
Il y a quelques années, « infrastructure » signifiait les fondations peu glamour sous tout le reste. Routes. Ports. Serveurs cloud. La couche dont personne ne se vantait, mais sur laquelle tout le monde comptait.
L'IA a changé cette conversation. L'infrastructure est soudainement devenue le sujet. GPU, clusters, couches d'inférence, capacité de calcul — tout cela a commencé à sonner comme la frontière. Le marché a commencé à traiter la puissance brute comme le principal goulot d'étranglement dans l'IA.
Ça avait du sens au début.
Mais plus les systèmes d'IA passent des démos à une utilisation réelle, moins le problème ressemble à de l'intelligence et plus il ressemble à de la responsabilité.
Un modèle écrivant de la poésie mal est assez inoffensif. Un modèle soutenant des décisions de crédit, des vérifications de conformité, la rédaction juridique, le filtrage d'identité ou l'allocation de capital est quelque chose de totalement différent. Une fois que l'IA touche des décisions réelles, la question centrale cesse d'être la vitesse à laquelle elle fonctionne.
Cela devient : qui est responsable quand cela échoue ?
Cette question est souvent sous-évaluée dans les récits d'IA crypto.
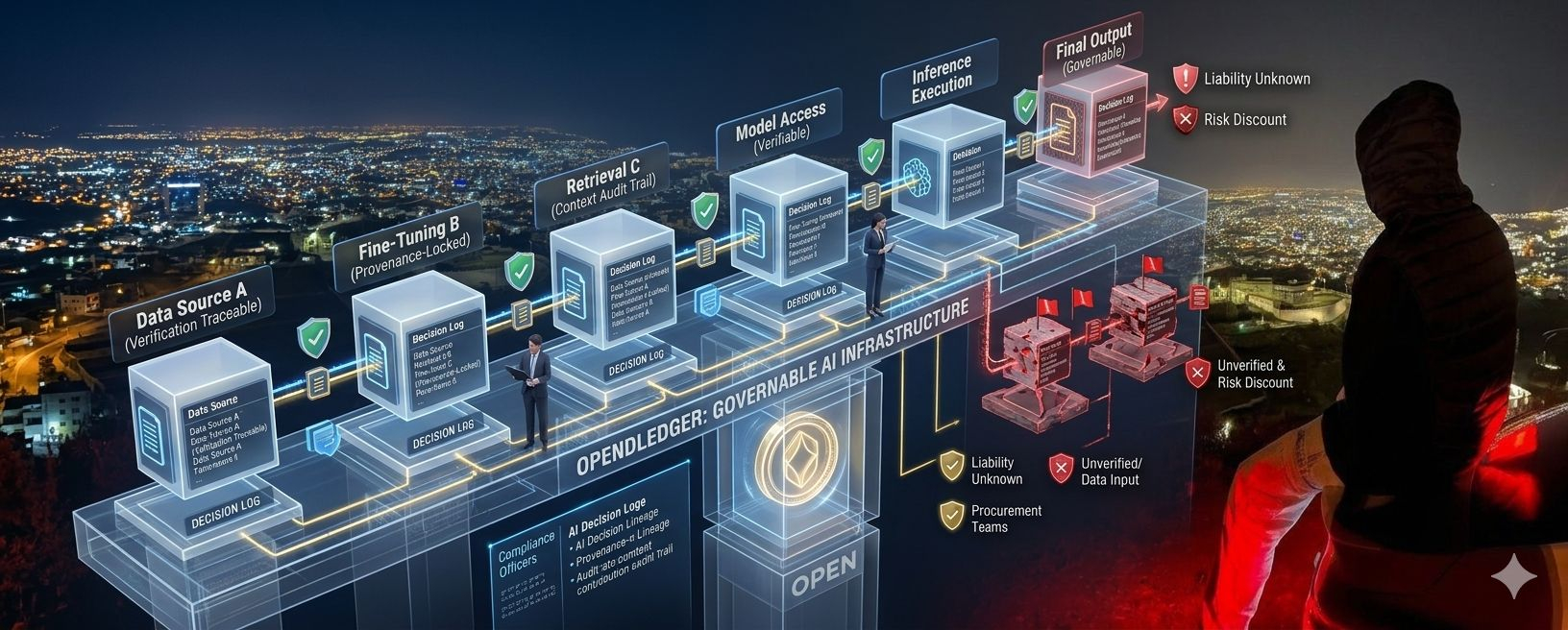
@OpenLedger est généralement présenté comme une infrastructure IA, et ce n'est pas faux. Mais ce cadre peut manquer de l'angle plus important. Beaucoup de gens parlent de l'attribution comme si c'était principalement un système de récompenses — un moyen de compenser équitablement les contributeurs. C'est utile, mais incomplet.
Dans des systèmes sérieux, l'attribution ne concerne pas seulement les incitations.
Il s'agit de cartographie de la responsabilité.
Et cela change la conversation.
Je pense toujours à la première vague d'enthousiasme pour les agents autonomes. Les gens parlaient d'agents effectuant des paiements, négociant des services, gérant des flux de travail et coordonnant des tâches à travers des systèmes. Techniquement impressionnant, bien sûr. Mais un problème plus profond était passé sous silence : si un agent produit un mauvais résultat parce que ses données, sa logique, son chemin de récupération ou sa source en amont étaient compromis, où se situe réellement la responsabilité ?
Cette réponse n'est pas claire.
Le logiciel traditionnel était plus simple d'une manière importante. Une entreprise livrait du code. Si quelque chose se cassait, la responsabilité était généralement traçable jusqu'au vendeur, à l'opérateur ou à l'implémentation. Pas simple, exactement, mais lisible.
Les systèmes IA sont plus fragmentés.
Une partie fournit des données. Une autre peaufine le modèle. Une autre héberge l'inférence. Une autre ajoute de l'orchestration. Une autre injecte un contexte de récupération. Une autre enrobe le flux de travail dans une logique commerciale. Au moment où un résultat atteint l'utilisateur final, la responsabilité a été distribuée à travers une chaîne d'acteurs.
Ce genre de diffusion rend le risque plus difficile à définir.
Et si le risque est plus difficile à définir, il est plus difficile à tarifer.
Les marchés n'aiment pas ça.
Les institutions n'aiment pas ça encore plus.
Les utilisateurs de détail peuvent tolérer l'incertitude si le produit semble magique. Les entreprises, en général, ne le font pas. Les banques ne le font certainement pas. Les environnements régulés ne le font absolument pas.
Personne ne se présente à une revue de conformité en disant que le modèle "paraissait digne de confiance".
Ils demandent la provenance. Des pistes de vérification. La lignée des sources. Des procédures d'escalade. De la documentation. Des journaux de décision. Quelque chose qu'ils peuvent défendre plus tard si un régulateur, un client ou une revue interne pose des questions inconfortables.
C'est là que #OpenLedger commence à sembler plus intéressant.
Si cela construit réellement une infrastructure autour de l'attribution vérifiable, alors la valeur la plus importante pourrait ne pas être qu'elle aide l'IA à évoluer plus rapidement.
Il se peut que cela aide l'IA à devenir gouvernable.
C'est une proposition moins excitante, mais souvent plus durable.
La gouvernabilité ne sonne pas aussi sexy que le calcul. Elle ne dominera pas les gros titres comme le font les benchmarks de modèles bruts ou les récits sur le matériel. Mais une infrastructure ennuyeuse a tendance à avoir une importance plus durable que l'infrastructure flashy.
Les marchés financiers offrent une comparaison utile. Au début, la vitesse comptait. Puis l'auditabilité est devenue importante. Ensuite, la conformité a compté. Avec le temps, les couches de contrôle sont devenues tout aussi précieuses que les couches d'exécution.
L'IA pourrait suivre un chemin similaire.
Pas parfaitement. Aucune analogie ne l'est. Mais le schéma rime.
Il y a aussi une vérité pratique qui est souvent négligée : les institutions ne sont pas anti-innovation. Elles sont anti-incertitude qu'elles ne peuvent pas opérationnaliser.
Cette distinction a de l'importance.
Une équipe d'approvisionnement évaluant l'IA ne se soucie pas de la narration propre au crypto. Elle se soucie de savoir si le système peut s'expliquer quand des questions juridiques, de risque ou de régulateurs commencent à être posées plus tard.
Et ils posent toujours des questions plus tard.
Prenez un exemple simple. Imaginez un outil IA utilisé pour soutenir la souscription d'assurance. Pas d'automatisation complète. Juste un soutien à la décision.
Maintenant, imaginez que le modèle produise des recommandations biaisées parce qu'une partie du pipeline de données sous-jacent était défectueuse, manipulée ou mal sourcée. Un client conteste la décision. La question s'intensifie. La gouvernance interne veut tracer la chaîne d'influence.
Si personne ne peut mapper cette chaîne de manière significative, l'organisation est laissée à improviser.
Dans des environnements régulés, l'improvisation est coûteuse.
C'est à ce moment-là que l'attribution cesse d'être une caractéristique philosophique et commence à devenir une infrastructure opérationnelle.
C'est pourquoi l'expression "responsabilité du modèle de tarification" ne me semble pas exagérée.
Pas de responsabilité juridique littérale, du moins pas encore.
Responsabilité économique d'abord.
Primes de confiance. Rabais de risque. Confiance des contreparties. Volonté d'intégration. Friction d'approvisionnement.
Ces facteurs sont souvent intégrés dans le prix bien avant que les cadres juridiques formels ne s'adaptent.
Si deux écosystèmes IA produisent des résultats similaires, mais que l'un offre une couche de provenance plus forte autour de la façon dont ces résultats ont été façonnés, les institutions peuvent préférer l'environnement plus auditable même s'il n'est pas le plus performant sur le papier.
Cela arrive dans d'autres industries tout le temps.
Des rails financiers audités surpassent des alternatives opaques.
Les chaînes d'approvisionnement de confiance surpassent celles incertaines.
Des contrôles fiables remportent discrètement des budgets.
Néanmoins, le scepticisme est justifié.
L'attribution dans l'IA est réellement difficile. L'influence de l'entraînement est diffuse. Le mélange des signaux est désordonné. Les poids de contribution peuvent devenir approximatifs au mieux et fictifs au pire si le système est mal conçu.
Cela compte, car la responsabilité factice peut être pire que l'opacité évidente.
Puis la crypto ajoute son propre ensemble de complications.
Le moment où l'attribution devient économiquement précieuse, le système invite à la manipulation.
Ensembles de données spam. revendications de contribution fabriquées. comportement sybil. exploitation de la réputation. distorsion des incitations.
Quiconque a passé du temps autour des incitations crypto sait à quelle vitesse un bon mécanisme peut devenir une surface d'attaque.
Donc, le vrai défi n'est pas seulement de construire l'attribution. C'est de construire une attribution qui reste utile dans des conditions adversariales.
Il y a aussi une question stratégique qui mérite d'être posée.
Les entreprises veulent-elles réellement une responsabilité décentralisée ?
Conceptuellement, cela semble élégant. En pratique, certaines organisations peuvent préférer un fournisseur centralisé précisément parce que la responsabilité semble plus facile à gérer de cette manière. Un fournisseur. Un contrat. Un chemin d'escalade.
La responsabilité distribuée peut devenir un chaos bureaucratique si le design est faible.
Donc, le défi d'OpenLedger n'est pas seulement technique. Il est aussi au niveau du produit.
Il faut que l'attribution distribuée semble opérationnellement utile, pas seulement intellectuellement attrayante.
C'est une norme beaucoup plus difficile que beaucoup de récits de jetons ne le prennent en compte.
Pourtant, je ne peux pas me débarrasser de la sensation que la conversation sur l'infrastructure IA est coincée dans une phase antérieure.
Les gens se concentrent encore sur la construction de l'intelligence plus rapidement.
Mais peut-être que le prochain goulot d'étranglement n'est pas l'intelligence.
Peut-être que c'est la gestion des conséquences.
Parce que l'intelligence sans lignée accountable est bien pour le divertissement.
C'est beaucoup moins fin pour l'argent.
Et beaucoup moins fin pour les systèmes régulés.
Si ce changement se produit réellement, alors $OPEN pourrait ne pas être en concurrence dans la catégorie que la plupart des gens supposent.
Pas de calcul. Pas d'accès au modèle.
Quelque chose de plus discret.
Un marché pour réduire l'incertitude autour des décisions machines.
C'est une thèse moins glamour.
C'est exactement pourquoi cela peut avoir de l'importance.