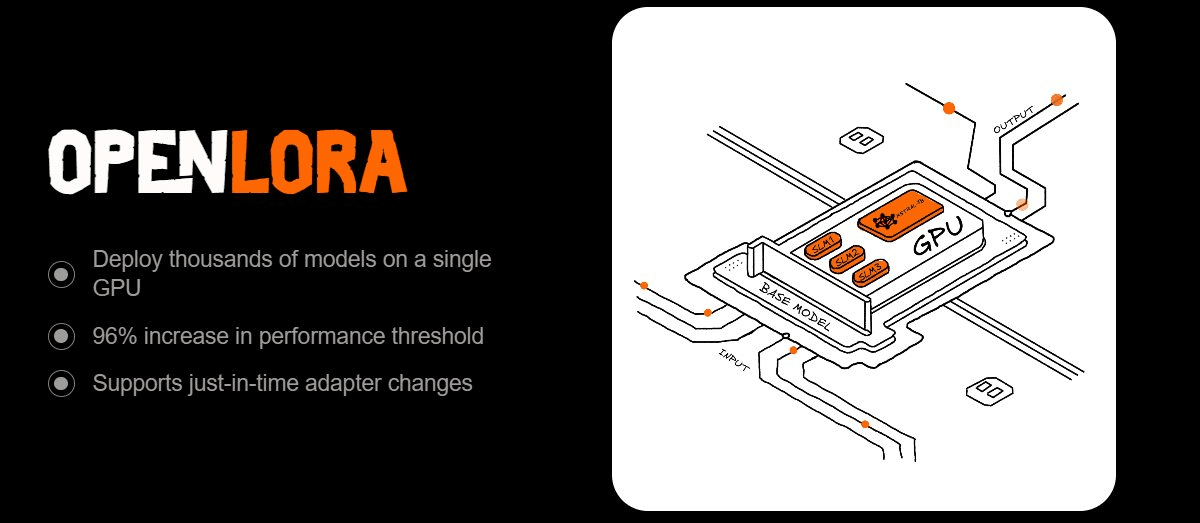
La plupart des gens ne réalisent pas à quel point cela devient chaotique lorsque vous essayez de servir un tas de modèles finement ajustés. Chaque adaptateur consomme de la mémoire GPU, le changement semble être un fardeau, et les coûts s'accumulent rapidement.
C'est pourquoi OpenLoRA a attiré mon attention. Il est conçu pour servir des milliers de modèles LoRA sur un seul GPU sans effort. Le truc ? Chargement dynamique des adaptateurs. Au lieu de tout précharger, il ne tire que ce dont vous avez besoin, le fusionne avec un modèle de base à la volée, et le renvoie après l'inférence. La mémoire reste légère, le débit reste élevé, la latence reste basse.

Ce qui le rend puissant pour moi :
Hugging Face, Predibase, ou même des adaptateurs personnalisés ? Il les récupère JIT.
Besoin d'inférence d'ensemble ? Plusieurs adaptateurs peuvent être fusionnés par demande.
Gestion de long contexte ? Attention paginée + attention flash s’en occupe.
Vous voulez réduire les coûts ? La quantification et les optimisations au niveau CUDA réduisent considérablement la consommation GPU.
Ce n’est pas juste un bonbon infra. C’est la différence entre le lancement d’une instance séparée pour chaque modèle et l’exécution de milliers efficacement au même endroit. Pour les développeurs, cela signifie que vous pouvez déployer des chatbots avec différentes personnalités, des assistants de code ajustés pour des tâches spécifiques, ou des modèles spécifiques à un domaine - sans maux de tête liés à l'échelle.
Et le meilleur, du moins pour moi, c’est la façon dont cela s'intègre au moteur d'attribution d'OpenLedger. Chaque fois qu'un adaptateur fonctionne, le système enregistre qui l'a entraîné, quelles données il a utilisées, et comment il a contribué. Les récompenses affluent en temps réel. C’est la propriété intégrée directement dans le pipeline.
Ma thèse : OpenLoRA ne consiste pas seulement à rendre LoRA plus léger, mais à rendre l'infrastructure IA évolutive, rentable et juste. Si l'IA doit être personnalisée et répandue, c'est le type d'infrastructure dont elle a besoin.
#OpenLoRA #OpenLedger $OPEN @OpenLedger