
J'ai commencé à remarquer quelque chose d'étrange en utilisant des outils d'IA pour la recherche.
Les réponses semblaient soignées.
Les explications semblaient convaincantes.
Mais parfois, lorsque je vérifiais les détails… certaines parties de l'information n'existaient tout simplement pas. Pas intentionnellement faux. Juste incorrect avec assurance.
Plus je lis sur le fonctionnement des grands modèles de langage, plus cela devient clair. Ces systèmes ne “savent” pas vraiment des faits. Ils génèrent la séquence de mots la plus probable basée sur des motifs dans les données d'entraînement. Ce processus est puissant pour la créativité et le raisonnement, mais il crée également deux problèmes persistants dans les systèmes d'IA.
Hallucinations.
Et biais.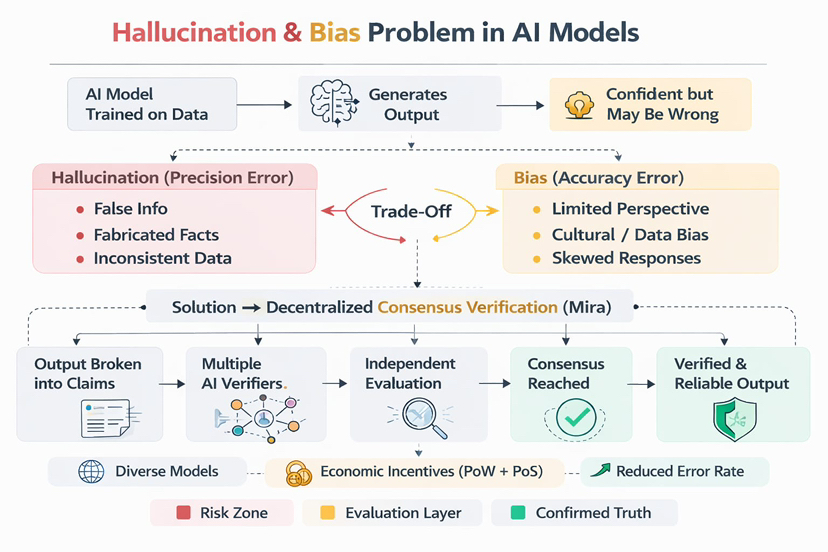
Les hallucinations apparaissent lorsque le modèle génère en toute confiance des informations qui sont fausses ou fabriquées. Le biais apparaît lorsque le modèle penche systématiquement vers certaines perspectives ou motifs intégrés dans ses données d'entraînement.
Essayer de corriger l'un rend souvent l'autre pire.
Si les développeurs réduisent les hallucinations en filtrant soigneusement les ensembles de données, le modèle peut devenir plus biaisé car il apprend d'un ensemble de perspectives plus étroit. S'ils élargissent les données d'entraînement pour réduire le biais, les hallucinations tendent à augmenter car la base de connaissances devient plus incohérente.
C'est presque comme un compromis intégré dans l'architecture elle-même.
En lisant récemment sur ce problème, je suis tombé sur l'approche proposée par Mira.
Au lieu d'essayer de construire un seul modèle parfait, Mira considère la fiabilité comme un problème de réseau plutôt qu'un problème de modèle.
Ce changement de pensée m'a immédiatement frappé.
Le système fonctionne en prenant des résultats générés par l'IA et en les divisant en revendications vérifiables plus petites. Chaque revendication est ensuite évaluée par plusieurs vérificateurs d'IA indépendants opérant au sein du réseau.
Au lieu de faire confiance au raisonnement d'un seul modèle, le système s'appuie sur une vérification collective.
Différents modèles vérifient la même affirmation.
Différentes perspectives l'analysent.
Si suffisamment de validateurs sont d'accord, la revendication est considérée comme fiable.
Ce qui rend le système intéressant, c'est que ce processus se déroule à l'intérieur d'une infrastructure décentralisée sécurisée par des incitations économiques. Les opérateurs de nœuds effectuant des tâches de vérification sont récompensés pour leur participation honnête grâce à des mécanismes combinant la computation de type preuve de travail et l'engagement de type preuve d'enjeu.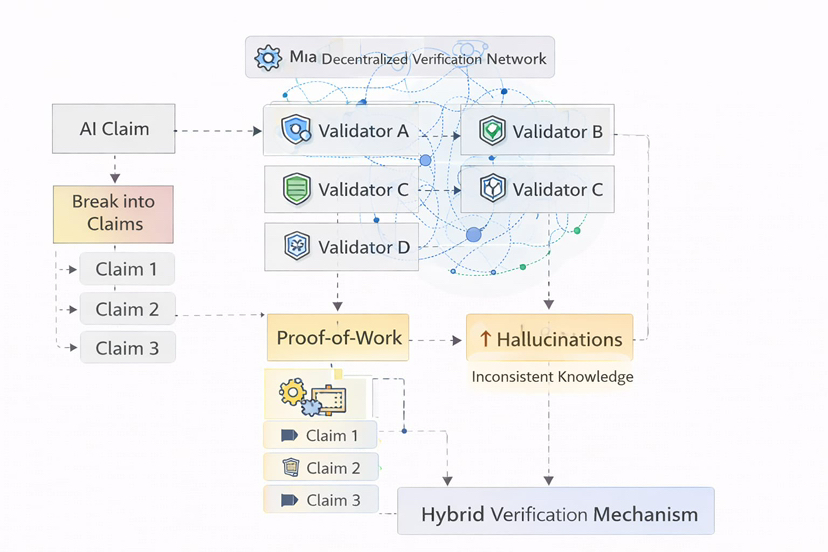
Cela signifie que les validateurs sont économiquement motivés à fournir une vérification précise plutôt qu'à manipuler les résultats.
D'une certaine manière, le système traite l'information comme une transaction blockchain.
Non accepté parce qu'une entité dit que c'est vrai... mais parce qu'un réseau atteint un consensus.
Une autre partie qui a attiré mon attention est la façon dont cette structure pourrait encourager la diversité parmi les modèles d'IA. Au lieu de s'appuyer sur une architecture de modèle dominante, le réseau bénéficie de la participation de différents modèles spécialisés qui agissent en tant que vérificateurs.
Certains pourraient être meilleurs en raisonnement scientifique. D'autres pourraient se spécialiser dans les connaissances historiques ou le contexte régional.
Ensemble, ils créent quelque chose de plus proche de l'intelligence collective que du raisonnement isolé des machines.
En réfléchissant à l'avenir des systèmes d'IA autonomes, cette idée devient encore plus pertinente. Si l'on s'attend à ce que l'IA fonctionne sans supervision humaine constante — gérant l'infrastructure, coordonnant la robotique ou assistant la recherche scientifique — la fiabilité devient critique.
Une seule sortie hallucination pourrait déclencher des conséquences dans le monde réel. Mais si chaque revendication passe d'abord par une couche de vérification décentralisée, le risque devient beaucoup plus petit.
Ce que je trouve intéressant à propos de Mira, c'est qu'il ne promet pas une IA parfaite.
Au lieu de cela, il essaie de construire un système qui détecte et filtre les erreurs avant qu'elles n'aient de l'importance. L'industrie de l'IA aujourd'hui est principalement axée sur la construction de modèles plus grands avec plus de paramètres et plus de données d'entraînement.
Mais parfois, la véritable percée n'est pas de rendre la machine plus intelligente. Parfois, c'est de construire des systèmes qui rendent l'intelligence digne de confiance.
@Mira - Trust Layer of AI #Mira $MIRA
