Au cours des dernières années, l'IA a fait des progrès incroyables. Les modèles peuvent rédiger des essais, générer du code et même créer des images ou des vidéos. Mais plus j'explore comment ces systèmes fonctionnent, plus je réalise que l'intelligence sans fiabilité est une fondation. L'IA est comme un bâtiment qui a besoin d'une base pour tenir.
En étudiant les idées présentées dans le livre blanc de Mira, un thème ne cessait de me revenir à l'esprit : l'IA ne échoue pas parce qu'elle manque de connaissances, elle échoue parce qu'elle manque de vérification. Je pensais sans cesse à cette idée et à la façon dont elle se rapporte à l'IA.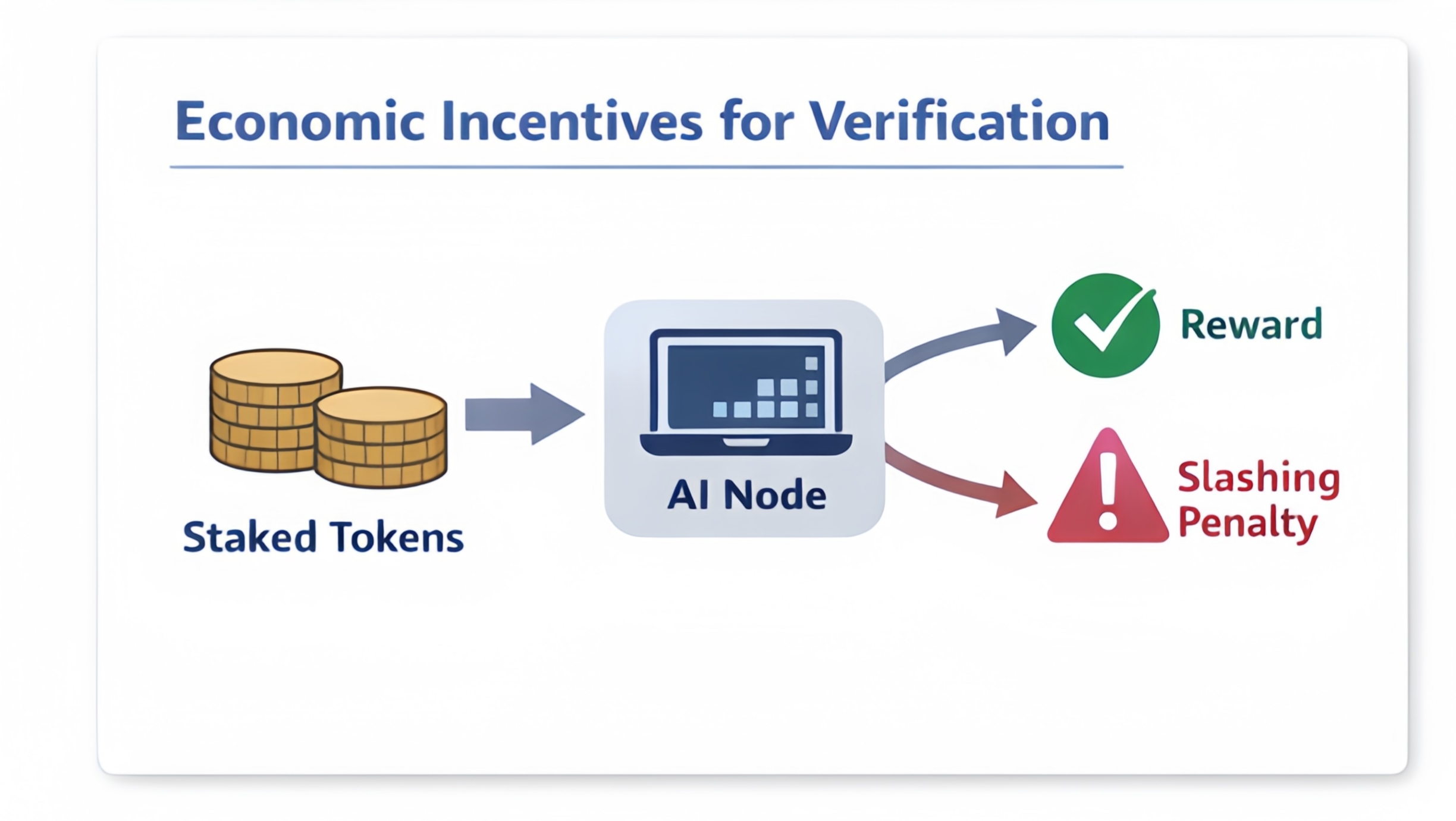
Les grands modèles génèrent des réponses basées sur des probabilités apprises à partir d'ensembles de données. Cela signifie qu'ils peuvent produire des réponses qui semblent convaincantes même lorsqu'elles sont fausses. Cela peut apparaître comme une hallucination, où le modèle invente des informations ou un biais où la sortie reflète des schémas dans les données d'entraînement plutôt que la vérité objective. Peu importe la taille du modèle, ces problèmes ne disparaissent jamais complètement.
Pour moi, cela met en évidence un problème : nous avons passé des années à améliorer la génération d'IA, mais nous n'avons pas investi suffisamment dans la vérification de l'IA. Nous devons nous concentrer sur le fait de rendre l'IA plus fiable.
Le Problème de Compter sur un Modèle Unique
* Un des aperçus que j'ai trouvé intéressant est qu'un seul système d'IA a une limite d'erreur.
* Même le modèle avancé ne peut pas complètement éliminer à la fois l'hallucination et le biais en même temps.
Si les développeurs essaient de réduire les hallucinations en restreignant les données d'entraînement, ils introduisent souvent un biais. S'ils élargissent les données pour réduire le biais, des incohérences commencent à apparaître dans les réponses des modèles. Cela devient un exercice d'équilibre sans solution.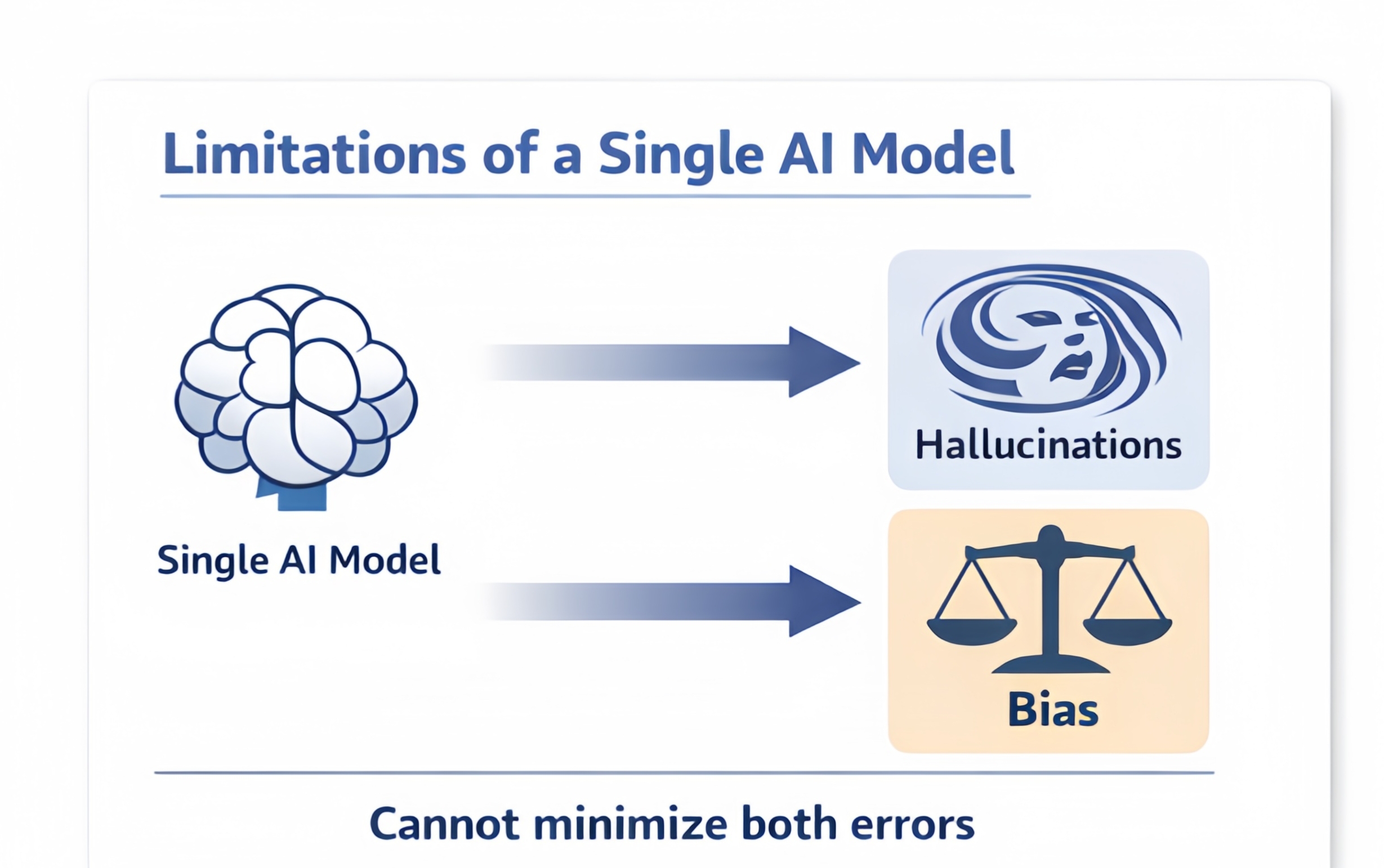
C'est pourquoi je pense que la validation collective est si importante. Au lieu de faire confiance à un seul modèle pour décider si quelque chose est correct, Mira introduit un système où plusieurs modèles d'IA indépendants évaluent la même affirmation. Le résultat final provient du consensus plutôt que de l'autorité.
Ce changement semble similaire à la façon dont les systèmes distribués ont amélioré la confiance dans les infrastructures financières et de données. C'est comme un groupe de personnes vérifiant des informations ensemble.
Diviser l'Information en Morceaux
Un autre concept qui a attiré mon attention est la façon dont le système transforme le contenu avant que la vérification n'ait lieu.
* Plutôt que de demander aux modèles de juger un article ou un paragraphe entier, le réseau divise l'information en petites affirmations claires.
* Chaque affirmation devient une question que les modèles de vérification peuvent évaluer indépendamment.
Cela résout un problème technique. Différents modèles interprètent le texte de manière différente. En convertissant le contenu en affirmations, le réseau s'assure que chaque vérificateur analyse la même déclaration exacte.
Pour moi, ce design montre que la fiabilité dans l'IA ne concerne pas seulement de meilleurs modèles ; il s'agit aussi d'un meilleur cadrage des problèmes.
Incitations Qui Encouragent le Comportement
Ce qui rend également ce système intéressant, c'est la couche économique qui le sous-tend. Les nœuds qui vérifient les affirmations doivent miser de la valeur avant de participer. Si leurs réponses s'écartent constamment du consensus ou montrent des signes de manipulation, ils risquent de perdre leur mise. Cela crée une incitation pour les opérateurs à effectuer une véritable vérification au lieu de deviner.
Les systèmes traditionnels de preuve de travail récompensent l'effort, même si cet effort n'a pas de signification pratique. En revanche, ce réseau nécessite un calcul : l'inférence de l'IA utilisée pour valider l'information.
Le Rôle de la Diversité des Modèles
Une autre chose que j'apprécie est l'accent mis sur la diversité. Différents modèles d'IA sont formés sur des ensembles de données, des architectures et des stratégies d'optimisation. Ces différences peuvent introduire un biais individuellement. Lorsqu'elles sont combinées, elles peuvent également s'équilibrer.
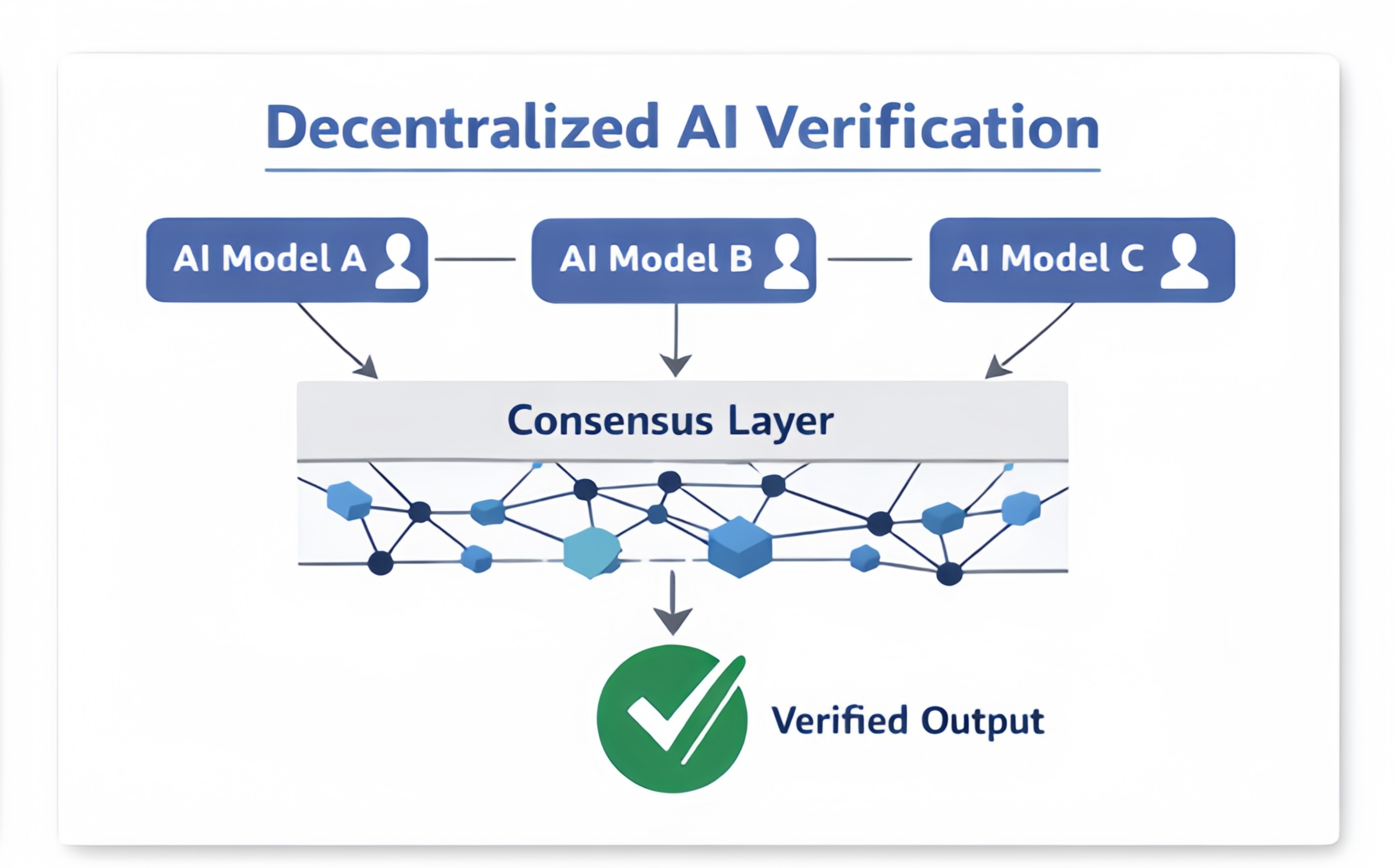
Un réseau décentralisé permet naturellement à cette diversité d'émerger. Des opérateurs indépendants exécutent des modèles de vérification, ce qui réduit le risque qu'une seule perspective domine le processus de vérification.
Un Pas Vers une IA Autonome Fiable
Ce qui m'enthousiasme le plus, à propos de cette approche, ce sont ses implications à long terme. Aujourd'hui, les systèmes d'IA nécessitent encore une supervision humaine car leurs sorties ne peuvent pas toujours être dignes de confiance. Si une couche de vérification solide devient partie intégrante de l'infrastructure de l'IA, cette dynamique pourrait changer.
Des humains vérifiant constamment les sorties de l'IA, les machines pourraient se vérifier mutuellement par un consensus décentralisé.
Ma Réflexion Finale
Après avoir réfléchi à ces idées, ma plus grande conclusion est simple : l'avenir de l'IA pourrait dépendre autant des réseaux de vérification que de meilleurs modèles. La génération a rendu l'IA puissante. La vérification pourrait être ce qui rend l'IA digne de confiance.
Si cette vision réussit, nous pourrions éventuellement voir des systèmes d'IA qui non seulement produisent des informations rapidement, mais fournissent également une preuve cryptographique que l'information a été vérifiée. Dans un monde de plus en plus dirigé par la connaissance générée par machine, ce type d'infrastructure de confiance pourrait devenir incroyablement précieux.
#Mira @Mira - Trust Layer of AI $MIRA
