
Je ne l'ai pas remarqué au début. OpenLedger ressemblait à un projet IA de plus qui s'était drapé dans une promesse plus propre et plus nette.
La première chose que j'ai remarquée était la couche de surface. DataNets, provenance, attribution, flux de récompenses. Tout semblait suffisamment ordonné, presque familier si vous avez vu suffisamment de projets d'infrastructure essayer de rendre l'apprentissage machine compréhensible.
Ce qui m'est resté, c'est à quel point cela semblait ordinaire au début. Un jeu de données est enregistré, un modèle l'utilise, et le système l'inscrit. Rien de dramatique. Juste un registre avec un nom plus ambitieux que la plupart.
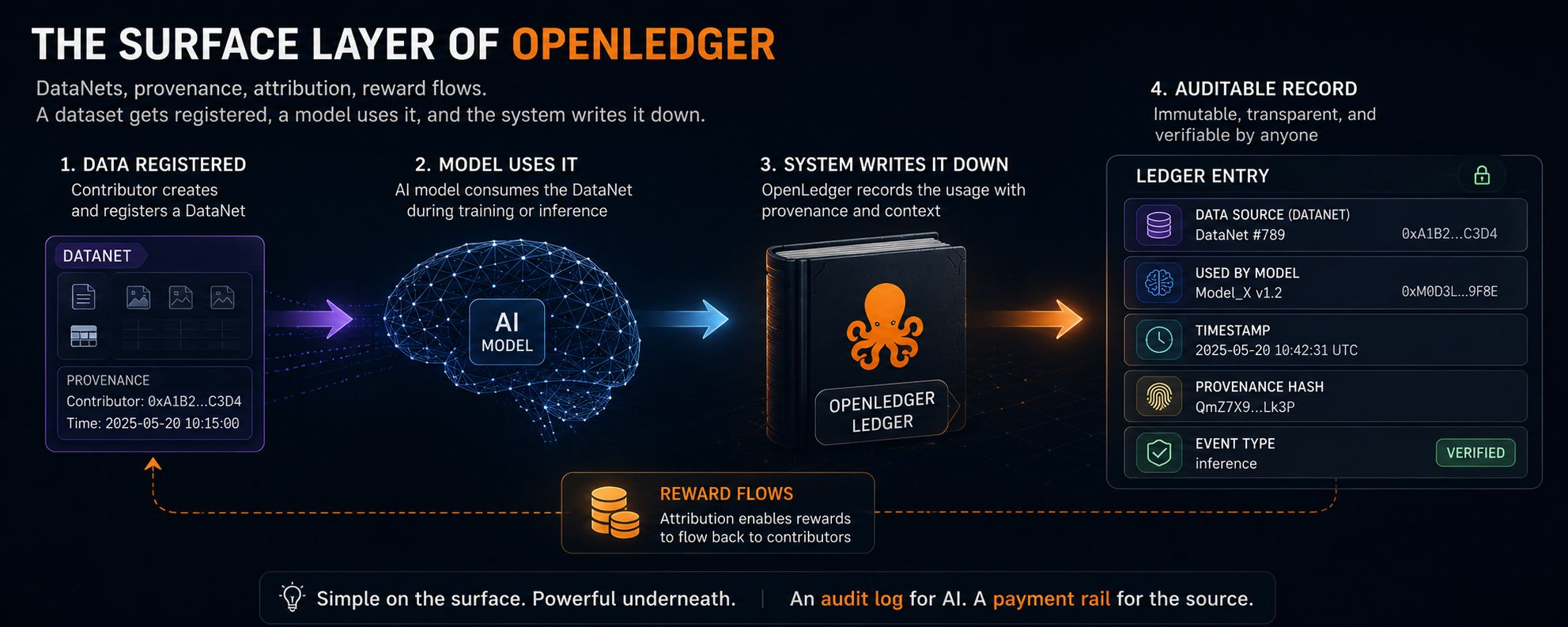
Ensuite, j'ai regardé deux contributeurs construire des DataNets qui semblaient suffisamment similaires pour être interchangeables. Même type de structure. Même type d'effort. Pourtant, l'un continuait d'apparaître dans les traces aval tandis que l'autre bougeait à peine.
C'est là que la friction a commencé. Ça semblait légèrement déséquilibré d'une manière qui n'avait rien à voir avec la qualité visible en surface. La différence n'était pas qui a posté le plus ou qui est arrivé en premier. C'était à propos des données qui devenaient utiles plus tard, et si le système pouvait réellement voir cette utilité lorsque le modèle répondait à quelqu'un d'autre.
Je ne suis pas encore totalement convaincu, mais c'est là que OPEN a commencé à m'apparaître différemment. Il ne semble pas se poser au sommet de la pile d'IA comme un jeton décoratif. Il se trouve à l'intérieur même de l'acte d'attribution, où la sortie est retracée jusqu'aux données qui l'ont rendue possible et où le paiement peut suivre cette trace.
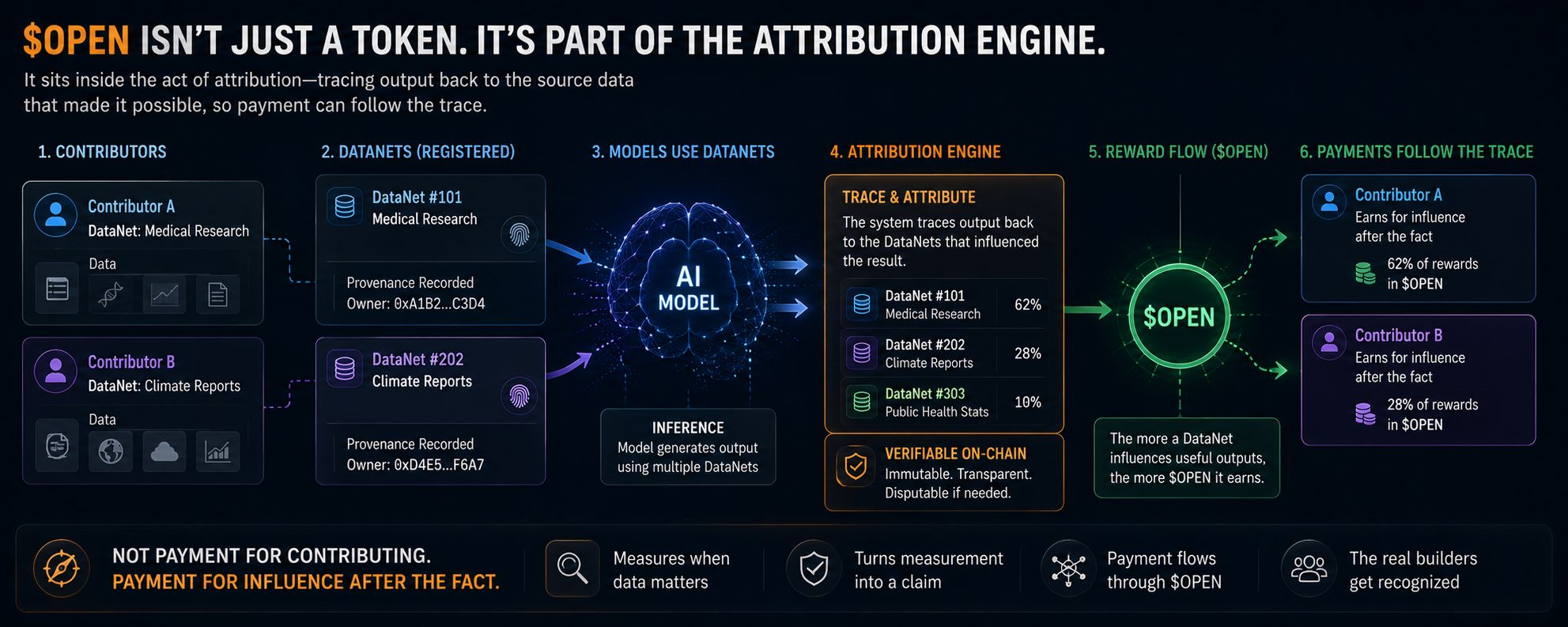
Cela change l'humeur de l'ensemble. Une fois que j'ai commencé à penser en ces termes, le registre a cessé de ressembler à un meuble de classement et a commencé à ressembler à un système de mémoire. Pas une archive statique. Quelque chose de plus proche d'un enregistrement vivant de quelles entrées continuent à refaire surface à l'intérieur de l'inférence.
Ça donne aussi l'impression que le côté contributeur ne ressemble pas à un téléchargement unique, mais plutôt à un pari long et incertain. Un DataNet peut être bien fait et rester silencieux. Un autre peut être plus désordonné et continuer à apparaître parce que le modèle s'appuie dessus. Je ne suis pas sûr si c'est intentionnel ou juste un effet émergent du design, mais c'est difficile à ignorer.
Et c'est la partie que je continue à retourner. OpenLedger ne dit pas seulement que les données comptent. Il essaie de mesurer quand les données comptent, puis de transformer cette mesure en une revendication. Cela semble plus structurel qu'un système de récompense normal, car la récompense n'est pas attachée à l'acte de contribution. Elle est attachée à l'influence après coup.
Cela commence à ressembler à un tout autre type de marché. Pas un marché pour le stockage. Pas même un marché pour l'accès. Plutôt un marché pour l'utilité répétée, où la même contribution peut encore compter chaque fois qu'un modèle la cherche.

La chose la plus proche à laquelle je peux le comparer est un bureau de circulation de bibliothèque. Un livre assis sur une étagère est une chose. Un livre qui continue à être emprunté en est une autre. L'étagère compte, mais le record de mouvement compte encore plus.
OpenLedger semble se soucier de cette deuxième partie. Il veut savoir quelles pièces d'information continuent à être empruntées, copiées et remboursées via le protocole. C'est une idée plus troublante qu'elle n'en a l'air, car cela rend l'utilité mesurable d'une manière qui peut être contestée plus tard.
Pourtant, je ne peux pas ignorer la tension à l'intérieur. Si l'attribution est trop lâche, tout le système devient du théâtre. Si elle est trop exacte, les gens commenceront à façonner les DataNets autour de ce qui peut être tracé proprement au lieu de ce qui est réellement utile. Ce ne sont pas la même chose.
Il y a aussi le problème plus difficile de l'échelle. Un système comme celui-ci dépend de modèles révélant suffisamment d'eux-mêmes pour rendre les traces significatives. Si la sortie devient trop généralisée, ou si la trace devient trop bruyante, alors la boucle de paiement peut s'affaiblir sans que personne n'annonce qu'elle a échoué.
Je reviens toujours à ce même petit inconfort. OpenLedger veut rendre les données suffisamment visibles pour être payées, mais pas si simplifiées que le paiement devienne une fiction. Cet équilibre semble fragile.
Peut-être que c'est pourquoi OpenLedger est resté dans mon esprit après le premier coup d'œil. Il ne demande pas vraiment qui a construit le modèle. Il demande qui a continué à rendre le modèle possible.
Et cette question est plus difficile à laisser de côté.
\u003cm-72/\u003e\u003cc-73/\u003e\u003ct-74/\u003e\u003ct-75/\u003e
\u003cc-56/\u003e\u003cc-57/\u003e