

L'autre jour, alors que je rentrais chez moi en prenant l'autoroute depuis le campus, j'avais une discussion intense avec mon grand frère sur l'état actuel de la blockchain. On était en train de disséquer les tokens d'intelligence artificielle qui vont inonder le marché. Mon avis était clair et sceptique. Je lui ai dit, frère, clarifie un truc, chaque fois que je regarde un nouveau projet de crossover crypto, à la fin, c'est juste un emballage vide. Ils utilisent juste des buzzwords tape-à-l'œil, prétendent avoir de l'apprentissage automatique, mais derrière, il n'y a pas d'infrastructure de smart contract réelle. C'est frustrant de passer des heures à lire un whitepaper et de réaliser qu'ils n'ont même pas de produit vérifiable. Le monopole de données des grandes entreprises tech, ces projets ne l'effleurent même pas. Ils parlent de données décentralisées, mais au fond, leurs systèmes tournent encore sur des serveurs centralisés, ignorant le problème fondamental que les modèles d'IA sont entraînés dans une boîte noire.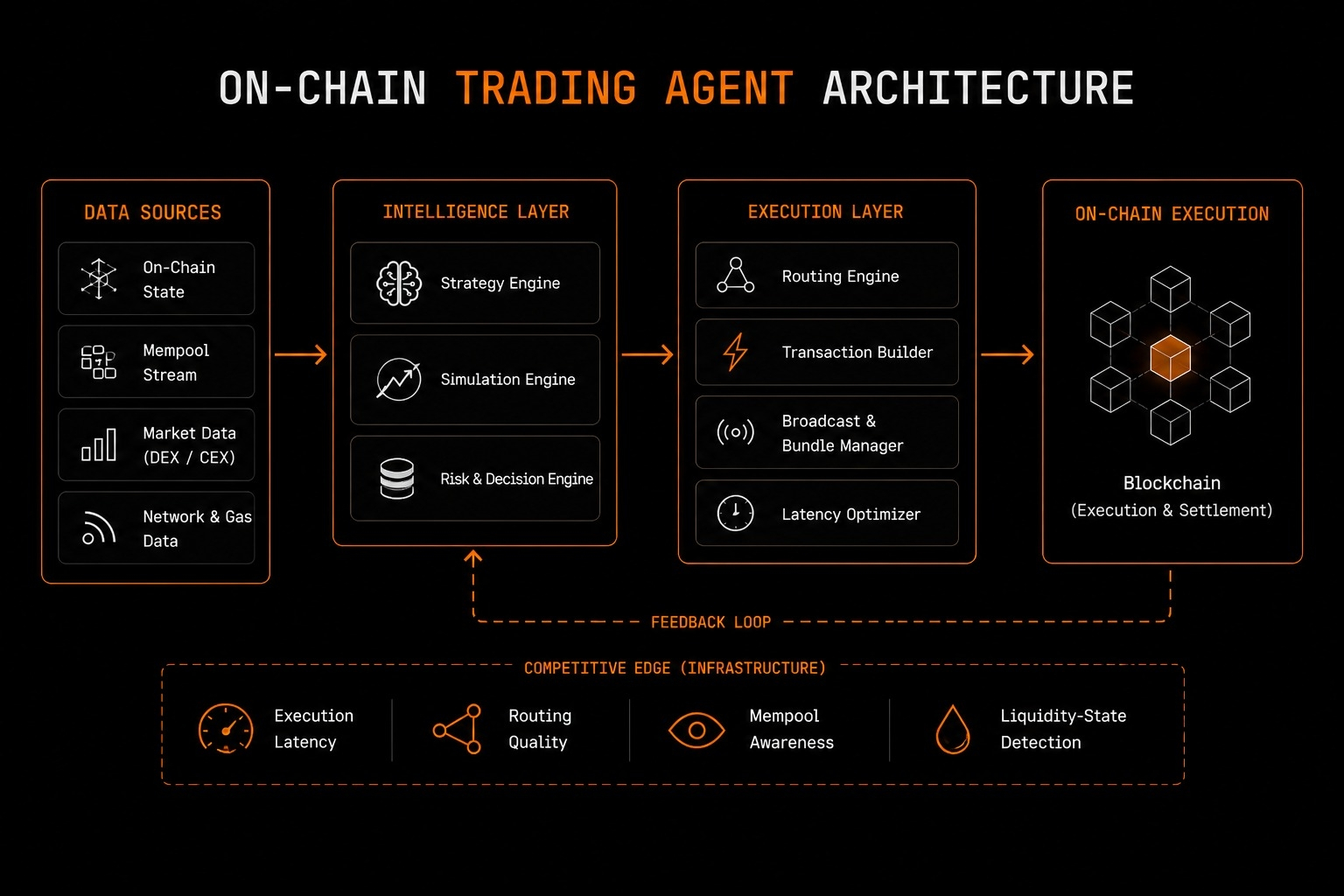
C'était justement ce doute qui m'a fait ignorer @OpenLedger au début. Je pensais que c'était juste un jeu spéculatif. Mais quand j'ai commencé à plonger dans leur documentation pour écrire une véritable évaluation précieuse, ma perspective a commencé à changer. Ce qui a attiré mon attention, ce n'était pas leur marketing, mais plutôt l'accent pratique sur la construction d'un pipeline de données vérifiable. Ces gens veulent vraiment résoudre le problème de monopole sur les données de base où les grandes corporations scrutent Internet, entraînent des modèles sur nos sorties et gardent tout le profit pour elles. #OpenLedger introduit une véritable économie de données d'IA décentralisée basée sur des principes d'IA collaborative, avec des mécaniques on-chain que vous pouvez tracer de manière transparente.
Quand nous$OPEN Quand on parle de problème ou de solution de token, leur approche est ancrée dans la manière dont le réseau de token fonctionne comme une véritable utilité. Au lieu d'être un actif spéculatif, $OPEN le système de preuve de contribution du token devient le moteur économique. Chaque fois que les utilisateurs fournissent des ensembles de données de haute qualité, leurs contributions sont enregistrées on-chain. Si par la suite, un modèle d'IA utilise ces données spécifiques pour une sortie, le système de validation de nœud décentralisé peut tracer cette utilisation jusqu'à la source originale et récompenser le créateur. Vous ne nourrissez plus les méga-corporations gratuitement. Ce réseau suit toute la lignée de l'information, assurant un flux d'information transparent depuis le téléchargement des données jusqu'à l'influence sur la sortie.
En analysant l'écosystème, j'ai prêté attention aux détails d'Octoclaw pour comprendre comment il a été ajouté et comment un utilisateur régulier peut l'utiliser. Octoclaw a été récemment lancé en tant qu'agent intelligent conçu pour l'automatisation des workflows en temps réel, et il se distingue des interfaces de conversation normales. Au lieu de simplement répondre à des questions de base, Octoclaw peut mener des recherches approfondies sur les données, générer des stratégies d'exécution et exécuter des tâches en interagissant avec des contrats intelligents dans des écosystèmes décentralisés. Si vous recevez un signal on-chain, vous pouvez configurer Octoclaw. Il comble efficacement le fossé où vous savez ce qu'il faut faire on-chain mais où le frottement de l'exécution le rend difficile, prouvant que l'infrastructure supporte un cas d'utilisation de token ouvert clair.
Rediriger cette valeur de formation en IA des méga-corporations centralisées vers les poches des véritables créateurs de données a un sens économique. Nous générons des insights précieux quotidiennement grâce à la recherche technique et à l'analyse. OpenLedger reverse ce flux de valeur, et c'est un changement fondamental qui compte vraiment. Les petits créateurs ont maintenant enfin un moyen de monétiser en toute sécurité des connaissances spécifiques. Ce modèle d'information transparent garantit que la récompense est basée sur leur véritable utilité.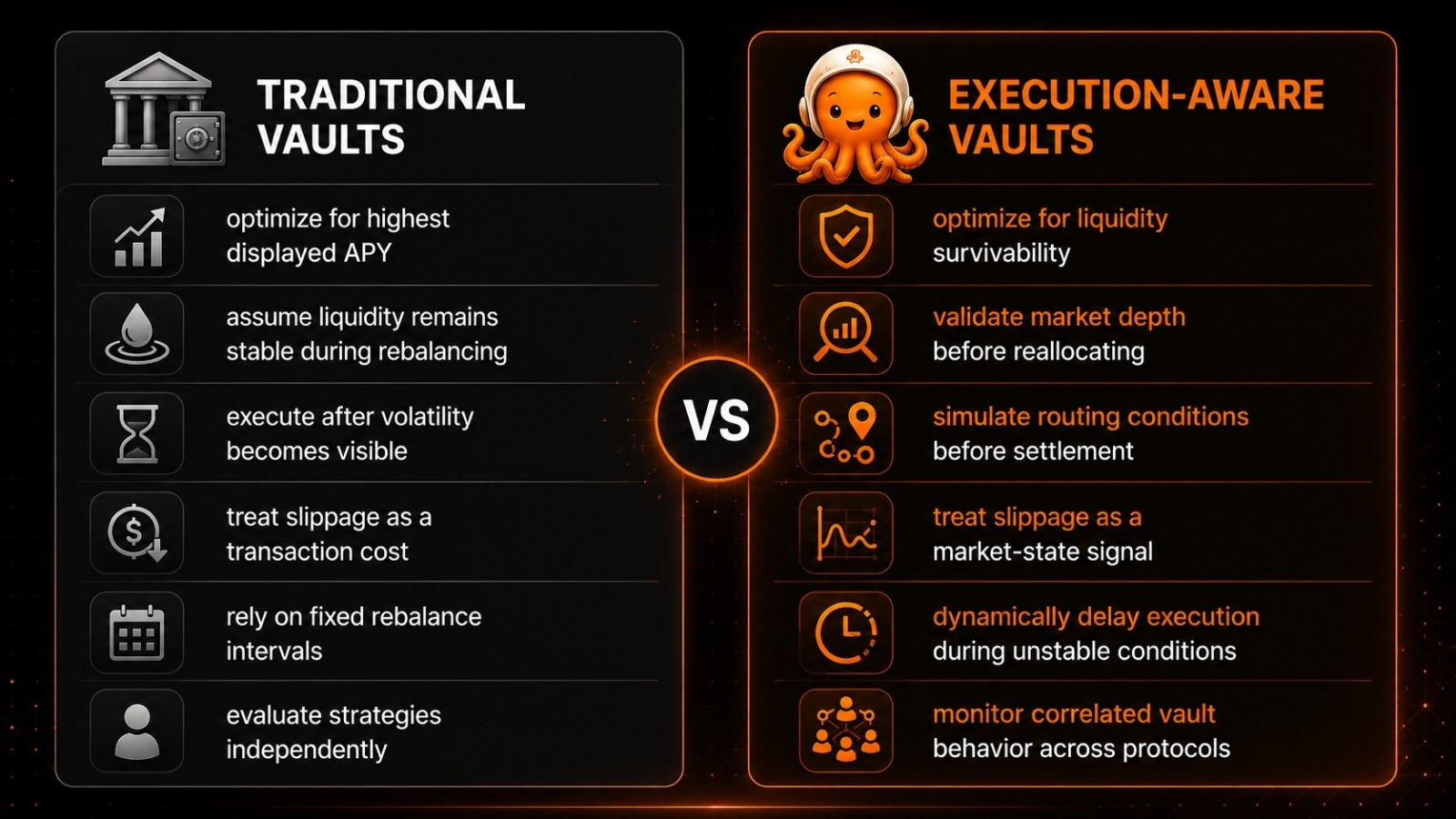
Mais je dois rester honnête sur les risques et les récompenses, car ce n'est pas de la magie. Équilibrer la qualité des données au niveau décentralisé est notoirement difficile, et cela pourrait devenir le plus grand goulet d'étranglement de leur vision. Il y a le risque de mauvais acteurs qui tenteront de manipuler le système. Ils vont délibérément spammer le réseau avec des données de mauvaise qualité juste pour extraire des récompenses de token. Si leur processus de validation de nœud décentralisé échoue à filtrer ces entrées de faible qualité, l'ensemble du dataset sera contaminé. Aucune entreprise d'IA ne paiera pour des données polluées, et la scalabilité et l'utilité du projet seront gravement compromises.
Dans les mois à venir, mon approche pratique sera uniquement d'observer comment les développeurs externes interagissent avec ce marché de données B2B inter-écosystèmes. La survie à long terme de cette infrastructure dépend directement de la demande d'IA d'entreprise, et non de la spéculation de détail. Le signal le plus clair pour moi sera de voir si des studios d'IA externes adoptent leur infrastructure décentralisée pour améliorer les modèles pendant une période prolongée. Le véritable test est de savoir si OpenLedger peut continuellement fournir une provenance de données propre et vérifiable et s'il peut filtrer le bruit du réseau de manière vraiment décentralisée. Je préfère voir ces choses se développer sur le deck plutôt que dans la production réelle.