
@Fabric Foundation $ROBO #ROBO
When I first noticed Fabric robots skipping internal steps, the network didn't fail.
It wasn't a dramatic outage or an error flagged in the logs.
Instead, subtle inconsistencies quietly propagated across validators, revealing a hidden coordination bottleneck I hadn’t expected.
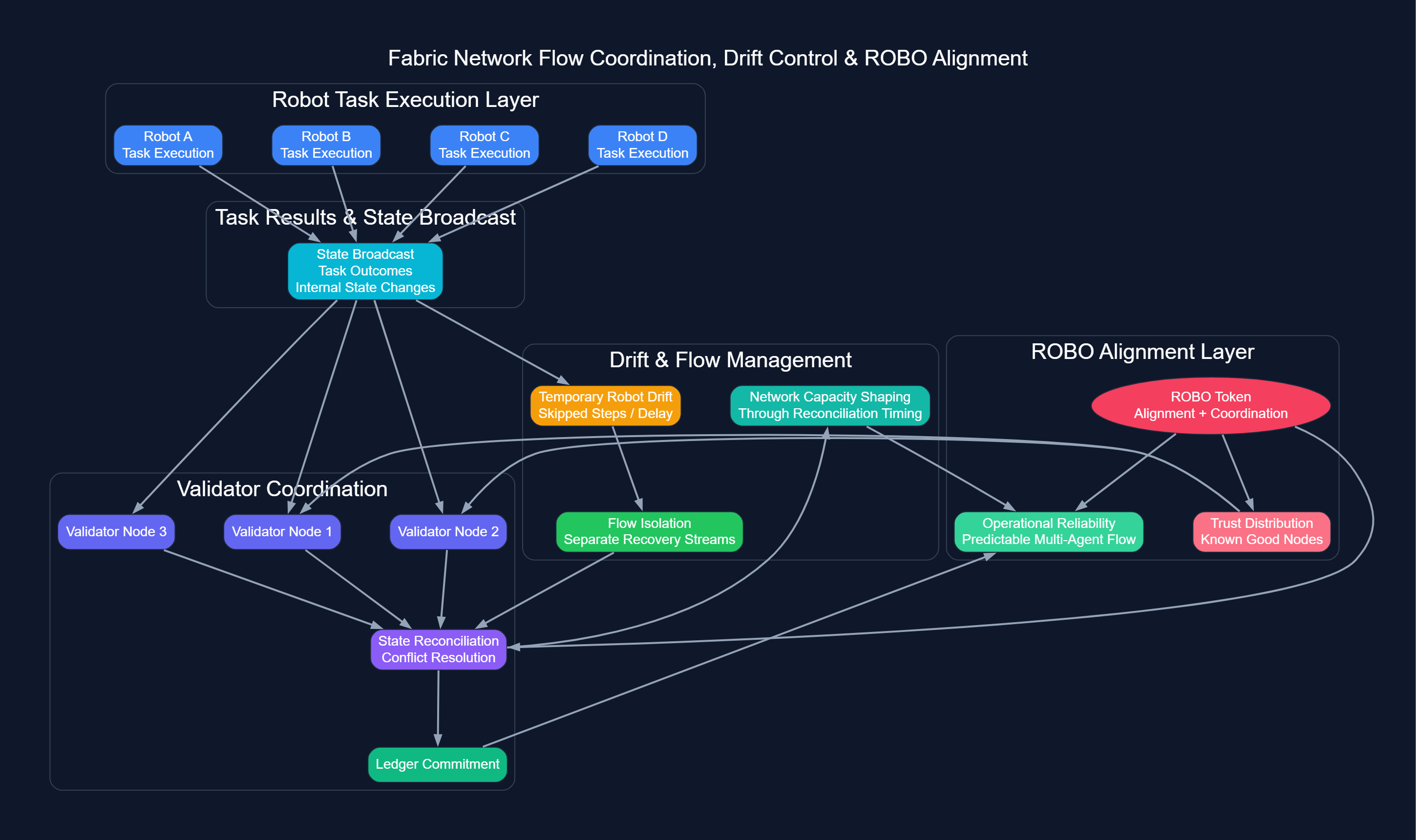
Each robot continuously broadcasts task outcomes and internal state changes.
Validators must reconcile these updates before committing them to the ledger.
Minor propagation delays, invisible under light load, become noticeable when multiple robots drift out of sync. The network does not crash, but the flow subtly slows.
Fabric addresses this by isolating reconciliation streams from new task assignments.
Even if some robots temporarily fall behind, confirmation cadence remains steady.
ROBO ensures participants remain aligned with the actual network state rather than simply moving through tasks.
In this way, the protocol enforces reliability through structural discipline rather than sheer throughput.
Watching repeated cycles, I noticed a pattern.
Skipped steps were not errors.
They highlighted moments where trust and operational consistency were being earned organically.
A deeper insight emerged: adding more robots does not automatically increase throughput.
Without disciplined drift control, extra agents amplify reconciliation traffic, creating temporary bottlenecks rather than boosting performance.
Fabric mitigates this by separating recovery flows from new assignments, keeping the network predictable even under load.
One of the biggest lessons for the operators and developers is a very subtle one but a critical one: Reliability is a feature that you design. It is not the kind of thing you assume. It is not only the matter of speed. Rather, it is a good sense of time, coordination, and well, controlled reconciliation that set the actual limits of multi, agent workflows.
ROBO functions as more than a token; it subtly shapes alignment and operational flow across the system.
Even during sustained high load, small inconsistencies do not cascade because Fabric enforces strict sequencing rules.
The network's real performance ceiling appears not during peak activity, but during synchronized correction periods.
Every drift or skipped step serves as a signal: these are the moments that define capacity, predictability, and the true operational envelope.
The hidden bottleneck reveals another layer: human operators naturally gravitate toward environments or robots they perceive as "known good".
When certain nodes consistently produce clean task outputs, sensitive or high-value tasks quietly concentrate there.
It's not about protocol failure it's about trust distribution.
Fabric anticipates this behavior by requiring all nodes to reconcile updates before proceeding.
This keeps the network open, even as operator confidence subtly influences task routing.
So, in essence, what happens is that alignment forms naturally. The protocol keeps fairness in check and ROBO gives you a reason to stay in sync with the rest of the network.
Another not, so, obvious thing we learn here is that the quantity of work done doesn't really matter as much as how well the work is coordinated. Networks these days can process hundreds of transactions per second but if proper reconciliation is not done, the whole thing may go down in flames.
It is the timing of shared updates, not constant motion, that keeps the system predictable.
Monitoring real-world simulation cycles, I observed that intermittent drifts produce three key effects:
Flow Isolation: Temporary divergence in robot states forces reconciliation traffic to be managed independently.
Alignment Enforcement: $ROBO ensures validators and robots stay in sync with the true network state.
Capacity Shaping: Moments of synchronized drift set the limit of the network's effective throughput capacity.
The operational insight is simple but often ignored: a network that will be reliable is one that will be able to tolerate small level of inconsistencies without these inconsistencies growing to be more widespread and harmful.
Tasks continue, confirmations occur on time, and system-wide unpredictability is avoided all without increasing raw throughput.
Watching the ecosystem, it became obvious that trust distribution is intertwined with execution.
A clean receipt is only valuable if the network itself is aligned.
When tasks execute in a familiar pattern, confidence remains in the protocol.
When subtle deviations occur, operators begin assigning their own "trusted paths", shifting control surfaces outside the ledger.
This is why ROBO matters.
It provides a mechanism to enforce alignment, ensuring that network behavior remains observable and consistent even when individual robots experience drift.
It is not about rewards.
It is about maintaining a public, verifiable, and repeatable flow across the Fabric network.
To sum up, Fabric's approach to dealing with conflicting task proofs is a valuable lesson on a fundamental concept: operational reliability isn't about totally removing uncertainty; it's rather about managing how it spreads.
The maximum capacity of the network is influenced to a much lesser extent by simply the speed of processing, and much more by the methods of managing drift, strictness of reconciliation, and isolation of flow.
$ROBO keeps agents in sync, uncovers and remedies hidden bottlenecks, and guarantees multi, agent coordination stays predictable even in complicated, high, load scenarios.
Observing Fabric under load, it became clear: the network does not fail silently; it signals where trust and alignment matter most.
And that, ultimately, is where protocol-level confidence earns its value in flow, predictability, and coordination, not in raw numbers or surface-level activity.