I noticed it during a routine verification sweep on the Fabric Foundation infrastructure.
Nothing dramatic. Just a simple automation that checks whether certain validator attestations for $ROBO were still fresh enough to be considered valid by downstream jobs.
The task runs every few minutes.
It has been running for months.
And yet one morning the queue looked… wrong.
Not broken. Just slow in a way that didn’t make sense.
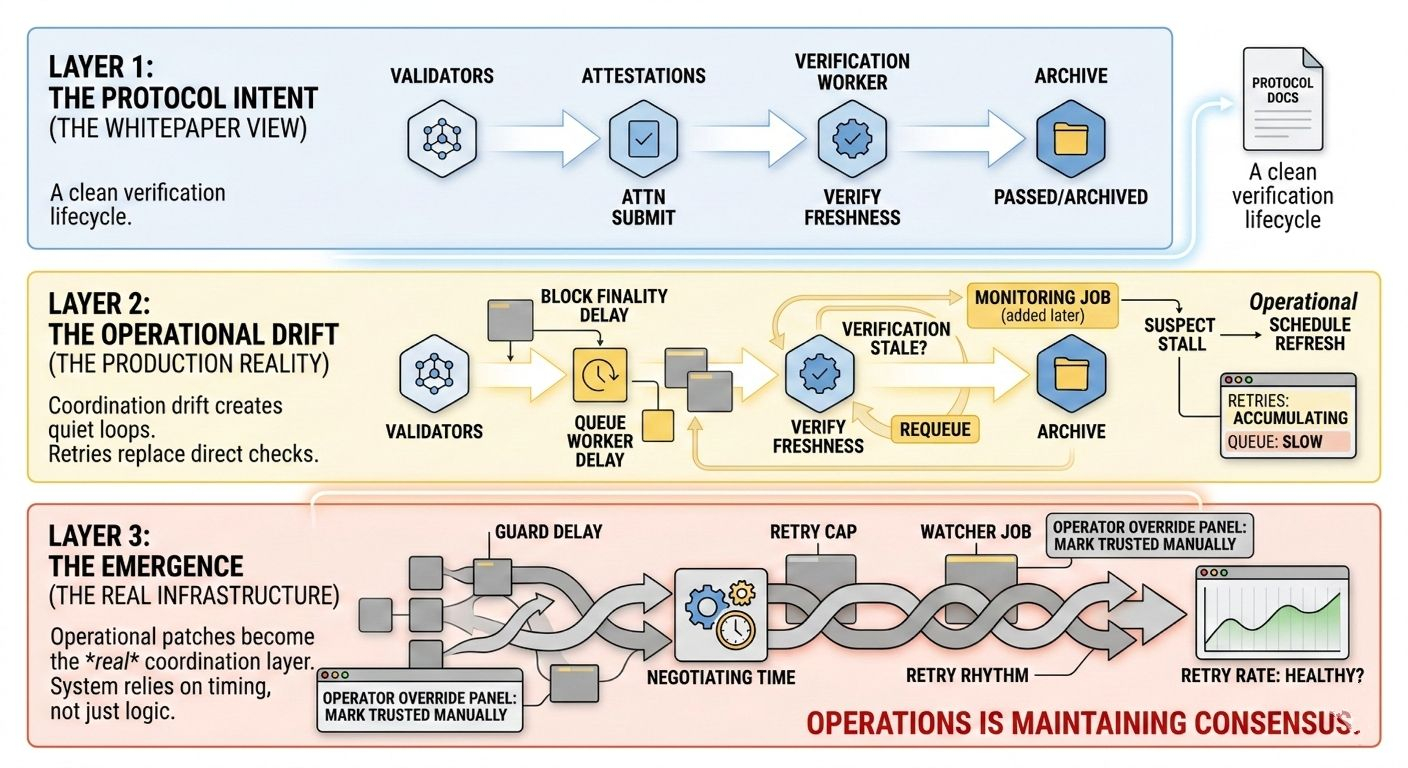
The system expected a fairly clean sequence. Validators submit attestations. The verification worker picks them up. The freshness window passes, and older attestations get archived. New ones replace them.
Simple lifecycle.
At least on paper.
But in production the workers were quietly retrying the same verification tasks over and over. Not because the attestations were invalid. Because the freshness check itself had become slightly stale by the time the worker evaluated it.
A few seconds here.
A queue delay there.
Nothing catastrophic.
But enough to create a loop.
The worker would pick up a job, check the timestamp, decide the data might be outdated, schedule a refresh, and requeue the verification.
Then another worker would pick it up.
Repeat.
At first we assumed it was just temporary queue pressure. Web3 infrastructure often behaves this way during traffic spikes. But traffic was normal.
So we started tracing the pipeline more carefully.
The issue wasn’t a single bug.
It was coordination drift.
The verification logic assumed that three things happened roughly at the same time:
attestation arrival
verification scheduling
freshness evaluation
In reality those three clocks were drifting apart.
Block finality introduced a delay.
Queue workers introduced another.
Then monitoring jobs began triggering refreshes if they suspected the verification stage had stalled.
That monitoring job had been added months earlier after a completely different incident.
At the time it seemed harmless.
Just a safety net.
But now it meant that verification freshness was no longer determined by the protocol logic alone. It was influenced by a monitoring script running on a different schedule.
So the pipeline started to oscillate.
Not failing.
Just circling around itself.
Retries began to accumulate.
We added a guard delay.
Then a retry cap.
Then a watcher job to detect excessive refresh cycles.
Later someone added a small manual override panel so operators could mark certain attestations as trusted even if freshness checks disagreed.
None of these fixes felt architectural.
They were small operational patches.
But over time something subtle happened.
Those patches became the real coordination layer.
The protocol documentation still described a clean verification lifecycle. But the production system was now relying on retry timing, queue ordering, monitoring triggers, and occasional human intervention.
The verification pipeline wasn’t just checking attestations anymore.
It was coordinating time.
And time is messy in distributed systems.
Blocks finalize late.
Workers wake up at different intervals.
Monitoring tools have their own schedules.
Eventually you realize the system isn’t really verifying data freshness.
It’s negotiating it.
And the negotiation happens through retries.
Retries slowly become infrastructure.
At some point we stopped asking whether the verification logic was correct.
Instead we asked whether the retry rhythm looked healthy.
Which is a strange metric if you think about it.
But after running the system long enough, you start to see the pattern.
Protocols define rules.
Production systems define tolerances.
And somewhere between those two, a quiet layer emerges — a mix of queues, retries, watchers, and operator intuition.
That layer rarely appears in whitepapers.
But it’s the layer that actually keeps the network moving.
If the Fabric Foundation system coordinating $ROBO stopped accepting new attestations tomorrow, the protocol wouldn’t collapse immediately.
The retry loops would keep things alive for a while.
Monitoring would stretch the freshness windows.
Operators would approve edge cases manually.
The system would keep working.
Which is slightly uncomfortable to admit.
Because at that point you realize the protocol isn’t the only thing maintaining consensus.
Operations is.
$ROBO @Fabric Foundation #ROBO