Je n'ai pas vraiment pris l'IA privée au sérieux au début.
Pas parce que l'idée est mauvaise mais parce que la plupart du temps, cela signifie simplement cacher les données mieux tout en les déplaçant. Cryptez-les, envoyez-les, traitez-les ailleurs, espérez que rien ne fuit. Ce modèle n'a pas beaucoup changé.
Et si vous pensez aux environnements d'entreprise ou réglementés, ce modèle est exactement là où les choses échouent.
Les données qui comptent vraiment, les dossiers financiers, le comportement des clients, les signaux de risque internes, sont le type de données qui légalement et opérationnellement ne sont pas censées quitter leur frontière en premier lieu.
Ainsi, chaque fois que l'IA a besoin que ces données se déplacent, vous négociez déjà avec la conformité avant même d'arriver au modèle.
C'est là que @MidnightNetwork a commencé à se sentir différent pour moi.
Pas parce qu'il dit que nous protégeons les données, mais parce qu'il supprime discrètement le besoin de les déplacer.
Et une fois que vous voyez cela, toute l'idée de « prouver un résultat sans révéler les entrées » cesse de sembler être une caractéristique et commence à ressembler à la seule configuration fonctionnelle pour l'IA réglementée.
Je pensais auparavant que la partie difficile de l'IA d'entreprise était l'exactitude du modèle.
Maintenant, il semble que le véritable goulot d'étranglement soit la permission.
Qui est autorisé à voir quoi, où les données peuvent exister, et combien de copies sont créées pendant le traitement.
Parce qu'une fois que les données traversent les systèmes, même si elles sont cryptées, elles laissent des traces. Journaux, états de mémoire, résultats intermédiaires, couches d'accès. Des choses qui intéressent finalement les audits.
Midnight aborde ce problème sous un angle différent.
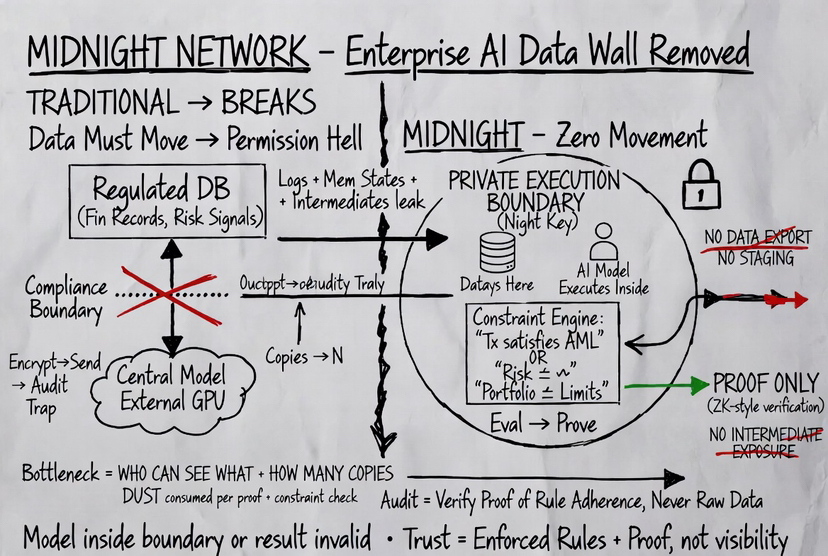
Vos données se trouvent à l'intérieur d'une frontière d'exécution privée définie par la clé Night.
À première vue, cela ressemble à un contrôle d'accès. Mais c'est plus strict que cela.
Il ne s'agit pas seulement de savoir qui peut lire les données.
Il définit où le calcul sur ces données est autorisé à se produire.
Si un modèle fonctionne en dehors de cette frontière, le système ne considère pas son résultat comme valide.
C'est une contrainte forte, et cela change la façon dont les pipelines d'IA sont construits.
Au lieu de tirer des données dans un modèle central, le modèle fonctionne à l'intérieur de la frontière des données.
Rien n'est exporté.
Aucun jeu de données copié, aucune couche de staging, aucun environnement de traitement externe.
Et plus important encore, aucune exposition intermédiaire.
Le côté sortie est là où cela devient intéressant.
Dans la plupart des systèmes, la sortie n'est qu'un résultat, un score, une classification, une prédiction.
Sur Midnight, la sortie est liée à une condition.
Pas une explication complète, pas de valeurs brutes, une déclaration spécifique qui peut être vérifiée.
Quelque chose comme : cette transaction satisfait les règles de conformité, ce score de risque est en dessous du seuil, ce portefeuille est resté dans les limites définies.
Ce ne sont pas des vérifications lâches.
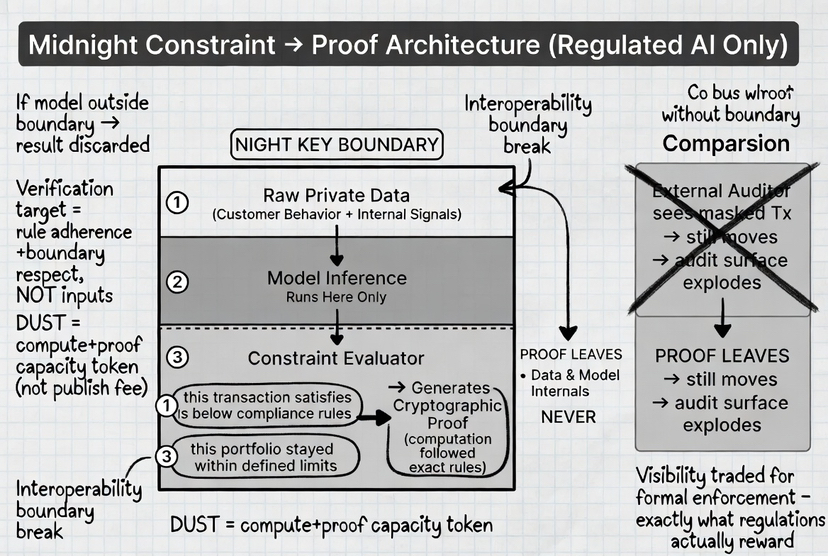
Elles sont encodées comme des contraintes, des règles strictes que le système peut évaluer.
Ainsi, le flux devient différent de ce à quoi nous sommes habitués.
Le modèle fonctionne localement sur des données privées.
Il évalue la contrainte définie.
Ensuite, il génère une preuve que cette contrainte est respectée.
Cette preuve est ce qui quitte le domaine privé.
Rien d'autre ne le fait.
Ce que le réseau vérifie n'est pas les données et pas les internes du modèle.
Il vérifie que le calcul a suivi les règles définies et a produit un résultat valide.
C'est là que Midnight va au-delà de la vérification ZK générique.
Ce n'est pas juste prouver des résultats après le calcul.
Il s'agit de faire en sorte qu'une computation valide ne puisse se produire qu'à l'intérieur de cette frontière privée en premier lieu.
Cette combinaison compte beaucoup pour une utilisation en entreprise.
Parce que dans les environnements réglementés, il ne suffit pas que quelque chose soit correct.
Il doit être prouvé correct sans exposer des données restreintes.
Et c'est exactement le fossé que la plupart des systèmes échouent à combler.
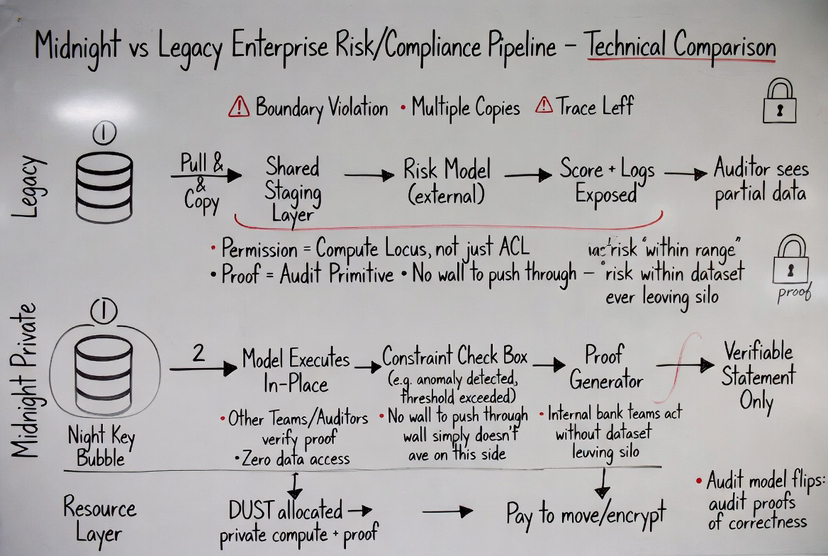
Prenez quelque chose comme des vérifications de conformité dans les systèmes financiers.
Normalement, vérifier la conformité signifie exposer les détails des transactions aux auditeurs ou aux systèmes externes.
Même si elles sont partiellement masquées, les données continuent de circuler.
Avec Midnight, la logique de conformité fonctionne à l'intérieur du domaine privé.
Le système prouve que la transaction satisfait les règles requises.
Une partie externe peut vérifier la preuve et accepter le résultat.
Mais les données transactionnelles elles-mêmes ne quittent jamais.
Cela change le modèle d'audit.
Au lieu d'auditer des données brutes, vous auditez des preuves de correction.
C'est une approche très différente, mais elle s'aligne mieux avec la façon dont les réglementations fonctionnent réellement, elles se soucient du respect des règles et non d'une exposition inutile.
Un autre cas où cela compte est l'IA d'entreprise interne.
Pensez à une banque exécutant des modèles de risque sur des données clients.
Aujourd'hui, ces modèles sont fortement restreints car les données ne peuvent pas être partagées librement entre les équipes ou les systèmes.
Avec Midnight, le modèle peut fonctionner là où les données existent déjà.
La sortie est transformée en une déclaration vérifiable : risque dans une plage acceptable, anomalie détectée, seuil dépassé.
D'autres systèmes peuvent agir sur ce résultat sans jamais accéder au jeu de données sous-jacent.
Ainsi, vous obtenez l'interopérabilité sans briser les frontières des données.
Le rôle de DUST devient également plus clair ici.
Ce n'est pas juste un mécanisme de frais.
Cela représente la capacité requise pour exécuter ces calculs privés et générer des preuves.
Chaque évaluation de modèle, chaque vérification de contrainte, chaque preuve, tout cela consomme DUST.
Donc, au lieu de payer pour publier des données, vous allouez des ressources pour produire des résultats vérifiables.
C'est un meilleur ajustement pour l'IA d'entreprise, où le coût est dans le calcul et la validation, pas dans la diffusion d'informations.
Ce qui me frappe, c'est que Midnight n'essaie pas de rendre l'IA plus privée de manière superficielle.
Cela restructure le pipeline afin qu'aucune exposition ne soit jamais requise.
Et c'est ce qui le rend pertinent pour les environnements réglementés.
Parce que ces environnements n'ont pas besoin seulement de confidentialité.
Ils ont besoin de contrôle sur où se trouvent les données, comment elles sont traitées, et ce qui peut être révélé.
Je vais être honnête, le compromis ici est que vous perdez en visibilité.
Vous ne voyez pas les données brutes, vous n'inspectez pas chaque étape.
Vous comptez sur des preuves.
Au début, cela ressemble à un abandon.
Mais quand vous pensez aux systèmes d'entreprise, cette visibilité n'a jamais été totalement disponible de toute façon, elle était restreinte, cloisonnée, contrôlée.
Midnight formalise simplement cette contrainte et construit autour.
Si quelque chose, cela change à quoi ressemble la confiance.
Pas de confiance dans les données.
Pas de confiance dans le modèle.
Faites confiance au fait que le système applique des règles et prouve qu'elles ont été suivies.
Et pour l'IA réglementée, c'est probablement la seule version qui évolue.
Parce que plus les données deviennent sensibles, moins elles peuvent se déplacer.
Et les systèmes qui dépendent encore de son déplacement vont toujours frapper le même mur.
Midnight n'essaie pas de percer ce mur.
Cela construit juste du côté où le mur n'existe plus.