
La plupart des projets d'IA dans le Web3 semblent toujours coincés dans la même boucle.
Une nouvelle narration apparaît, tout le monde se précipite, les récompenses explosent pendant quelques semaines, puis l'excitation disparaît lentement car le produit lui-même ne devient jamais plus fort que le battage médiatique qui l'entoure.
J'ai vu cela se produire trop de fois, surtout dans l'IA. Chaque projet prétend construire "l'avenir", mais en réalité, la plupart dépendent encore des mêmes systèmes et infrastructures recyclés.
C'est honnêtement pourquoi j'ai regardé OpenLedger avec beaucoup de scepticisme au début.
Je pensais que "Modèles Spécialisés" n'était qu'un autre mot à la mode de l'IA Web3 conçu pour surfer sur la vague narrative. Mais après avoir passé du temps à lire sur l'architecture des Ensembles de Données et des Datanets d'OpenLedger, j'ai réalisé que le projet essaie de résoudre quelque chose de beaucoup plus profond que la visibilité ou la spéculation.
Elle essaie de résoudre la question de la propriété.
Et cela change complètement la conversation autour de l'IA décentralisée.
Une chose qui m'a toujours dérangé dans l'économie de l'IA d'aujourd'hui est à quel point les contributeurs deviennent invisibles. D'énormes modèles d'IA sont entraînés à l'aide de quantités massives de données créées par des humains, pourtant les personnes fournissant ces données savent rarement si leurs contributions ont même compté. La plupart du temps, elles ne partagent jamais la valeur créée par la suite non plus.
OpenLedger aborde cela différemment.
Au lieu de construire un autre modèle généralisé entraîné sur un bruit Internet sans fin, le réseau se concentre sur des Modèles Spécialisés alimentés par des ensembles de données organisés provenant de contributeurs décentralisés. Mais la vraie différence n'est pas seulement "les données de la communauté" — nous avons entendu cette phrase de nombreuses fois auparavant.
La partie importante, c'est l'attribution.
Je me souviens d'avoir été assis tard dans la nuit avec un chai en lisant leurs notes d'infrastructure, et j'ai fait une pause un instant parce que l'idée semble simple en surface, mais économiquement, ça change tout.
Un modèle d'IA financière peut s'entraîner spécifiquement sur des ensembles de données financières.
Un assistant de santé peut s'améliorer en utilisant des informations médicales ciblées.
Un modèle de développeur peut apprendre à partir de dépôts de code et de discussions techniques au lieu de désordre Internet non pertinent.
Ce niveau de spécialisation compte plus que la plupart des gens ne le réalisent.
La course à l'IA n'est plus seulement une question de qui possède le plus grand modèle. De plus en plus, elle devient une question de qui possède les données de la plus haute qualité.
Et c'est là qu'OpenLedger commence à devenir stratégiquement intéressant.
Leur système de Preuve d'Attribution tente de suivre comment les ensembles de données contribuent aux résultats des modèles afin que la valeur puisse revenir aux contributeurs au lieu de disparaître dans une boîte noire. Ce point m'a marqué parce que la plupart des systèmes d'IA aujourd'hui ne peuvent pas clairement expliquer d'où vient réellement leur intelligence une fois l'entraînement commencé.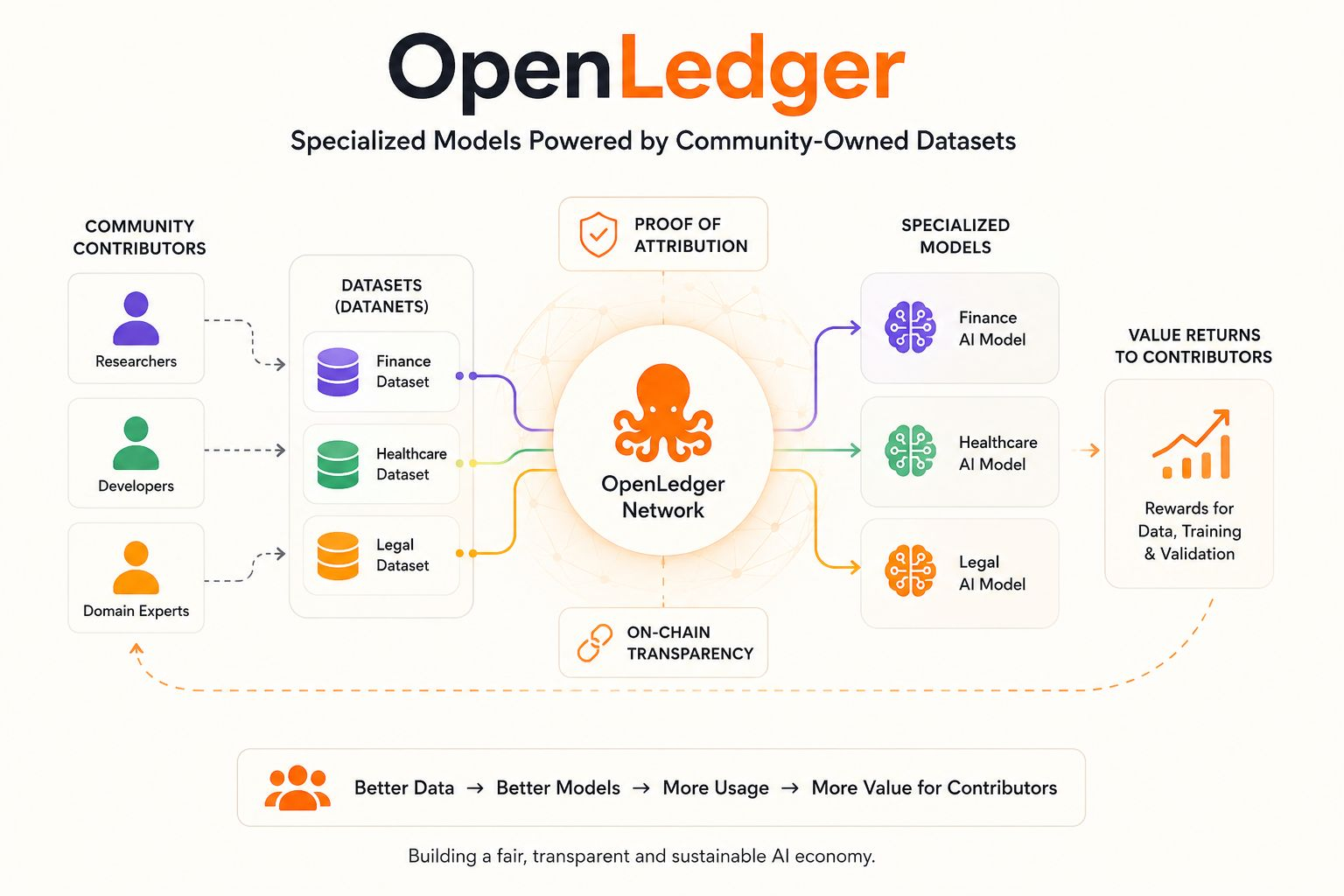
OpenLedger essaie d'intégrer la traçabilité économique directement dans l'infrastructure elle-même.
Cela crée une structure d'incitation beaucoup plus saine.
Parce qu'une fois que les contributeurs savent que leurs ensembles de données peuvent générer de la valeur en continu grâce à l'utilisation des modèles, l'état d'esprit passe de l'agriculture à court terme à une participation à long terme. Et honnêtement, le Web3 a désespérément besoin de plus de systèmes conçus autour de la rétention plutôt que de l'extraction.
Une autre chose qui m'a surpris, c'est à quel point leur réflexion sur l'infrastructure semble pratique par rapport à de nombreux récits d'IA qui circulent aujourd'hui.
OpenLedger ne parle pas seulement d'intelligence ou de modèles. Ils réfléchissent également à l'efficacité de déploiement, à l'inférence évolutive et aux économies de données réutilisables.
Ça sonne technique, mais ça compte beaucoup.
De nombreux projets d'IA se concentrent entièrement sur l'idée d'intelligence tout en ignorant la réalité économique derrière les coûts de calcul. Finalement, chaque réseau se heurte au même problème : si les coûts d'exploitation deviennent trop élevés, la durabilité disparaît peu importe à quel point la narration semble solide sur les réseaux sociaux.
OpenLedger semble conscient de ce défi dès le départ.
Maintenant, cela garantit-il le succès ?
Pas du tout.
Le risque d'exécution reste énorme. Construire une infrastructure d'IA décentralisée est déjà difficile. En construire une où l'attribution, les incitations, la scalabilité et l'adoption réelle des développeurs fonctionnent tous ensemble est un défi encore plus grand.
Et il y a une autre réalité que les gens ne peuvent pas ignorer.
La plupart des utilisateurs choisissent encore la commodité plutôt que la transparence. Les entreprises d'IA centralisées dominent déjà l'infrastructure, la liquidité et l'attention. OpenLedger entre sur un marché où la force technique seule ne suffit pas. Le plus grand défi est de changer le comportement des utilisateurs eux-mêmes.
Mais même avec tous ces risques, je reviens toujours à la même conclusion.
Ça ne ressemble pas à un autre récit de jeton IA à court terme.
On dirait plus une tentative de redéfinir comment l'intelligence elle-même est structurée économiquement dans le Web3.
Et peut-être que c'est pour ça que je continue à y prêter attention.
Pas à cause du battage médiatique.
Parce qu'en dessous de tout le bruit autour de l'IA en ce moment, la propriété pourrait devenir discrètement la couche la plus importante de toutes.