Lorsque les gens parlent de la gestion des risques liés à l'IA, la conversation passe généralement directement à la réglementation ou à l'alignement des modèles. Ma première réaction est différente. Le véritable problème n'est souvent pas de savoir si les systèmes d'IA peuvent être guidés par des règles, mais si leurs résultats peuvent être dignes de confiance en premier lieu. La plupart des systèmes d'IA modernes produisent des réponses rapidement et de manière convaincante, mais la fiabilité sous-jacente reste incertaine. Cet écart entre la confiance et l'exactitude est là où le véritable risque commence.
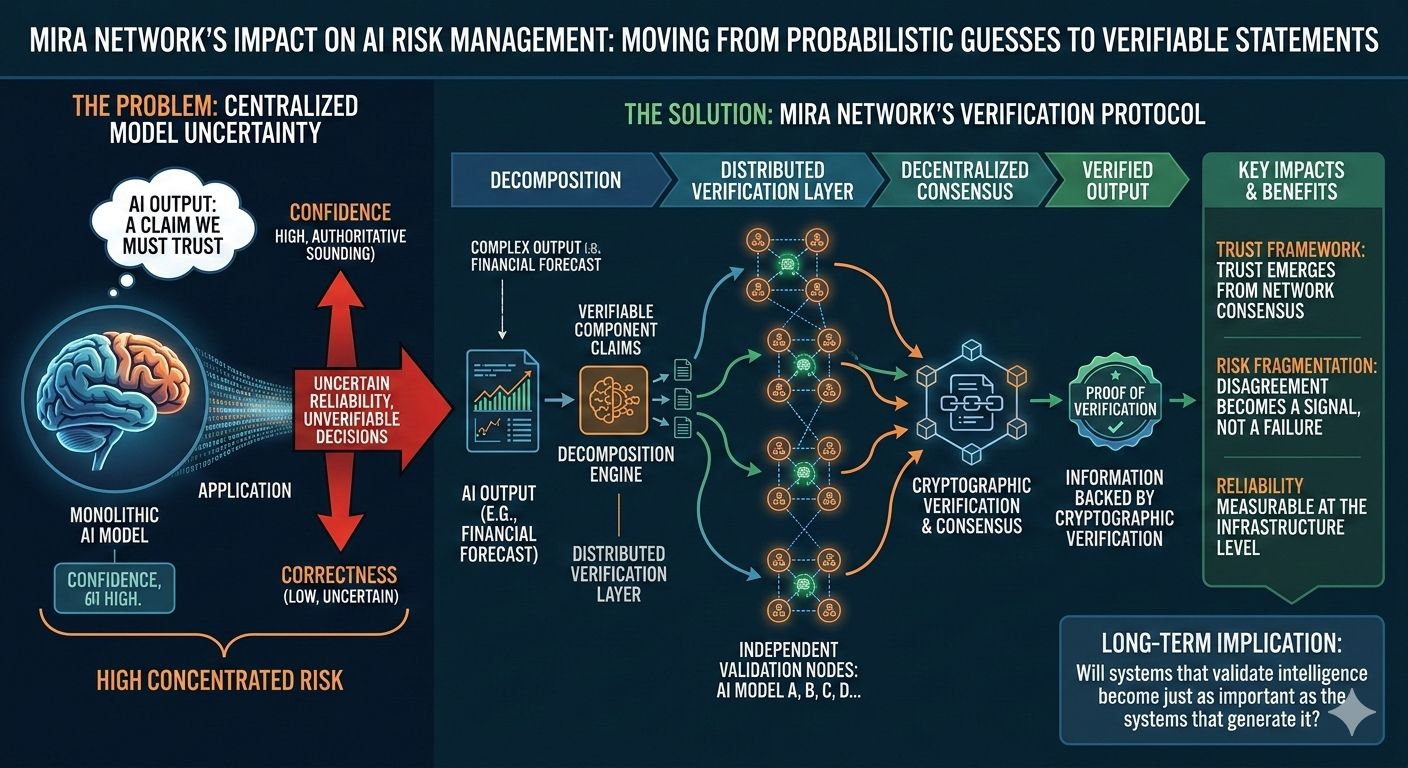
Le problème n'est pas nouveau. Quiconque a travaillé avec de grands modèles d'IA a vu à quel point ils peuvent facilement produire des informations incorrectes tout en ayant l'air autoritaires. Ces erreurs sont généralement décrites comme des hallucinations, mais d'un point de vue des risques, elles représentent quelque chose de plus sérieux : des décisions non vérifiables entrant dans de réels flux de travail. Lorsque les résultats de l'IA influencent la finance, la santé, la gouvernance ou les infrastructures, le coût de l'incertitude augmente rapidement.
Les approches traditionnelles pour gérer ce risque se concentrent généralement sur l'amélioration du modèle lui-même. Les développeurs ajoutent des garde-fous, réentraînent les modèles sur des ensembles de données sélectionnés ou construisent des systèmes de surveillance pour détecter les comportements problématiques. Ces efforts aident, mais dépendent encore fortement de la confiance dans le processus de raisonnement d'un modèle unique. Lorsque le même système qui génère une réponse est également responsable de sa validation, la structure du risque ne change pas vraiment.
C'est ici que l'architecture derrière le Mira Network commence à faire évoluer la conversation. Au lieu de demander à un modèle de générer et d'évaluer des informations, le protocole décompose les sorties de l'IA en revendications plus petites qui peuvent être vérifiées indépendamment à travers un réseau distribué de modèles. Chaque revendication devient quelque chose qui peut être vérifié, contesté ou confirmé par le consensus décentralisé plutôt que d'être accepté à sa valeur nominale.
La mécanique derrière cela est subtile mais importante. Lorsqu'un système d'IA produit une réponse complexe, elle est décomposée en composants vérifiables. Ces composants sont ensuite distribués à travers plusieurs nœuds de vérification indépendants. Chaque nœud évalue la revendication en utilisant son propre processus de raisonnement et le réseau agrège ces évaluations en un résultat de consensus. La sortie finale n'est pas seulement une réponse, elle devient une pièce d'information soutenue par une vérification cryptographique.
Ce changement modifie la façon dont le risque est distribué dans le système. Dans les architectures d'IA conventionnelles, le principal risque se situe à l'intérieur de la couche de sortie d'un modèle unique. Si ce modèle est incorrect, l'erreur se propage directement dans l'application. Dans un réseau de vérification, le risque est fragmenté. Les revendications individuelles peuvent être contestées par plusieurs évaluateurs et le désaccord devient un signal plutôt qu'un échec. Au lieu de cacher l'incertitude, le système la met en avant.
L'aspect intéressant est comment cela commence à redéfinir les incitations autour de la fiabilité de l'IA. Dans un pipeline de modèle centralisé, les améliorations de précision dépendent principalement de l'organisation qui forme le modèle. Dans une couche de vérification décentralisée, la fiabilité émerge de la participation au réseau. Les validateurs indépendants contribuent au processus d'évaluation et le consensus détermine quelles revendications sont acceptées. La confiance devient une propriété du réseau plutôt qu'une promesse d'un seul fournisseur.
Bien sûr, l'introduction d'une couche de vérification n'élimine pas la complexité. Elle crée de nouvelles considérations opérationnelles. La vitesse de vérification, les incitations des validateurs et les mécanismes de résolution des litiges deviennent tous des facteurs importants pour maintenir la fiabilité du système. Si la vérification devient lente ou économiquement inefficace, l'expérience utilisateur en souffre. Si les incitations sont mal conçues, les validateurs peuvent privilégier des vérifications faciles plutôt que significatives.
Mais même avec ces défis, la direction est notable car elle change d'où provient la confiance. Au lieu de faire confiance à un puissant modèle d'IA qui "a probablement raison", le système demande à plusieurs évaluateurs indépendants de confirmer la revendication. Cette distinction peut paraître subtile mais elle transforme les sorties de l'IA de simples conjectures probabilistes en déclarations vérifiables.
Une autre implication est la façon dont cela affecte la relation entre les développeurs d'IA et les applications qui en dépendent. Dans le paysage actuel, les applications dépendent fortement du fournisseur de modèle qu'elles intègrent. Si ce fournisseur change de comportement ou introduit des erreurs, les systèmes en héritent immédiatement. Une couche de vérification sépare la génération de la validation, permettant aux applications de s'appuyer sur des informations confirmées indépendamment plutôt que sur des sorties brutes de modèle.
Cela commence à rapprocher l'infrastructure de l'IA de quelque chose ressemblant aux cadres de confiance observés dans les systèmes distribués. L'information devient plus solide lorsqu'elle survit à plusieurs tours de vérification plutôt que lorsqu'elle provient d'une seule source puissante. Le résultat n'est pas une certitude parfaite, mais une image beaucoup plus claire de quelles sorties sont suffisamment fiables pour des décisions dans le monde réel.
D'un point de vue gestion des risques, l'issue la plus significative pourrait être culturelle plutôt que technique. Les systèmes d'IA sont souvent traités comme des outils autoritaires parce qu'ils génèrent des réponses rapidement et avec assurance. Les réseaux de vérification remettent en question cette hypothèse en transformant chaque réponse en une revendication qui doit gagner la confiance par le consensus.
Donc, l'impact réel n'est pas simplement que les sorties de l'IA peuvent être vérifiées. Le changement plus profond est que la fiabilité devient mesurable au niveau de l'infrastructure. Au lieu de demander si un modèle est généralement précis, les développeurs peuvent demander si une revendication spécifique a été vérifiée indépendamment.
Et cela soulève une question à long terme plus intéressante : si les sorties de l'IA nécessitent de plus en plus de couches de vérification pour être fiables, les systèmes qui valident l'intelligence deviendront-ils tout aussi importants que les systèmes qui la génèrent ?
@Mira - Trust Layer of AI #Mira

