je parcourais le livre blanc du protocole SIGN et quelques démos d'intégration, essayant surtout de comprendre pourquoi il continue d'apparaître dans les outils de distribution. à première vue, cela semble assez simple : définir des identifiants, les vérifier, puis utiliser cela pour décider qui reçoit des jetons. un peu comme formaliser les tableurs et scripts désordonnés que les équipes utilisent déjà.
et oui, je pense que c’est ainsi que la plupart des gens le voient. une couche d'attestation plus quelques mécanismes de largage intégrés. utile, mais pas exactement un nouveau primitif.
mais ce n’est pas le tableau complet.
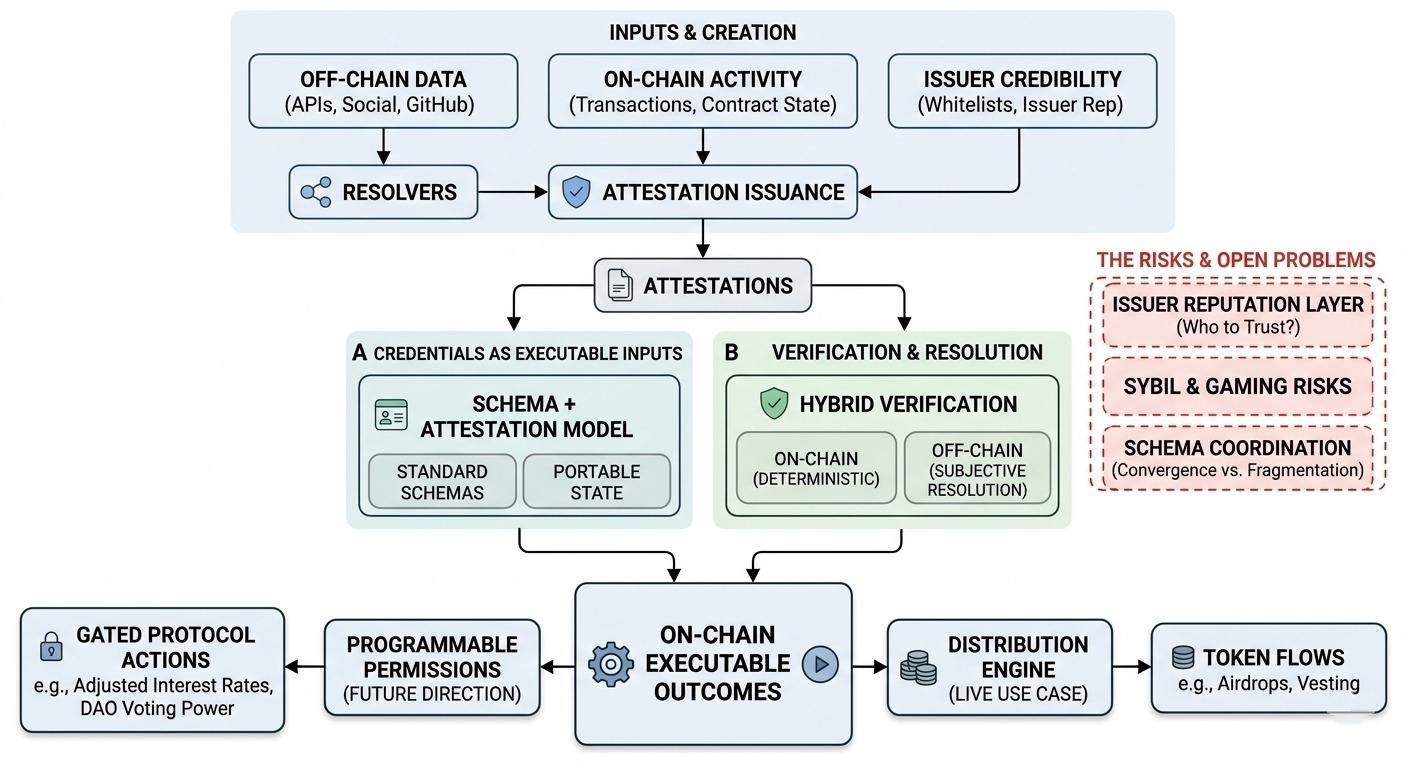
ce que SIGN fait discrètement, c'est transformer les identifiants en quelque chose d'exécutable. pas seulement des enregistrements que vous interrogez, mais des entrées qui entraînent directement des résultats on-chain. et une fois que les identifiants commencent à déclencher des actions — en particulier des flux de jetons — ils cessent d'être des données passives et commencent à se comporter davantage comme une infrastructure.
la première pièce est le modèle de schéma + attestation. rien de nouveau conceptuellement — les schémas définissent la structure, les attestations les remplissent de revendications. mais SIGN s'engage dans la normalisation des schémas d'une manière qui suggère une réutilisation à travers les applications. pas seulement « cette application définit un identifiant », mais « cet identifiant pourrait exister indépendamment de n'importe quelle application unique. »
et c'est là que cela devient intéressant. si les schémas deviennent réellement partagés, alors les identifiants commencent à ressembler à un état portable. l'« histoire » ou la « réputation » d'un utilisateur n'est pas verrouillée dans un seul système. mais cela dépend fortement de la coordination. les schémas n'ont d'importance que si plusieurs parties s'accordent sur eux, et cet accord n'est pas appliqué par le protocole.
une partie de cela est en direct — des projets émettent des attestations et utilisent des schémas en interne. mais la réutilisation inter-applications semble encore faible. la plupart des équipes semblent définir ce dont elles ont besoin et passer à autre chose, plutôt que de s'ancrer dans des normes partagées.
le deuxième mécanisme est la couche de vérification, en particulier le modèle hybride. SIGN prend en charge la vérification on-chain (déterministe, basée sur des contrats) et la résolution off-chain (données externes, API, heuristiques). sur le papier, c'est juste de la flexibilité.
mais voici la chose — mélanger ces deux crée une frontière de confiance divisée. la vérification on-chain est uniforme, tout le monde voit le même résultat. la résolution off-chain introduit de la subjectivité, selon la manière dont les résolveurs sont mis en œuvre et maintenus.
donc maintenant, un identifiant n'est pas juste « vrai ou faux », c'est « vrai selon la manière dont vous le résolvez. » ce qui est acceptable pour les données du monde réel, mais cela complique la composition. deux applications pourraient consommer la même attestation mais arriver à des conclusions légèrement différentes.
cette approche hybride est déjà en cours d'utilisation, en particulier dans les vérifications d'éligibilité qui s'appuient sur des signaux off-chain. mais normaliser le comportement des résolveurs, ou même convenir des variations acceptables, semble être un problème ouvert.
le troisième est le moteur de distribution, qui est probablement la partie la plus concrète aujourd'hui. SIGN connecte les identifiants directement à la logique de distribution de jetons. définissez l'éligibilité via des attestations, puis exécutez des distributions sans exporter de listes ou écrire des scripts personnalisés.
cela est clairement en direct et en cours d'utilisation. cela réduit les frais généraux opérationnels et rend les distributions plus reproductibles. mais cela déplace aussi où se situe la complexité. au lieu de script des distributions manuellement, vous encodez la logique dans des schémas et des règles de vérification.
et je ne suis pas entièrement sûr que cela soit toujours plus simple — juste différent. la complexité passe de scripts ad hoc à des définitions structurées, qui sont plus faciles à réutiliser mais plus difficiles à raisonner lorsque les choses tournent mal.
les parties les plus tournées vers l'avenir — couches d'identité persistantes, portabilité des identifiants inter-chaînes, intégrations plus profondes des portefeuilles — semblent plus être une direction qu'une réalité. elles dépendent de la réutilisation des identifiants à travers les écosystèmes, ce qui ramène à la coordination des schémas et à la confiance dans les émetteurs.
une chose que je continue à remettre en question est la crédibilité des émetteurs. si n'importe qui peut émettre des attestations, alors le système a besoin d'un moyen de les pondérer. sinon, vous obtenez une inondation d'identifiants à faible signal. SIGN ne fait pas respecter cette couche — elle la laisse aux applications ou aux extensions futures.
vous vous retrouvez donc avec un problème de second ordre : pas seulement vérifier les identifiants, mais décider quels émetteurs comptent. et cela peut devenir rapidement désordonné.
je me demande aussi comment cela tient face à des conditions adversariales. attaques Sybil, émetteurs collusoires, manipulation de schéma — aucun de ces éléments n'est unique à SIGN, mais le protocole facilite la mise en œuvre des identifiants à grande échelle, ce qui pourrait amplifier ces problèmes.
curieux à propos de :
* si les schémas convergent réellement ou restent fragmentés par projet
* comment les résolveurs off-chain évoluent et s'ils se normalisent
* si la distribution reste le principal cas d'utilisation ou juste le point d'entrée
* émergence de la réputation des émetteurs ou de couches de filtrage
* exemples réels d'identifiants réutilisés à travers des écosystèmes non liés
#signdigitalsovereigninfra @SignOfficial $SIGN