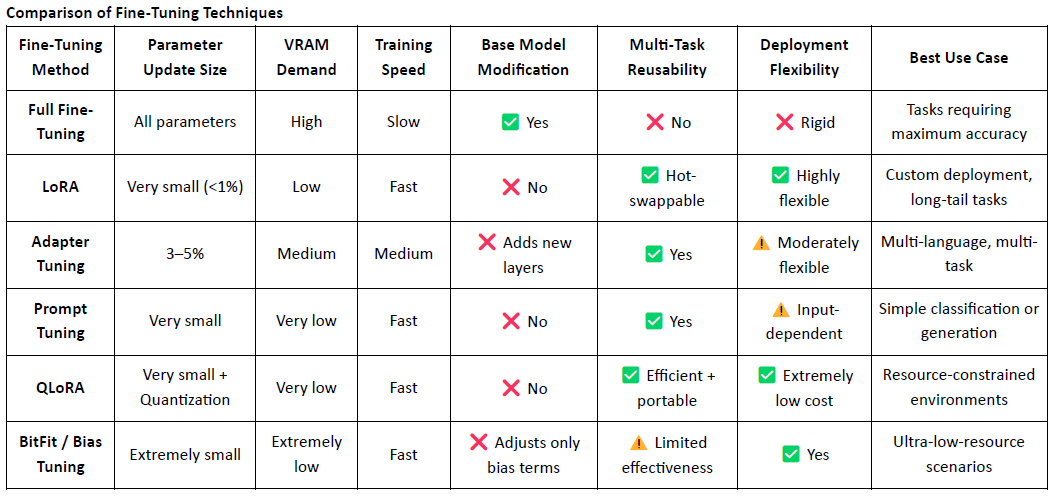
LoRA (Low-Rank Adaptation) est une technique d'ajustement fin efficace et peu gourmande en paramètres. Elle consiste à insérer des matrices de faible rang entraînables dans un modèle pré-entraîné de grande taille sans modifier les poids du modèle original, ce qui réduit considérablement les coûts d'entraînement et les besoins de stockage.
Les modèles de langage traditionnels de grande taille (LLM), tels que LLaMA ou GPT-3, contiennent souvent des milliards, voire des centaines de milliards, de paramètres. Pour adapter ces modèles à des tâches spécifiques (par exemple, questions-réponses juridiques, consultations médicales), un réglage fin est nécessaire. L'idée principale de LoRA est de figer les paramètres du modèle original et de n'entraîner que les matrices nouvellement ajoutées, ce qui le rend très efficace et facile à déployer.
Grâce à sa légèreté et à son architecture flexible, LoRA est devenu l'approche de réglage fin dominante pour le déploiement et la composabilité des modèles natifs Web3.
OpenLoRA est un framework d'inférence léger développé par @OpenLedger spécifiquement conçu pour le déploiement multi-modèles et le partage des ressources GPU. Son objectif principal est de résoudre les problèmes liés aux coûts de déploiement élevés, à la faible réutilisabilité des modèles et à l'utilisation inefficace des GPU, rendant ainsi la vision d'une « IA payante » concrètement réalisable.
Architecture modulaire pour un service de modèles évolutif
OpenLoRA est composé de plusieurs composants modulaires qui, ensemble, permettent un service de modèles évolutif et rentable :
Stockage des adaptateurs LoRA : les adaptateurs LoRA optimisés sont hébergés sur @OpenLedger et chargés à la demande. Cela évite de précharger tous les modèles dans la mémoire du GPU et permet d’économiser des ressources.
Couche d'hébergement de modèles et de fusion d'adaptateurs : tous les adaptateurs partagent un modèle de base commun. Lors de l'inférence, les adaptateurs sont fusionnés dynamiquement, prenant en charge l'inférence multi-adaptateurs de type ensemble pour des performances améliorées.
Moteur d'inférence : implémente des optimisations au niveau CUDA, notamment Flash-Attention, Paged Attention et SGMV, pour améliorer l'efficacité.
Routeur de requêtes et flux de jetons : achemine dynamiquement les requêtes d’inférence vers l’adaptateur approprié et diffuse les jetons à l’aide de noyaux optimisés.
Flux de travail d'inférence de bout en bout
Le processus d'inférence suit un pipeline éprouvé et pratique :
Initialisation du modèle de base : les modèles de base comme LLaMA 3 ou Mistral sont chargés dans la mémoire du GPU.
Chargement dynamique des adaptateurs : sur demande, les adaptateurs LoRA spécifiés sont récupérés depuis Hugging Face, Predibase ou le stockage local.
Fusion et activation : les adaptateurs sont fusionnés en temps réel dans le modèle de base, prenant en charge l’exécution d’ensemble.
Exécution des inférences et flux de jetons : le modèle fusionné génère une sortie avec un flux au niveau des jetons, pris en charge par la quantification pour une vitesse et une efficacité mémoire optimales.
Libération des ressources : les adaptateurs sont déchargés après l’exécution, libérant ainsi de la mémoire et permettant une rotation efficace de milliers de modèles finement réglés sur un seul GPU.
Optimisations clés
OpenLoRA atteint des performances supérieures grâce à :
Chargement de l'adaptateur JIT (Just-In-Time) pour minimiser l'utilisation de la mémoire.
Parallélisme tensoriel et attention paginée pour la gestion de séquences plus longues et l'exécution concurrente.
Fusion multi-adaptateurs pour la fusion de modèles composables.
Flash Attention, noyaux CUDA précompilés et quantification FP8/INT8 pour une inférence plus rapide et à plus faible latence.
Ces optimisations permettent une inférence multi-modèles à haut débit et à faible coût, même dans des environnements à GPU unique, particulièrement adaptée aux modèles à longue traîne, aux agents de niche et à l'IA hautement personnalisée.
OpenLoRA : Transformer les modèles LoRA en ressources Web3
Contrairement aux frameworks LoRA traditionnels axés sur le réglage fin, OpenLoRA transforme le service de modèles en une couche native Web3 monétisable, rendant chaque modèle :
Identifiable sur la chaîne (via l'identifiant du modèle)
Incitation économique par l'utilisation
Composable en agents d'IA
Récompense distribuable via le mécanisme PoA
Cela permet de considérer chaque modèle comme un actif :
Perspectives de performance
De plus, @OpenLedger a publié des benchmarks de performances futures pour OpenLoRA. Comparé aux déploiements de modèles à paramètres complets traditionnels, l'utilisation de la mémoire GPU est considérablement réduite à 8-12 Go, le temps de commutation de modèle est théoriquement inférieur à 100 ms, le débit peut atteindre plus de 2 000 jetons par seconde et la latence est maintenue entre 20 et 50 ms.
Bien que ces chiffres soient techniquement atteignables, ils doivent être considérés comme des estimations maximales et non comme des performances quotidiennes garanties. En production, les résultats réels peuvent varier en fonction de la configuration matérielle, des stratégies d'ordonnancement et de la complexité des tâches.
3.3 Réseaux de données : de la propriété des données à l’intelligence des données
Les données de haute qualité et spécifiques à un domaine sont devenues essentielles à la création de modèles performants. Les Datanets constituent l'infrastructure fondamentale de @OpenLedger pour la gestion des données en tant qu'actif, permettant la collecte, la validation et la distribution d'ensembles de données structurés au sein de réseaux décentralisés. Chaque Datanet fonctionne comme un entrepôt de données dédié à un domaine, où les contributeurs téléchargent des données vérifiées et authentifiées sur la blockchain. Grâce à des autorisations transparentes et à un système d'incitations, les Datanets permettent une curation de données fiable et collaborative pour l'entraînement et l'optimisation des modèles.
Contrairement à des projets comme Vana, qui se concentrent principalement sur la propriété des données, OpenLedger va au-delà de la simple collecte de données en les transformant en intelligence. Grâce à ses trois composants intégrés – Datanets (ensembles de données collaboratifs et attribués), Model Factory (outils de réglage fin sans code) et OpenLoRA (adaptateurs de modèles traçables et composables) – OpenLedger étend la valeur des données tout au long du cycle d'entraînement des modèles et de leur utilisation sur la blockchain. Là où Vana met l'accent sur « qui possède les données », OpenLedger se concentre sur « comment les données sont entraînées, utilisées et valorisées », positionnant ainsi les deux comme des piliers complémentaires de l'architecture d'IA du Web3 : l'un pour garantir la propriété des données, l'autre pour permettre leur monétisation.
3.4 Preuve d'attribution : redéfinir le mécanisme d'incitation à la distribution de la valeur
La preuve d’attribution (PoA) est le mécanisme central d’OpenLedger permettant de lier les contributions aux récompenses. Elle enregistre cryptographiquement chaque contribution de données et chaque invocation de modèle sur la blockchain, garantissant ainsi aux contributeurs une juste rémunération lorsque leurs contributions génèrent de la valeur. Le processus se déroule comme suit :
Soumission des données : les utilisateurs téléchargent des ensembles de données structurés et spécifiques à un domaine et les enregistrent sur la blockchain à des fins d’attribution.
Évaluation d'impact : Le système évalue la pertinence de chaque ensemble de données pour la formation, au niveau de chaque inférence, en tenant compte de la qualité du contenu et de la réputation du contributeur.
Vérification de l'entraînement : les journaux permettent de suivre les ensembles de données réellement utilisés pour l'entraînement du modèle, ce qui permet de fournir une preuve de contribution vérifiable.
Distribution des récompenses : Les contributeurs sont récompensés en jetons en fonction de l’efficacité des données et de leur influence sur les résultats du modèle.
Gouvernance de la qualité : les données de faible qualité, indésirables ou malveillantes sont pénalisées afin de préserver l’intégrité de la formation.
Contrairement à l'architecture incitative de Bittensor, basée sur les sous-réseaux et la réputation, qui encourage globalement les fonctions de calcul, de données et de classement, @OpenLedger se concentre sur la valorisation au niveau des modèles. PoA n'est pas qu'un simple mécanisme de récompenses : c'est un cadre d'attribution multi-étapes garantissant la transparence, la traçabilité et la rémunération tout au long du cycle de vie, des données aux modèles, jusqu'aux agents. Chaque invocation de modèle devient ainsi un événement traçable et récompensable, établissant une chaîne de valeur vérifiable qui aligne les incitations sur l'ensemble du pipeline des actifs d'IA.
Attribution par génération augmentée de la récupération (RAG)
RAG (Retrieval-Augmented Generation) est une architecture d'IA qui améliore les performances des modèles de langage en intégrant des connaissances externes, résolvant ainsi le problème des informations erronées ou obsolètes. @OpenLedger introduit l'attribution RAG afin de garantir la traçabilité, la vérifiabilité et la valorisation de tout contenu extrait utilisé pour la génération du modèle.
Flux de travail d'attribution RAG :
Requête de l'utilisateur → Récupération de données : L'IA récupère les données pertinentes à partir des ensembles de données indexés de @OpenLedger (Datanets).
Génération de réponses avec suivi d'utilisation : le contenu récupéré est utilisé dans la réponse du modèle et enregistré sur la chaîne.
Récompenses pour les contributeurs : Les contributeurs de données sont récompensés en fonction du fonds et de la pertinence des données recueillies.
Citations transparentes : les résultats du modèle incluent des liens vers les sources de données originales, ce qui renforce la confiance et la traçabilité.
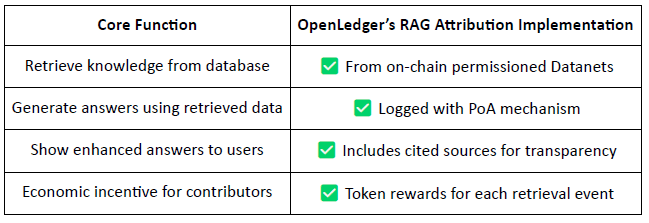
En résumé, le système d'attribution RAG de @OpenLedger garantit la traçabilité de chaque réponse d'IA jusqu'à une source de données vérifiée, et les contributeurs sont récompensés en fonction de leur fréquence d'utilisation, créant ainsi un cercle vertueux d'incitation durable. Ce système accroît non seulement la transparence des résultats, mais jette également les bases d'une infrastructure d'IA vérifiable, monétisable et fiable.
4. Avancement du projet et collaboration avec l'écosystème
Le projet @OpenLedger a officiellement lancé son réseau de test, la première phase étant axée sur la couche d'intelligence des données : un référentiel de données Internet alimenté par la communauté. Cette couche agrège, enrichit, classe et structure les données brutes afin de les transformer en informations exploitables pour l'entraînement de modèles linéaires logiques (LLM) spécifiques à un domaine sur @OpenLedger . Les membres de la communauté peuvent exécuter des nœuds périphériques sur leurs appareils personnels pour collecter et traiter les données. En contrepartie, les participants gagnent des points en fonction de leur temps de fonctionnement et de leur contribution aux tâches. Ces points seront ensuite convertibles en jetons $OPEN , le mécanisme de conversion précis étant annoncé avant l'événement de génération de jetons (TGE).

Époque 2 : Lancement des réseaux de données
La deuxième phase du réseau de test introduit Datanets, un système de contribution accessible uniquement sur liste blanche. Les participants doivent réussir une évaluation préalable pour accéder à des tâches telles que la validation, la classification ou l'annotation des données. Les récompenses sont attribuées en fonction de la précision, du niveau de difficulté et du classement.
Feuille de route : Vers une économie de l'IA décentralisée
@OpenLedger vise à boucler la boucle entre l'acquisition des données et le déploiement des agents, formant ainsi une chaîne de valeur d'IA décentralisée complète :
Phase 1 : Couche d'intelligence des données
Les nœuds communautaires collectent et traitent les données Internet en temps réel pour un stockage structuré.Phase 2 : Contributions de la communauté
La communauté contribue à la validation et aux retours d'information, constituant ainsi le « jeu de données de référence » pour l'entraînement du modèle.Phase 3 : Création de modèles et réclamation
Les utilisateurs peaufinent et s'approprient des modèles spécialisés, permettant ainsi la monétisation et la composabilité.Phase 4 : Création d'agents
Les modèles peuvent être transformés en agents intelligents sur la chaîne, déployés dans divers scénarios et cas d'utilisation.
Partenaires de l'écosystème : @OpenLedger collabore avec les principaux acteurs des domaines du calcul, de l'infrastructure, des outils et des applications d'IA :
Calcul et hébergement : Aethir, Ionet, 0G
Infrastructure de cumul : AltLayer, Etherfi, EigenLayer AVS
Outils et interopérabilité : Ambios, Kernel, Web3Auth, Intract
Agents et constructeurs de modèles d'IA : Giza, Gaib, Exabits, FractionAI, Mira, NetMind
Dynamisme de marque grâce aux sommets internationaux : Au cours de l’année écoulée, @OpenLedger a organisé des sommets DeAI lors d’événements Web3 majeurs, notamment Token2049 Singapour, Devcon Thaïlande, Consensus Hong Kong et ETH Denver. Ces rencontres ont mis en lumière des intervenants et des projets de pointe en intelligence artificielle décentralisée. Comptant parmi les rares équipes d’infrastructure à organiser régulièrement des événements sectoriels de haut niveau, @OpenLedger a considérablement renforcé sa visibilité et sa notoriété auprès de la communauté des développeurs et de l’écosystème plus large de l’IA crypto, jetant ainsi les bases d’une croissance future et d’un effet de réseau significatif.
5. Financement et profil de l'équipe
@OpenLedger La société a finalisé une levée de fonds d'amorçage de 11,2 millions de dollars en juillet 2024, avec le soutien de Polychain Capital, Borderless Capital, Finality Capital, Hashkey et d'investisseurs providentiels de renom tels que Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda) et Trevor. Les fonds seront principalement utilisés pour accélérer le développement de@OpenLedger Le réseau AI Chain de [nom de l'entreprise], y compris ses mécanismes d'incitation des modèles, son infrastructure de données et le déploiement plus large de son écosystème d'applications d'agents.
OpenLedger a été fondée par Ram Kumar, contributeur principal d'OpenLedger et entrepreneur basé à San Francisco, expert en intelligence artificielle/apprentissage automatique et en technologies blockchain. Il apporte au projet une combinaison de connaissance du marché, d'expertise technique et de leadership stratégique. Ram a précédemment codirigé une société de R&D spécialisée dans la blockchain et l'IA/ML, réalisant un chiffre d'affaires annuel de plus de 35 millions de dollars, et a joué un rôle clé dans le développement de partenariats à fort impact, notamment une coentreprise stratégique avec une filiale de Walmart. Son travail est axé sur le développement de l'écosystème et la création d'alliances favorisant l'adoption concrète de ces technologies dans différents secteurs.
6. Tokenomics et gouvernance
Le jeton utilitaire natif de l'écosystème m-1241 est le principal support de la gouvernance, du traitement des transactions, de la distribution des incitations et du fonctionnement des agents d'IA de la plateforme. Il constitue ainsi le fondement économique d'une circulation durable, sur la blockchain, des modèles d'IA et des données. Bien que le cadre tokenomics soit encore en développement et susceptible d'être amélioré, m-1243 s'apprête à lancer son événement de génération de jetons (TGE), bénéficiant d'une popularité croissante en Asie, en Europe et au Moyen-Orient.
Les principales utilités de $OPEN comprennent :
Gouvernance et prise de décision:
Les détenteurs d'OPEN peuvent voter sur des aspects critiques tels que le financement du modèle, la gestion des agents, les mises à jour du protocole et l'allocation des fonds.Paiements de jetons de gaz et de frais : OPEN sert de jeton de gaz natif pour le @OpenLedger L2, permettant des modèles de frais personnalisables natifs de l'IA et réduisant la dépendance à l'ETH.
Incitations basées sur l'attribution:
Les développeurs qui contribuent en fournissant des ensembles de données, des modèles ou des services d'agents de haute qualité sont récompensés dans OPEN en fonction de leur utilisation et de leur impact réels.Pontage inter-chaînes:
OPEN prend en charge l'interopérabilité entre@OpenLedger L2 et Ethereum L1, améliorant la portabilité et la composabilité des modèles et des agents.Le staking pour les agents IA:
L'exploitation d'un agent d'IA nécessite un staking OPEN. Les agents sous-performants ou malveillants s'exposent à des sanctions, incitant ainsi à fournir un service fiable et de haute qualité.
Contrairement à de nombreux modèles de gouvernance qui lient l'influence exclusivement à la détention de jetons, @OpenLedger introduit un système de gouvernance au mérite où le pouvoir de vote est lié à la création de valeur. Ce modèle privilégie les contributeurs qui conçoivent, perfectionnent ou utilisent activement des modèles et des ensembles de données, plutôt que les détenteurs de capital passifs. Ce faisant, @OpenLedger garantit la pérennité du projet et le protège contre la spéculation, restant ainsi fidèle à sa vision d'une économie de l'IA transparente, équitable et pilotée par la communauté.
7. Analyse du paysage concurrentiel et de la concurrence
@OpenLedger , positionné comme une infrastructure incitative pour un modèle d'« IA payante », vise à fournir des voies de valorisation vérifiables, attribuables et durables aux contributeurs de données et aux développeurs de modèles. En s'appuyant sur un déploiement on-chain, des incitations basées sur l'usage et une composition modulaire d'agents, il a bâti une architecture système unique qui se distingue dans le secteur de l'IA crypto. Bien qu'aucun projet existant ne reproduise intégralement le cadre de bout en bout de @OpenLedger , il présente une forte comparabilité et une synergie potentielle avec plusieurs protocoles représentatifs dans des domaines tels que les mécanismes d'incitation, la monétisation des modèles et l'attribution des données.
Couche d'incitation : OpenLedger contre Bittensor
Bittensor est l'un des réseaux d'IA décentralisés les plus représentatifs. Il exploite un système collaboratif multi-rôles basé sur des sous-réseaux et un système de notation de réputation, son jeton $TAO incitant à la participation des nœuds de modélisation, de données et de classement. À l'inverse, @OpenLedger se concentre sur le partage des revenus via le déploiement et l'invocation de modèles sur la blockchain, privilégiant une infrastructure légère et une coordination basée sur les agents. Bien que les deux partagent une logique d'incitation commune, ils diffèrent par la complexité de leur système et leur couche d'écosystème : Bittensor vise à constituer la couche fondamentale pour une IA généralisée, tandis que @OpenLedger sert de couche de réalisation de valeur au niveau applicatif.
Incitations liées à la propriété et à l'invocation des modèles : OpenLedger vs. Sentient
Sentient introduit le concept d’« IA OML (Ouverte, Monétisable, Loyale) », mettant l’accent sur des modèles gérés par la communauté, dotés d’une identité unique et dont les revenus sont suivis grâce à l’empreinte numérique des modèles. Si les deux projets prônent la reconnaissance des contributeurs, Sentient se concentre davantage sur les phases d’entraînement et de création des modèles, tandis que @OpenLedger privilégie le déploiement, l’utilisation et le partage des revenus. Cette complémentarité les rend complémentaires à différents niveaux de la chaîne de valeur de l’IA : Sentient en amont, @OpenLedger en aval.
Hébergement de modèles et exécution vérifiable : OpenLedger vs. OpenGradient
OpenGradient se concentre sur la construction d'une infrastructure d'inférence sécurisée utilisant TEE et zkML, offrant un hébergement de modèles décentralisé et une exécution fiable. Il met l'accent sur une infrastructure fondamentale pour des opérations d'IA sécurisées. @OpenLedger , quant à lui, est conçu autour du cycle de monétisation post-déploiement, combinant Model Factory, OpenLoRA, PoA et Datanets dans une boucle complète « entraînement-déploiement-invocation-récompense ». Les deux opèrent à différentes couches du cycle de vie du modèle — OpenGradient sur l'intégrité de l'exécution, @OpenLedger sur l'incitation économique et la composabilité — avec un potentiel de synergie évident.
Modèles et évaluation participatifs : OpenLedger vs. CrunchDAO
CrunchDAO se concentre sur les compétitions de prédiction décentralisées dans le domaine de la finance, récompensant les communautés en fonction des performances des modèles soumis. Bien qu'elle soit parfaitement adaptée aux applications verticales, elle manque de fonctionnalités pour la composabilité des modèles et le déploiement sur la blockchain. @OpenLedger offre un cadre de déploiement unifié et une fabrique de modèles composables, avec une applicabilité plus large et des mécanismes de monétisation natifs, ce qui rend les deux plateformes complémentaires en termes de structures d'incitation.
Modèles légers pilotés par la communauté : OpenLedger vs. Assisterr
Assisterr, basé sur Solana, encourage la création de petits modèles de langage (SLM) grâce à des outils sans code et un système de récompenses basé sur $sASRR. À l'inverse, @OpenLedger met davantage l'accent sur l'attribution traçable et les boucles de revenus à travers les couches de données, de modèle et d'invocation, en utilisant son mécanisme PoA pour une distribution fine des incitations. Assisterr est mieux adapté à une collaboration communautaire simple, tandis que @OpenLedger vise une infrastructure de modèles réutilisable et composable.
Model Factory : OpenLedger contre Pond
Bien que @OpenLedger et Pond proposent tous deux des modules « Model Factory », leurs utilisateurs cibles et leurs philosophies de conception diffèrent sensiblement. Pond se concentre sur la modélisation basée sur les réseaux neuronaux graphiques (GNN) pour analyser le comportement sur la blockchain, s'adressant aux data scientists et aux chercheurs en algorithmes grâce à un modèle de développement axé sur la compétition. À l'inverse, OpenLedger fournit des outils de réglage fin et légers basés sur des modèles de langage (par exemple, LLaMA, Mistral), conçus pour les développeurs et les utilisateurs non techniques avec une interface sans code. Il met l'accent sur les flux d'incitation automatisés sur la blockchain et l'intégration collaborative des modèles de données, visant à construire un réseau de valeur d'IA piloté par les données.
Chemin d'inférence vérifiable : OpenLedger vs. Bagel
Bagel introduit ZKLoRA, un cadre d'inférence cryptographique vérifiable utilisant des modèles LoRA optimisés et des preuves à divulgation nulle de connaissance (ZKP) pour garantir l'exactitude des exécutions hors chaîne. Parallèlement, @OpenLedger exploite l'optimisation LoRA avec OpenLoRA pour permettre un déploiement évolutif et l'invocation dynamique de modèles. @OpenLedger aborde également l'inférence vérifiable sous un angle différent : en associant une preuve d'attribution à chaque sortie de modèle, il explique quelles données ont contribué à l'inférence et comment. Cela renforce la transparence, récompense les principaux contributeurs de données et instaure la confiance dans le processus de décision. Tandis que Bagel se concentre sur l'intégrité des calculs, OpenLedger apporte responsabilité et explicabilité grâce à l'attribution.
Voie de collaboration des données : OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien et FractionAI se concentrent sur l'étiquetage décentralisé des données, tandis que Vana et Irys se spécialisent dans la propriété et la souveraineté des données. @OpenLedger , via ses modules Datanets + PoA, assure le suivi de l'utilisation des données de haute qualité et distribue les récompenses en conséquence sur la blockchain. Ces plateformes couvrent différents niveaux de la chaîne de valeur des données — étiquetage et gestion des droits en amont, monétisation et attribution en aval — ce qui les rend naturellement collaboratives plutôt que concurrentielles.

En résumé, OpenLedger occupe une position intermédiaire dans l'écosystème actuel de l'IA cryptographique, en tant que protocole de pont pour l'intégration des modèles sur la blockchain et leur invocation incitative. Il connecte les réseaux d'entraînement et les plateformes de données en amont aux couches d'agents et aux applications utilisateur en aval, devenant ainsi une infrastructure essentielle qui relie la création de valeur à l'utilisation concrète des modèles.
8. Conclusion | Des données aux modèles : que l’IA gagne aussi de l’argent
Le projet @OpenLedger vise à créer une infrastructure de « modèles en tant qu’actifs » pour le Web3. En instaurant un cycle complet de déploiement sur la blockchain, d’incitations à l’utilisation, d’attribution de propriété et de composabilité des agents, il intègre pour la première fois les modèles d’IA dans un système économique véritablement traçable, monétisable et collaboratif.
Sa pile technologique, comprenant Model Factory, OpenLoRA, PoA et Datanets, offre :
outils de formation à faible barrière pour les développeurs,
Attribution équitable des revenus aux contributeurs de données,
Mécanismes d'invocation de modèles composables et de partage des récompenses pour les applications.
Cela active de manière exhaustive les aspects longtemps négligés de la chaîne de valeur de l'IA : les données et les modèles.
Plutôt que d'être une simple version Web3 de Hugging Face, OpenLedger s'apparente davantage à un hybride de Hugging Face, Stripe et Infura, offrant l'hébergement de modèles, la facturation à l'usage et un accès API programmable sur la blockchain. Face à l'accélération des tendances en matière d'assetisation des données, d'autonomie des modèles et de modularisation des agents, OpenLedger est idéalement positionné pour devenir une blockchain d'IA centrale dans le cadre du paradigme de l'« IA payante ».