

La plupart des gens évaluent encore l'infrastructure AI de la même manière que les traders crypto évaluaient autrefois les blockchains pendant les guerres de débit. inférence plus rapide. calcul moins cher. clusters plus grands. latence plus basse. la conversation semble sophistiquée jusqu'à ce que vous réalisiez que le cadre sous-jacent est encore douloureusement primitif. tout le monde mesure la puissance tout en presque personne ne mesurant la traçabilité économique.
c'est exactement ce point aveugle qui fait que OpenLedger attire encore mon attention.

plus j'étudie l'architecture, moins cela ressemble à une chaîne AI traditionnelle et plus cela ressemble à un réseau de règlement pour l'intelligence elle-même. pas un règlement dans le sens bancaire. quelque chose de plus étrange. règlement pour la contribution. règlement pour l'influence. règlement pour les empreintes économiques invisibles cachées dans les systèmes AI modernes.
parce qu'une fois que l'IA cesse d'être un jouet et commence à générer de la valeur d'entreprise à grande échelle, la question la plus difficile n'est plus de savoir si les modèles peuvent produire des résultats. La question plus difficile devient de savoir si quelqu'un peut prouver d'où proviennent réellement ces résultats.
cela semble philosophique jusqu'à ce que l'argent entre dans le système.
imaginez un agent IA légal formé à l'aide de cinq datanets différents. L'un contient des archives de jurisprudence. Un autre contient des mises à jour de conformité régionales. Un autre provient des flux de travail d'entreprises privées. Ensuite, un tiers affine le modèle à l'aide de Qlora dans la factory de modèles avant de le déployer via Openlora. Enfin, un agent autonome utilise cet ensemble pour générer des recommandations pour des clients dans plusieurs juridictions.
la sortie crée des revenus mesurables.
maintenant, le cauchemar comptable commence.
quel contributeur mérite une compensation. Quel ensemble de données a influencé le chemin de raisonnement. Quelle couche de fine-tuning a créé l'amélioration comportementale. Quel nœud d'inférence a traité la requête. Et surtout, quelqu'un peut-il vérifier ces affirmations sans faire confiance à un opérateur centralisé.
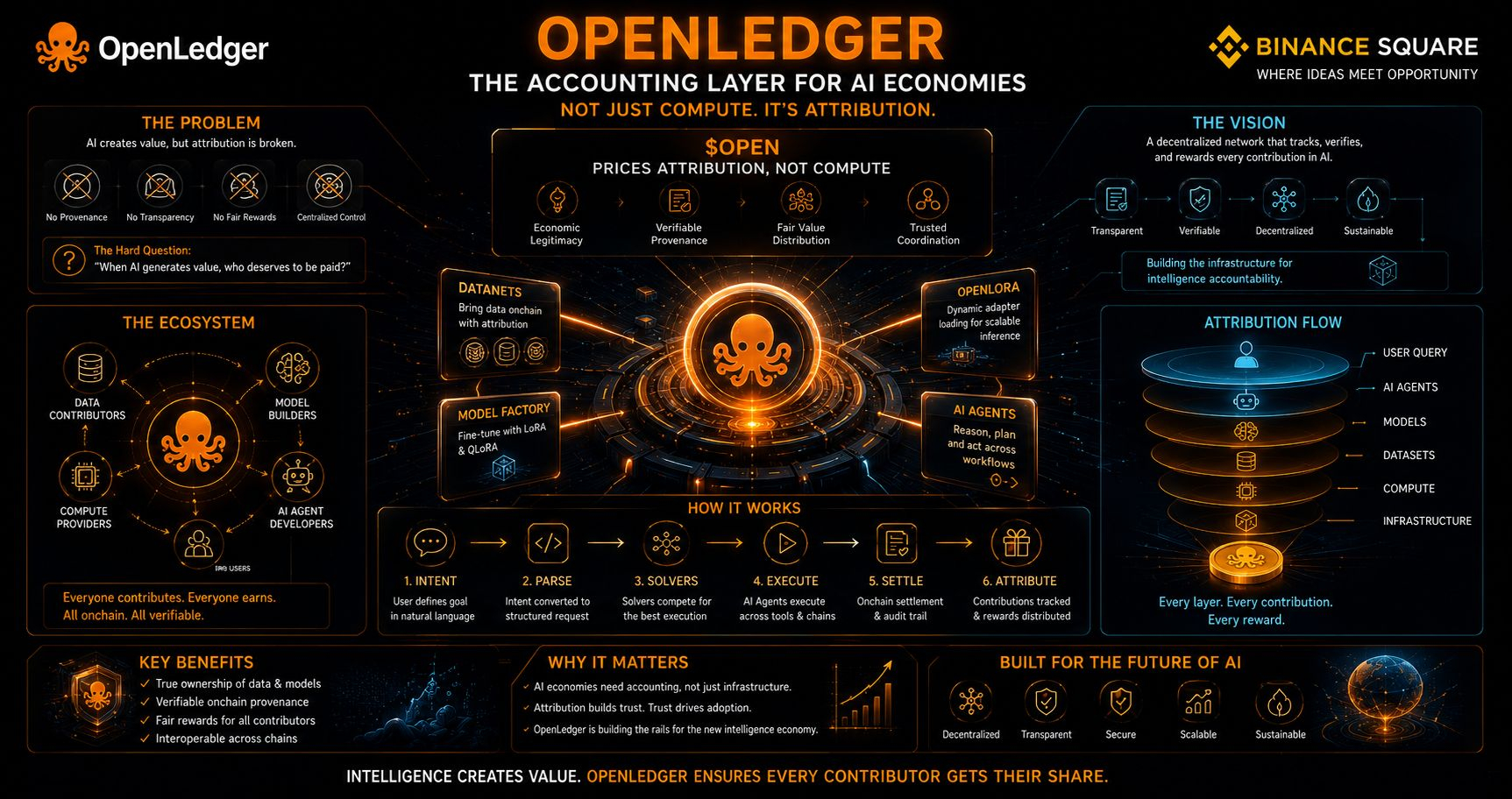
@OpenLedger est l'un des premiers projets que j'ai vus traiter ce problème comme une infrastructure au lieu d'un langage marketing.
le mécanisme clé est la preuve d'attribution. Au lieu de laisser les ensembles de données et les contributions de modèles disparaître dans une abstraction en boîte noire, le réseau enregistre la provenance directement sur la chaîne via les journaux d'attribution de Datanets, les métadonnées d'entraînement et le suivi des inférences. Chaque téléchargement, chaque événement de fine-tuning, chaque interaction d'inférence devient partie intégrante d'un graphe économique auditables.
cela change complètement la texture émotionnelle du développement de l'IA.
les données cessent de se comporter comme un carburant jetable et commencent à se comporter comme une propriété intellectuelle programmable.
la partie intéressante est comment la pile technique renforce cette philosophie de plusieurs directions simultanément. La factory de modèles supporte le fine-tuning Lora et Qlora, tandis qu'Openlora charge dynamiquement des adaptateurs uniquement lorsque les requêtes d'inférence les nécessitent, au lieu de forcer une allocation GPU permanente. L'attention flash, l'attention paginée et l'optimisation SGMV réduisent la pression mémoire suffisamment pour que des milliers de modèles spécialisés fonctionnent efficacement sur une infrastructure partagée.
normalement, cela semblerait juste être une histoire d'optimisation des coûts.
mais ici, la couche d'efficacité alimente directement l'économie d'attribution.
un déploiement moins cher signifie que des communautés plus petites peuvent se permettre une intelligence spécialisée. Des communautés plus petites générant une intelligence spécialisée signifient une propriété plus fragmentée. La propriété fragmentée augmente l'importance d'une attribution transparente parce que la création de valeur n'appartient plus à un seul laboratoire centralisé.
tout à coup, la logique des tokens change aussi.
je ne pense pas qu'Openledger devienne précieux simplement parce que les gens ont besoin d'accès computationnel. Les marchés du cloud ont déjà résolu la monétisation de base du calcul il y a des années. Ce qui semble plus important, c'est la possibilité qu'Openledger devienne une infrastructure de coordination pour la responsabilité de l'IA elle-même.
c'est un marché beaucoup plus difficile à modéliser.
les entreprises ne demandent pas seulement si les modèles fonctionnent. Elles demandent finalement si les sorties sont auditables. Les régulateurs demandent si la provenance de l'entraînement existe. Les contributeurs demandent si la compensation peut être vérifiée. Les constructeurs demandent si la collaboration peut se faire sans abandonner complètement la propriété.
la plupart des systèmes d'IA aujourd'hui répondent à ces questions avec une architecture 'fais-moi confiance, mec'.
Openledger essaie de répondre à ces questions avec une comptabilité cryptographique.
peut-être que cette vision réussit. Peut-être que la friction de coordination ralentit l'adoption. Peut-être que la modélisation d'attribution reste imparfaite pour toujours.
mais plus l'IA évolue, plus je suis convaincu que l'intelligence seule n'est pas le produit final.
la légitimité économique est.
et cela pourrait être la vraie chose qu'Openledger évalue silencieusement dans l'avenir de l'IA.
cette possibilité explique pourquoi l'écosystème continue d'attirer des chercheurs, des constructeurs et des contributeurs de données au lieu de traders spéculatifs. Les gens commencent à réaliser que la prochaine économie de l'IA pourrait ne pas appartenir à ceux qui possèdent les serveurs. Elle pourrait appartenir à ceux qui construisent les rails d'attribution de confiance sous les systèmes.
#OpenLedger $OPEN $ZEC
#MillenniumCutsIBITAndETHA #TrendingTopic